OldSummerOfCodeIdeas
This page collects old, no longer used Summer of Code ideas. These may have already been done in previous years. Reading through these could be useful for getting some context on the history of mlpack and could also help spark ideas for new projects.
See also the up-to-date SummerOfCodeIdeas page.
- Essential Deep Learning Modules
- NeuroEvolution of Augmenting Topologies
- Particle swarm optimization
- mlpack-TensorFlow translator
- String processing utilities
- Robotic Arm
- Quantum Gaussian Mixture Models
- Fixes to MVU and low-rank semidefinite programs
- Profiling for further optimization
- Variational Autoencoders
- LMNN with LRSDP implementation
- Alternatives to neighborhood-based collaborative filtering
- Low rank/sparse optimization using Frank-Wolfe
- Better benchmarking
- Cross-validation and hyper-parameter tuning infrastructure
- Fast k-centers Algorithm & Implementation
- Parallel stochastic optimization methods
- Augmented Recurrent Neural Networks
- Build testing with Docker and VMs
- Implement tree types
- Automatic bindings
- Approximate Nearest Neighbor Search
- Decision trees
- Neuroevolution algorithms
- Dataset and experimentation tools
- We need to go deeper - GoogLeNet
- Refinement of MATLAB bindings
- Python bindings and R bindings for mlpack
- Automatic benchmarking of mlpack methods
- Packaging in Debian (and Ubuntu)
- mlpack on RPi and other resource-constrained devices
- Example Zoo, Embedded Edition
- Automatic bindings to new languages
- Profiling for parallelization
- Build System (CMake) Modernization
- Visualization Tool
- Better layer stacking for ANN
- Improvisation and Implementation of ANN Modules
- Ready to use Models in mlpack
description: In the past years Deep Learning has markedly attracted a lot of attention in the Machine Learning community for its ability to learn features that allow high performance in a variety of tasks. For example, DeepMind has shown that neural networks can learn to play Atari games just by observing large amounts of images, without being trained explicitly on how to play games. This project involves implementing essential building blocks of deep learning algorithms based on the existing neural network codebase. A good project will select some of the architectures and implement them (with tests and documentation) over the course of the summer. This could include Deep Belief Networks (DBN), Radial Basis Function Networks (RBFN) and Generative Adversarial Networks (GAN). The architecture should be designed to build a foundation to integrating many more models including support for other state-of-the-art deep learning techniques. Note this project aims to revisit some of the traditional models from a more modern perspective e.g.:
- RBFN: Back to the Future: Radial Basis Function Networks Revisited, Learning methods for radial basis function networks
- GAN: Improved Training of Wasserstein GANs, PacGAN
deliverable: Implemented deep learning modules and proof (via tests) that the code works.
difficulty: 6/10
necessary knowledge: a working knowledge of what neural networks are, willingness to dive into some literature on the topic, basic C++
recommendations for preparing an application: Being familiar with the mlpack codebase, especially with existing neural network code is the first step if you wish to take up this task. We suggest that you build mlpack on your system and explore the functionalities. Take a look at the different layers and basic network structures. When you prepare your application, provide some comments/ideas/tradeoffs/considerations about your decision process, when choosing the models you want to implement over the summer.
relevant tickets: #1207, #1437, #1477, #1558
references: Deep learning reading list, Deep learning bibliography
potential mentor(s): Marcus Edel, Mikhail Lozhnikov, Shikhar Jaiswal, Saksham Bansal
Neuroevolution is a form of reinforcement learning, meaning that incoming data is raw and not marked or labeled. Instead, specific actions are rewarded or discouraged.


Mario Kart 64 by Nick Nelson and MarI/O by Seth Bling
NeuroEvolution of Augmenting Topologies (NEAT) can evolve networks of unbounded complexity from a minimal starting point, by searching the search space of simple networks and then looks at increasingly complex networks, which is called complexification [Stanley].
There are many use cases for neuroevolution; NEAT has been used in many fields, from physics calculations to game development [Miikkulainen]. Researchers at Fermilab used NEAT to compute the most accurate current measurement of the mass of the top quark at the Tevatron Collider. On the other end of the spectrum, NEAT was used in the MarI/O project written by Seth Bling, who was able to complete the first level of Super Mario World using NEAT [Bling].
