Statistics
This script computes a series of statistical values on the input raster. Some of the summarized statistics are the maximum, minumum, std and different types of means, e.g. the harmonic mean. These operations are of type Zonal, which means the reduce a values along some defined zone. In this case we are not giving explicit zones, which means the operations work in the whole raster. This script is simple but interesting because it presents opportunities for fusion, some fusion-preventing dependencies and scalar operations are better run by a scalar thread rather than in OpenCL.
from map import * ## "Parallel Map Algebra" package
dem = read('in_file_path')
N = prod(dem.datasize())
maxv = zmax(dem)
minv = zmin(dem)
rang = maxv - minv
mean = zsum(dem) / N
geom = zprod(dem) ** (1.0/N)
harm = N / zsum(1.0/dem)
quam = sqrt(zsum(dem**2)/N)
cubm = cbrt(zsum(dem**3)/N)
dev = (dem - mean) ** 2
var = zsum(dev) / N
vstd = sqrt(var)
norm = (dev - minv) / rang
nstd = sqrt(zsum(norm) / N)
print "max: ", value(maxv), "min: ", value(minv), "range: ", value(rang)
print "mean: ", value(mean), "quam: ", value(quam), "cubm: ", value(cubm)
print "vstd: ", value(vstd), "nstd: ", value(nstd)
print "geom: ", value(geom), "harm: ", value(harm)The actual source file for the statistics script can be found here.
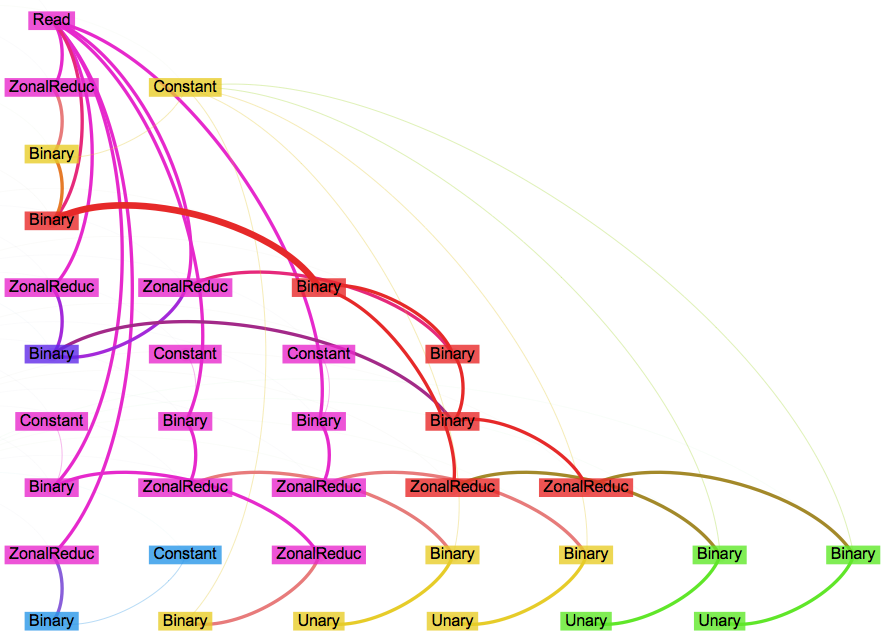
Below is the dependency graph showing six different groups of nodes (grouped by color). This organization differs from Hillshade, where all the nodes are seamlessly fused into one group. Moreover, only two groups presents two-dimensional operations (pink,red), while the other four groups work on scalar values. As a result those four scalar groups don't really need any OpenCL code, since they don't present data parallelism.
Here is the kernel code for the first non-scalar group. The reductions are performed completely in GPU memory, thus the use of atomic operations to finally reduce the values from shared memory to global memory.