NEAT must be implemented according to mlpack's optimization interface so that the method can work with different functions.
difficulty: 8/10
deliverable: Implemented NeuroEvolution of Augmenting Topologies (NEAT) and proof (via tests) that the algortihms works on different test functions.
necessary knowledge: a working knowledge of what neural networks are, willingness to dive into some literature on the topic, basic C++
recommendations for preparing an application: To be able to work on this you should be familiar with the source code of mlpack and mlpack's optimization framewwork ensmallen. We suggest that everyone who wishes to apply for this idea, try to compile the source code and explore the source code.
relevant tickets: none are open at this time
references: Evolving Neural Networks through Augmenting Topologies, ensmallen: a flexible C++ library for efficient function optimization
potential mentor(s): Marcus Edel
Particle swarm optimization (PSO) is a population-based stochastic optimization technique developed by Eberhart and Kennedy in 1995, inspired by social behavior of bird flocking or fish schooling;

Walter Baxter - A murmuration of starlings at Gretna.
In PSO, the potential solutions, called particles, fly through the problem space by following the current optimum particles to find a solution. Several variants of PSO have been proposed up to date e.g.
-
global best (gbest) PSO: uses a star neighborhood topology, where each particle has the entire swarm as its neighborhood (all particles are attracted to one global best position).
-
local best (lbest) PSO: uses a ring topology, where each particle’s neighborhood consists of itself and its immediate two neighbors (each particle is attracted to a different neighborhood position).
In recent years, Particle Swarm Optimization (PSO) methods have gained popularity in solving single objective but solving constrained optimization problems using PSO has been attempted in past but arguably stays as one of the challenging issues. For unconstrained problems we have something like this:
class ObjectiveFunction
{
// Evaluates the actual optimization problem.
double Evaluate(...)
}
ObjectiveFunction f;
Optimizer optimizer(....);
optimizer.Optimize(f, f.GetInitialPoint());This idea takes a closer look at constrained optimization problems that are encountered in numerous applications (using PSO).
So this project is divided into two parts: First implement one or two unconstrained methods and afterwards takes a look at one or two constrained methods. Note mlpack has already an optimization infrastructure for handling unconstrained problems, However, there is no infrastructure to deal with constrained problems. That is a detail that will need to be worked out in the proposal. For constrained PSO, we wish to pass a number of constraints, I can imagine an API something like this:
class ConstrainedFunction
{
// Evaluates the actual optimization problem.
double Evaluate(...) {}
// Returns all equality constraints of the given problem.
// Maybe it makes sense to express the constraineds in a matrix form or
// perhaps we can use C++11 lambda functions, maybe a combination of both.
void EqualityConstraint(...) {}
}Note that this is just an idea---there are many details left to be figured out.
difficulty: 7/10
deliverable: working PSO optimizer for unconstrained and contrained problems.
necessary knowledge: basic data science concepts, good familiarity with C++ and template metaprogramming (since that will probably be necessary), familiarity with mlpack optimizer API (see https://github.com/mlpack/ensmallen/tree/master/include/ensmallen_bits/problems)
relevant tickets: none are open at this time
potential mentor(s): Marcus Edel
recommendations for preparing an application: This project can't really be designed on-the-fly, so a good proposal will have already gone through the existing codebase and identified what parts of the API will need to change (if any).
mlpack has a neural network module in src/mlpack/methods/ann/, which is made up of roughly the same components as all of the other toolkits, like TensorFlow, Keras, MXNet, PyTorch, DyNet, and others. When each of these libraries save neural networks, they are just saving the weights and the structure of the network. So, it should be possible to take a model trained with mlpack and evaluate it with TensorFlow, or take a model trained with PyTorch, and evaluate it with mlpack (or any other combination).
The goal of this project would be to create a "translation layer" between mlpack and other libraries, so that someone could transform mlpack models into TensorFlow models or vice versa. TensorFlow is not the only possible target---other good ones could include Keras, PyTorch, or MXNet. (Or even others!)
Since this code is likely to have code specific to the other libraries, we should avoid putting it in the main mlpack repository and so instead this will involve the creation of an entirely new repository for the "translator". When it's ready, perhaps it could be used something like this:
$ python train_model_with_tensorflow.py --model-output-file tensorflow_model.h5
$ mlpack_converter -f TensorFlow -t mlpack -i tensorflow_model.h5 -o mlpack_model.bin
$ mlpack_nn -i mlpack_model.bin -T test_points.csv -p output_predictions.csv -v
Of course, that's just a basic idea. Maybe what you are thinking is a little different than that, and that's okay! In fact, maybe an idea here would be to look into the ONNX project and see how we can interface with it with mlpack:
difficulty: 6/10
deliverable: a repository containing a code that compiles to a program that translates to and from a target language (or multiple target languages), including tests to ensure that everything is working right
necessary knowledge: how to use mlpack's neural network code, how to use the target library's code, how to serialize models in mlpack, the representations of layers in the target library
recommendations for preparing an application: You'll need to be an expert on how mlpack neural networks are stored on disk and in memory, so you should familiarize yourself with that code. Whatever library you want to translate from may represent neural networks differently---for instance, mlpack puts activations as separate layers, whereas Keras may include those in a layer. So you will need to know how basic layers are represented, since you may need to have some "translation" between the two architectures. When you apply, be sure to specify the types of models that you'll be able to translate between, what you'll do if you encounter a layer you don't know about, and the exact "translations" between types of layers. It'll be really important to test this translator too, so be sure to put some thought into your testing strategy. Whatever library we are translating to may change over time, so ideally if the representation of their models changes, we're going to want to be sure that our tests break if our code is not adapted accordingly.
potential mentor(s): Ryan Curtin, Atharva Khandait
relevant issue(s): #1254 isn't done yet, and would be a great place to get started, since having a command-line program that runs neural networks for mlpack would be really helpful for the project.
description: mlpack and many other machine learning libraries are built upon a core of LAPACK- and BLAS-like algorithms that expect numeric data (specifically, single or double precision numeric data). But much of today's interesting data is in other formats, such as dates or strings. Some machine learning libraries handle this by writing generic algorithms that can also support types like strings; but this can cause huge runtime penalties. Instead it is better to provide some utilities that can convert string datatypes (or other datatypes) to the numeric datatypes required by the algorithms implemented in mlpack.
For the sake of simplicity, let's assume that we have some string "hello world hello everyone". Typically a user may want to encode this in many different ways. Below are two simple possibilities.
-
dictionary encoding: here we simply assign a word (or a character) to a numeric index and treat the dataset as categorical. So our example string "hello world hello everyone" would map to [0 1 0 2] where 0 = "hello", 1 = "world", and 2 = "everyone" if we were encoding words.
-
one-hot dictionary encoding: here, we encode each word as a k-dimensional vector where only one dimension has a nonzero value, and k is the number of words in the dictionary. So our example string "hello world hello everyone" would map to
[[1 0 1 0]
[0 1 0 0]
[0 0 0 1]]
where the first row is 1 if the word is "hello" and 0 otherwise, the second row is 1 if the word is "world" and 0 otherwise, and the third row is 1 if the world is "everyone" and 0 otherwise.
Other useful encodings might be TF-IDF or related techniques.
We want users to be able to convert seamlessly between these representations, in different languages. Therefore, we might imagine some functionality like the following:
class DictionaryEncoding
{
public:
// ...
/**
* Use dictionary encoding to fill the 'output' matrix with numeric data.
*
* ...
*/
void Encode(const std::vector<std::string>& strings,
std::map<size_t, std::string>& mappings,
arma::Mat<eT>& output);
};
This has some similarity to the NormalizeLabels() function found in
src/mlpack/core/data/normalize_labels.hpp, but takes the idea somewhat further
in that it makes the encoding and decoding process classes of their own.
On top of this, this could be integrated with the preprocessing utilities to provide a command-line program and Python binding that can convert a dataset of labels to a numeric dataset that can then be used with mlpack algorithms (or other algorithms). Below is a demo of what we might expect a user to do when they interact with mlpack's tools.
$ echo "Let's do nearest neighbor search on a dataset of sentences."
$ head -4 sentences.csv
A tetrad is a set of four notes in music theory.
Notable people with the surname include:
Gunspinning is a western art such as trick roping.
The play is a tragicomedy about a small rural town in Ireland.
$ mlpack_preprocess_encode -i sentences.csv -o sentences-numeric.csv -a "tf-idf" -e encoding.bin --strip-nonalnum --lowercase -v
[INFO ] Loading 'sentences.csv' as string data... X columns.
[INFO ] 1533 different words in the dataset.
[INFO ] Output one-hot encoded matrix is of size 1533 x X.
[INFO ] Saving output to 'sentences-numeric.csv'...
[INFO ] Saving output model to 'encoding.bin'...
$ mlpack_knn -r sentences-numeric.csv -k 1 -n neighbors.csv
Or they might want to use Python:
>>> print("Let's do nearest neighbor search on a dataset of sentences.")
Let's do nearest neighbor search on a dataset of sentences.
>>> print(sentences[0:4])
['A tetrad is a set of four notes in music theory.', 'Notable people with the surname include:', 'Gunspinning is a western art such as trick roping.', 'The play is a tragicomedy about a small rural town in Ireland']
>>> from mlpack import preprocess_encode, knn
>>> encoding = preprocess_encode(input=sentences, algorithm="tf-idf", strip-nonalnum=True, lowercase=True, verbose=True)
[INFO ] Input string data 'sentences' as string data contains 1000 columns.