kernel void krn2477221412142453674
(
global float *IN_34, float IN_34v, uchar IN_34f,
float IN_44v,
int IN_48v,
int IN_53v,
global float *OUT_35, int idx_35,
global float *OUT_36, int idx_36,
global float *OUT_38, int idx_38,
global float *OUT_41, int idx_41,
global float *OUT_46, int idx_46,
global float *OUT_50, int idx_50,
global float *OUT_55, int idx_55,
const int BS0,
const int BS1,
const int BC0,
const int BC1,
const int GS0,
const int GS1,
const int GN0,
const int GN1
)
{
float F32_34, F32_44, F32_35, F32_36, F32_38, F32_41, F32_45, F32_46, F32_49, F32_50, F32_54, F32_55;
int S32_48, S32_53;
local float F32S_35[256];
local float F32S_36[256];
local float F32S_38[256];
local float F32S_41[256];
local float F32S_46[256];
local float F32S_50[256];
local float F32S_55[256];
int gc0 = get_local_id(0);
int gc1 = get_local_id(1);
int GC0 = get_group_id(0);
int GC1 = get_group_id(1);
int bc0 = get_global_id(0);
int bc1 = get_global_id(1);
// Previous to ZONAL core
if (bc0 < BS0 && bc1 < BS1)
{
F32_34 = LOAD_L_F32(IN_34);
F32_44 = IN_44v;
S32_48 = IN_48v;
S32_53 = IN_53v;
F32_45 = F32_44 / F32_34;
F32_49 = pow(F32_34,S32_48);
F32_54 = pow(F32_34,S32_53);
F32S_35[(gc1)*GS0+gc0] = F32_34;
F32S_36[(gc1)*GS0+gc0] = F32_34;
F32S_38[(gc1)*GS0+gc0] = F32_34;
F32S_41[(gc1)*GS0+gc0] = F32_34;
F32S_46[(gc1)*GS0+gc0] = F32_45;
F32S_50[(gc1)*GS0+gc0] = F32_49;
F32S_55[(gc1)*GS0+gc0] = F32_54;
}
else
{
F32S_35[(gc1)*GS0+gc0] = -INFINITY;
F32S_36[(gc1)*GS0+gc0] = INFINITY;
F32S_38[(gc1)*GS0+gc0] = 0;
F32S_41[(gc1)*GS0+gc0] = 1;
F32S_46[(gc1)*GS0+gc0] = 0;
F32S_50[(gc1)*GS0+gc0] = 0;
F32S_55[(gc1)*GS0+gc0] = 0;
}
// Zonal core
for (int i=GS0*GS1/2; i>0; i/=2) {
barrier(CLK_LOCAL_MEM_FENCE);
if ((gc1)*GS0+gc0 < i)
{
F32S_35[(gc1)*GS0+gc0] = max(F32S_35[(gc1)*GS0+gc0], F32S_35[(gc1)*GS0+gc0 + i]);
F32S_36[(gc1)*GS0+gc0] = min(F32S_36[(gc1)*GS0+gc0], F32S_36[(gc1)*GS0+gc0 + i]);
F32S_38[(gc1)*GS0+gc0] = F32S_38[(gc1)*GS0+gc0] + F32S_38[(gc1)*GS0+gc0 + i];
F32S_41[(gc1)*GS0+gc0] = F32S_41[(gc1)*GS0+gc0] * F32S_41[(gc1)*GS0+gc0 + i];
F32S_46[(gc1)*GS0+gc0] = F32S_46[(gc1)*GS0+gc0] + F32S_46[(gc1)*GS0+gc0 + i];
F32S_50[(gc1)*GS0+gc0] = F32S_50[(gc1)*GS0+gc0] + F32S_50[(gc1)*GS0+gc0 + i];
F32S_55[(gc1)*GS0+gc0] = F32S_55[(gc1)*GS0+gc0] + F32S_55[(gc1)*GS0+gc0 + i];
}
}
if (gc0 == 0 && gc1 == 0)
{
atomicMAX( (global char*)OUT_35+idx_35 , F32S_35[(gc1)*GS0+gc0]);
atomicMIN( (global char*)OUT_36+idx_36 , F32S_36[(gc1)*GS0+gc0]);
atomicSUM( (global char*)OUT_38+idx_38 , F32S_38[(gc1)*GS0+gc0]);
atomicPROD( (global char*)OUT_41+idx_41 , F32S_41[(gc1)*GS0+gc0]);
atomicSUM( (global char*)OUT_46+idx_46 , F32S_46[(gc1)*GS0+gc0]);
atomicSUM( (global char*)OUT_50+idx_50 , F32S_50[(gc1)*GS0+gc0]);
atomicSUM( (global char*)OUT_55+idx_55 , F32S_55[(gc1)*GS0+gc0]);
}
// Posterior to ZONAL core
if (bc0 < BS0 && bc1 < BS1)
{
}
}This is a dump of the assembly code generated by the Intel OpenCL compiler for a Skylake i7-6700 CPU. See how the reduction instructions are vectorized (i.e. vmaxps, vminps, vaddps, vmulps) and are fused together into the same basic block.
...
vpcmpgtd 128(%rcx), %ymm0, %ymm2
vptest %ymm2, %ymm2
je .LBB1_23
movq 168(%rcx), %rax
vmovups (%rax), %ymm3
movl 160(%rcx), %esi
addl %r14d, %esi
movslq %esi, %rsi
--> vmaxps 512(%rbx,%rsi,4), %ymm3, %ymm3
vptest %ymm1, %ymm2
jae .LBB1_22
vmovups %ymm3, (%rax)
movq 176(%rcx), %rax
vmovups (%rax), %ymm2
--> vminps 1536(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
movq 184(%rcx), %rax
vmovups (%rax), %ymm2
--> vaddps 2560(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
movq 192(%rcx), %rax
vmovups (%rax), %ymm2
--> vmulps 3584(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
movq 200(%rcx), %rax
vmovups (%rax), %ymm2
--> vaddps 4608(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
movq 208(%rcx), %rax
vmovups (%rax), %ymm2
--> vaddps 5632(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
movq 216(%rcx), %rax
vmovups (%rax), %ymm2
--> vaddps 6656(%rbx,%rsi,4), %ymm2, %ymm2
vmovups %ymm2, (%rax)
jmp .LBB1_23
...