[INFO ] 1533 different words in the dataset.
[INFO ] Output one-hot encoded matrix is of size 1533 x X.
[INFO ] Saving output to 'sentences-numeric.csv'...
[INFO ] Saving output model to 'encoding.bin'...
>>> knn_results = knn(reference=encoding['output'], k=1)
recommendations for preparing an application: The key to a successful project here is first defining the API that will be provided to the user. So in your application, it should be completely clear how the user will input their strings, how they will be converted to numeric values, and then how the resulting numeric values can be converted back to strings. It would be a good idea to make sure that your design is flexible enough to allow other conversion strategies, as well as handling data with other formats (graph data, for instance).
difficulty: 5/10
deliverable: Implemented design and algorithms, fully tested and ready for end users.
necessary knowledge: a working knowledge of data science and typical data processing steps, some knowledge of the mlpack automatic bindings system, C++ knowledge, and familiarity with Armadillo and string processing in C++.
potential mentor(s): Ryan Curtin
You are likely pretty good at picking things up. That’s really great. Part of the reason that you’re pretty good at picking things up is that when you were young, you spent a lot of time trying to pick things up and learning from your experiences. For the industrial task, say, sorting objects we don't want to wait through the equivalent of an entire robotic childhood, we want robots to operate in unstructured environments while learning many tasks on the fly, either by themselves or with the assistance of a human teacher.

This project takes up on the idea and explores different approaches towards teaching manipulation tasks to robots by applying (already implemented) learning methods. To show the learning process, we can provide access to a standard robot arm that can be used to demonstrate your work.
The idea behind this project would be, to use mlpack for various robotic manipulation tasks. The completed project would include an implementation of a simulator based on the existing robot arm, plus and that's the real focus of the project; implementing a pipeline (with tests and documentation) that uses different mlpack methods to solve the chosen task over the course of the summer. For this project, it would be up to you to observe the current mlpack API and methods, devise a design for the pipeline, and then implement everything. One idea would be to implement the simulator using processing, use OpenCV for the image processing and at the end mlpack's reinforcement framework for the model optimization. Note that this is just an idea---there are many details left to be figured out.
difficulty: 8/10
deliverable: working simulator and pipeline
necessary knowledge: basic data science concepts, good familiarity with C++, Python and template metaprogramming (since that will probably be necessary), familiarity with mlpack methods API (see src/mlpack/methods/*/)
relevant tickets: none are open at this time
potential mentor(s): Marcus Edel
recommendations for preparing an application: To be able to work on this you should be familiar with the source code of mlpack. We suggest that everyone who likes to apply for this idea, try to compile and explore the source code, especially the neural network and reinforcement code.
(No quantum computer or simulator Required!) Gaussian Mixture Models, or GMMs, are used widely across many domains of machine learning. In classical GMM, the data distribution is thought of to be a mixture of many independent gaussian distributions. In this project, we will tackle the word 'independent' and see if we can gain some advantage in modelling. In classical GMMs, probability of point A belonging to cluster C1, P(A|C1) does not affect P(A|C2), but instead while training EM will take this into consideration while maximizing the likelihood of the data. But what if we make P(A|C1) depend on P(A|C2)? Do we get more expressive power? Or is it just another way of expressing the same problem? A very unique solution comes up through quantum mechanics, more specifically wave functions. This paper explains the idea in details. In short, we will be modelling, each cluster as a wave, squaring of which will produce the distribution comparable to classical case of GMM. Rather than mixing the distribution we will be mixing the underlying wave functions. The data distribution will be the square of this mixed wave functions. This will allow the data distribution to take multitude of forms as mixing of waves will form interference patterns based on the phase angle between these waves. Although, optimizing such a case for multi cluster is not tractable yet, the case with 2 cluster could be optimized with EM algorithm as the paper explains.
One obvious advantage that I see is wider phase angle between cluster will cancel out the waves and may zero probability regions, I cannot imagine any situation where this can be produced by classical model. Such zero probability regions will be useful in many models, especially latent space modelling. The project will first concentrate on implementing QGMM for the case of 2 classes and go on to compare QGMM with classical GMM on various fronts -
- Sample efficiency - how fast it trains
- Accuracy - how better it models the data
- Edge cases - What can QGMM model that GMM cannot, and vice versa With all this information we will finally decide if any extra expressive power is attained by QGMM. And with some luck, we should be able to solidify this idea over the summer.
difficulty: 8/10
necessary knowledge: Basic math involved in GMM and EM. Basic interest in quantum physics. No special quantum physics knowledge required expect for the wave function described aptly in QGMM paper.
relevant tickets: None so far
potential mentor(s): Sumedh Ghaisas
description: This project is not for the faint of heart. For some time now, MVU (maximum variance unfolding), a dimensionality reduction technique, has not been converging even on simple datasets. mlpack's implementation of MVU uses LRSDP (low-rank semidefinite programs); there is not another existing implementation of MVU+LRSDP. Many tears will be shed trying to debug this. A good approach will probably be to compare mlpack MVU results on exceedingly simple problems with other MVU implementation results. The final outcome of this project may not even be a successful converging algorithm but instead more information on what is going wrong.
Here is a good list of papers to read or at least be familiar with:
- Basic SDP knowledge:
- The LRSDP algorithm:
- Some papers about MVU+LRSDP:
- http://fodava.gatech.edu/files/reports/FODAVA-09-10.pdf
- http://ieeexplore.ieee.org/abstract/document/4785894/ (sorry I don't have the PDF)
deliverable: working MVU implementation, or, further details and information on the problem
difficulty: 10/10
necessary knowledge: understanding of convexity and duality, knowledge of semidefinite programs, incredible determination and perseverance
potential mentor(s): Ryan Curtin
why not this year? I don't think it's feasible to approach and solve this problem in a summer.
description: mlpack could run even faster if it used profiling information during compilation. This entails adding extra build steps to the build process: first, to run a subset of mlpack programs with profiling information, and second, to rebuild mlpack using that profiling information. The difficulty here is choosing datasets which reflect general characteristics of the datasets which users will run mlpack methods with. If an unusual dataset is chosen, then mlpack will be compiled to run very quickly on that type of dataset -- but it will not run as well on other datasets. Another issue here is that the profiling process should not take extremely long (that is, longer than an hour or so), so we cannot choose a huge variety of large datasets.
deliverable: a 'make profile' build option which performs the profiling as described above
difficulty: 6/10
necessary knowledge: some machine learning familiarity, some CMake scripting
relevant tickets: #48
potential mentor(s): Ryan Curtin
why not this year? I think this is not enough work for an entire summer.
Variational Autoencoders(VAE) are widely used in unsupervised learning of complicated distributions. The more classical generative models depend upon sampling techniques such as MCMC. These sampling techniques are unable to scale to high dimensional spaces, for example distribution over set of images. Due to this reason, VAEs get rid of sampling by introducing gradient based optimization.
This project involves implementing the basic framework of VAE as described in this paper. For validity, implementation should reproduce the results shown in the same paper. The paper shows experiments on MNIST dataset and uses fully connected networks for modelling. The completed project should also test the de-noising ability of VAEs shown in this paper. This task involves adding noise to the data and use the same VAE network to reconstruct the original image.

The above image shows the samples generated by VAEs after training on MNIST dataset. The images correspond to different latent space used while training VAE, 2D 5, 2D 10, 2D 15, respectively.
You are also encouraged to add more functionality to the VAE implementation. Some suggestions might be -
-
Conditional Modelling: Use the same VAE network to reconstruct the whole MNIST digit by providing half of the digit. Refer to this paper
-
Regularization: Add functionality for regularizing the network. Refer to paper
-
Beta VAE: Beta VAEs are shown to generate better reconstruction loss. Beta VAE only differ in their loss function from pure VAEs. Refer to this paper
You can also suggest your own ideas.
difficulty: 8/10
deliverable: Basic VAE framework with rigorous tests, able to reproduce results shown in the paper
necessary knowledge: a good knowledge of C++ and Armadillo, fair understanding of generative models
recommendations for preparing an application: You should get familiar with the ANN module of mlpack. Spend some time reading this paper. This paper is a tutorial on VAE and explains the idea in depth. By understanding the framework beforehand we can concentrate more on implementation issues and testing.
potential mentor(s): Sumedh Ghaisas
why not this year? Atharva Khandait completed this as his GSoC 2018 project.
description: mlpack has a working LRSDP (low-rank semidefinite program) implementation, which gives faster solutions to SDPs. This could give good speedups for existing SDP-based machine learning methods, such as LMNN (large margin nearest neighbor). This project should only entail the expression of LMNN as a low-rank SDP and then the implementation should be straightforward because the mlpack LRSDP API is straightforward. The difficulty is still quite high, though, because debugging LRSDPs is complex.
deliverable: working, tested LMNN implementation with extensive documentation
difficulty: 9/10
necessary knowledge: in-depth C++ knowledge, understanding of semidefinite programs; familiarity with LMNN is helpful
relevant tickets: none open at this time
potential mentor(s): Ryan Curtin
why not this year? Manish Kumar completed this as his GSoC 2018 project.
description: The past two years in Summer of Code have seen the addition of a highly flexible collaborative filtering framework to mlpack. This framework offers numerous different types of matrix factorizations, and is likely the most flexible package for this (with respect to matrix factorizations). However, the implementation uses k-nearest-neighbors to select its recommendations, whereas there are more options. This project entails the investigation of alternatives (for example, weighted nearest neighbors and regression techniques) and the implementation of these alternatives in a flexible manner.
deliverable: Implemented alternatives to k-NN for recommendation selection
difficulty: 7/10
necessary knowledge: experience with C++ and templates, knowledge of recommendation systems, willingness to read the literature
relevant tickets: #406
references: this paper describes an alternative to k-NN recommendation selection: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.129.4662&rep=rep1&type=pdf
potential mentor(s): Ryan Curtin, Sumedh Ghaisas
why not this year? Wenhao Huang completed this as his GSoC 2018 project.
description: The past decade has seen an explosion of work focusing on underdetermined linear inverse problems, where the solution is assume to have some sparse structure. Compressed sensing, matrix recovery, lasso, etc all fall under this framework. Many specialized algorithms have been developed for particular problem instances. Recently, researchers have realized that many of these algorithms are actually instances of the same Frank-Wolfe algorithm. The Frank-Wolfe algorithm is an old algorithm to optimize a general convex function over a compact set. Martin Jaggi in this awesome paper showed how algorithms such as orthogonal matching pursuit and various low rank matrix recovery algorithms are simply instances of Frank-Wolfe, and proved general O(1/k) convergence rates. This is really neat stuff, and it would be great if mlpack provided a solid implementation of this framework.
deliverable: An implementation of Frank-Wolfe for the various atomic norms listed in Jaggi's paper, complete with test cases. The implementation should be general enough that we can recover OMP (orthogonal matching pursuit) by simply setting a few template parameters.
difficulty: 7/10
necessary knowledge: Some background in convex optimization would be very useful. While the actual algorithms are very simple, to really understand what is going on (which helps in debugging, for instance) requires some level of familiarity with the math.
relevant tickets: None at this time
potential mentor(s): Stephen Tu
why not this year? Chenzhe Diao completed this as his GSoC 2017 project.
description: Back in 2013, Marcus Edel built a very useful benchmarking system, found at https://github.com/zoq/benchmarks. This has been useful for comparing mlpack's performance to other libraries, and gives us nice graphs like this one:
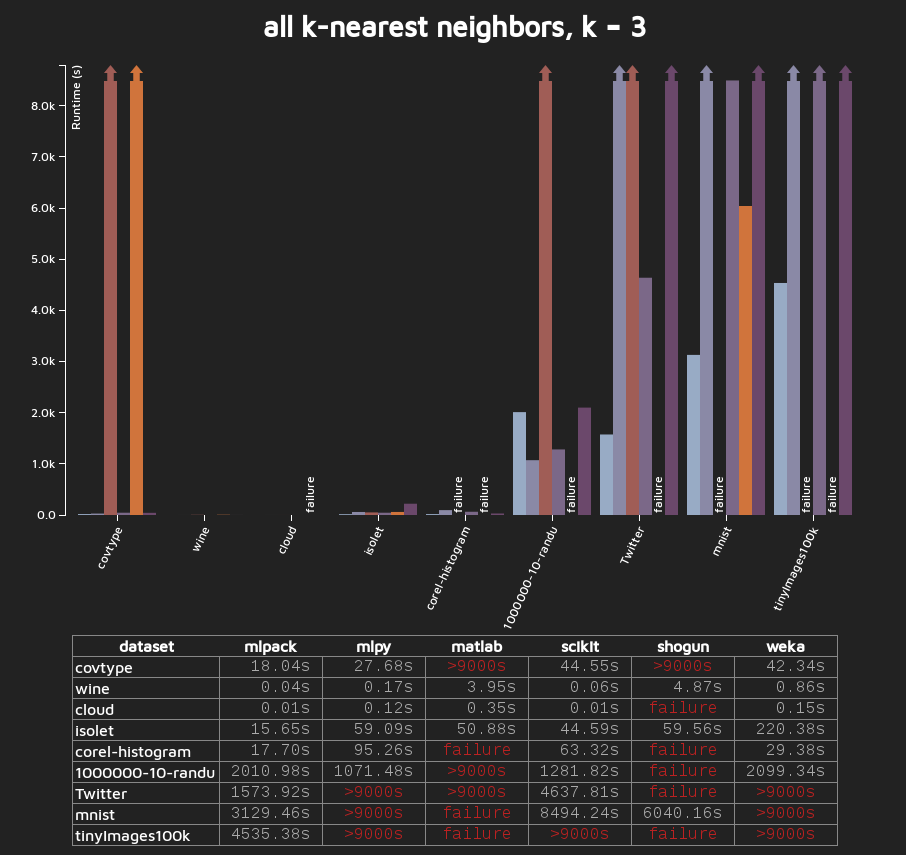
Although we as mlpack developers can use the benchmarking system and it's been very useful for us, it's less useful to the general public unless we compare thoroughly against other current implementations. There are many mlpack methods that have been added since the system has been built but are not benchmarked---some examples include the decision tree implementation, the Hoeffding tree implementation, parts of the ANN code, the DBSCAN implementation, and more.
There are a couple of different ideas to this project:
-
Select some mlpack algorithms that aren't currently well benchmarked, and add benchmarking scripts for mlpack's implementations and other implementations. At the end of the summer, we could have several images like the one above that show the speed of mlpack's implementations.
-
Select a single mlpack algorithm and focus on rigorously benchmarking that algorithm, and improving its runtime so that it is the fastest of all the implementations that are being compared.
Even a combination of those two ideas could be useful.
For more information on the benchmarking project, see https://github.com/zoq/benchmarks/wiki/Google-Summer-of-Code-2014-:-Improvement-of-Automatic-Benchmarking-System.
deliverable: benchmarks for mlpack algorithms and other implementations, with finished comparisons of runtimes or other performance measures
difficulty: 5/10
necessary knowledge: must be familiar with the machine learning algorithms that are being benchmarked, in order to be able to produce meaningful and relevant comparisons
relevant tickets: #886
potential mentor(s): Ryan Curtin, Marcus Edel
why not this year? Dewang Sultania completed the work on this project in GSoC 2017.
description: most data science tasks are not as simple as plugging in some data to a learner and taking the result. Typically, learners will have hyperparameters to tune, and users will also want to perform some sort of cross-validation to make sure the technique works well. In the very distant past (~2008-2010), mlpack did have a cross-validation module, but it had to be removed. Now, it would be a good time to re-add this support. For this project, it would be up to you to observe the current mlpack API, devise a design for cross-validation and/or hyper-parameter tuning modules, and then implement them.
Note that most mlpack learners have a very similar API, with the following training function:
template<typename MatType>
void Train(MatType& data,
arma::Row<size_t>& labels,
const X param1 = default, const X param2 = default, const X param3 = default, ...);
This makes it easy for us to create a CrossValidation module that can split a training set into some number of folds and evaluate some average measure (accuracy, error, AUC, and others) over all folds. The API for this could look similar to the idea below:
// Run 10-fold cross-validation on the DecisionTree.
CrossValidation<DecisionTree<>, Accuracy> cv(trainingSet, trainingLabels);
const double averageAccuracy = cv.Evaluate(10);
Still, there is extra complexity here---this example glosses over how the user will need to pass non-default training parameters for cross-validation. That is a detail that will need to be worked out in the proposal. For the hyper-parameter tuner, we wish to try a number of different values for the training parameters. I can imagine an API something like this:
/**
* Assume DecisionTree::Train() takes data, labels, then a size_t and double parameters:
* Train(MatType, arma::Row<size_t>, size_t, double).
*/
// The template parameters specify the type of model, and its parameters.
HyperParameterTuner<DecisionTree<>, size_t, double> tuner(trainingData, trainingLabels, testData, testLabels);
// Now we call Optimize() with the ranges to use for each parameter.
tuner.Optimize<GridSearchOptimizer<50 /* 50 bins for each dimension */>>(
Range<size_t>(1, 50), // range for size_t parameter
Range<double>(0.1, 0.5)); // range for double parameter
// Get the best decision tree.
DecisionTree<>& best = tuner.BestModel();
// Get the best parameters.
std::tuple<size_t, double> bestParams = tuner.BestParams();
Note that this is just an idea---there are many details left to be figured out, such as the measure to optimize for, how to handle regression models vs. classification models vs. other types of models, and so forth. Depending on the complexity of the proposal, it's possible that a single project might handle only the cross-validation module or the hyper-parameter tuner, instead of both.
difficulty: 6/10
deliverable: working cross-validation and/or hyper-parameter tuning module
necessary knowledge: basic data science concepts, good familiarity with C++ and template metaprogramming (since that will probably be necessary), familiarity with mlpack methods API (see src/mlpack/methods/*/)
relevant ticket(s): none are open at this time
potential mentor(s): Ryan Curtin
recommendations for preparing an application: This project can't really be designed on-the-fly, so a good proposal will have already gone through the existing codebase and identified what parts of the API will need to change (if any), what the API for the hyper-parameter tuner and cross-validation
why not this year? Kirill Mishchenko completed this project in his GSoC 2017 work.
description: The k-centers problem is a fundamental part of many machine learning algorithms (See Cortes & Scott, "Scalable Sparse Approximation of a Sample Mean", 2013 for a recent use of it). The basic problem is: given a set of points and integer k, choose k points that minimize the maximum distance between a point in the set and its nearest neighbor in the set. The ideas underlying the Dual-Tree Boruvka MST algorithm in mlpack could probably be extended to provide an efficient implementation for this problem. This one is more research / algorithm oriented, but would definitely require some implementation to evaluate the idea.
deliverable: working, tested k-centers implementation; paper comparing it to basic Gonzales algorithm and other implementations
difficulty: 7/10, but biased by being really related to Bill's thesis work
necessary knowledge: some understanding of geometry and spatial data structures, willingness to dive into some literature on the topic, basic C++
relevant tickets: none open at this time
potential mentor(s): Ryan Curtin, (possibly) Bill March
why not this year? Lack of mentor interest.
description: Recently, with the prevalence of multicore machines, there has been a large interest in parallelizing stochastic gradient methods such as SGD and SCD. While in principle these parallel implementations are quite simple, in practice there are lots of subtle details that need to be handled. Examples include, how do I anneal my step size, how much coordination/synchronization should I use, how should I partition my data in memory for good cache locality, do I solve the primal/dual, etc. This project would implement parallel SGD/SCD, and explore some of these design decisions.
deliverable: parallel implementations of stochastic gradient descent and stochastic coordinate descent, including both test cases and possibly an empirical analysis of the convergence behavior on various datasets for the issues discussed above.
difficulty: 5/10
necessary knowledge: C++, experience with writing multithreaded programs, some background in convex optimization would also be helpful
potential mentor(s): Ryan Curtin
why not this year? Shikhar Bhardwaj completed this project as part of his GSoC 2017 work.
Recurrent neural networks, such as the Long Short-Term Memory LSTM, have proven to be powerful sequence learning models. However, one limitation of the LSTM architecture is that the number of parameters grows proportionally to the square of the size of the memory, making them unsuitable for problems requiring large amounts of long-term memory. Recent approaches augmented with external memory have the ability to eluded the capabilities of traditional LSTMs and to learn algorithmic solutions to complex tasks.

The animation was created by using the Turing Machine Simulator check it out it's awesome.
Recently we’ve seen some exciting attemps attempts to augment RNNs with external memory such as:-
Neural Turing Machine: The NTM combines a RNN with an external memory bank and two different attention mechanisms allowing the model to perform many simple algorithms.
-
Neural Programmer: The Neural programmer is another approach that uses external memory to learn to create programs in order to solve a task without needing examples of correct programs.
-
Hierarchical Attentive Memory: HAM is some kind different as it uses a binary tree with leaves corresponding to memory cells. With the result to perform memory access in Θ(log n).
The underlying mlpack codebase could be extended to provide an efficient implementation for this kind of problems. A good project will select one or two algorithms and implement them (with tests and documentation) over the course of the summer. Note this project is more research/algorithm oriented, but definitely requires some implementation to evaluate the ideas. In addition, this project could possibly contain another research component -- benchmarking runtimes of different algorithms with other existing implementations.
difficulty: 8/10
deliverable: Implemented algorithms and proof (via tests) that the algortihms work with the mlpack's code base.
necessary knowledge: a working knowledge of neural networks, willingness to dive into some literature on the topic, basic C++
recommendations for preparing an application: To be able to work on this you should be familiar with the source code of mlpack. We suggest that everyone who likes to apply for this idea, try to compile and explore the source code, especially the neural network. If you have more time, try to review the documents linked below, and in your application provide comments/questions/ideas/tradeoffs/considerations based on your brainstorming.
relevant tickets: none are open at this time
references: Deep learning reading list, Deep learning bibliography, Neural Turing Machine, Neural programmer, Neural GPU, Hierarchical Attentive Memory
potential mentor(s): Marcus Edel
description: mlpack has an automatic build server (Jenkins) running at http://masterblaster.mlpack.org/. This build server is very powerful---it has 72 cores and 256GB RAM. However, it is in need of further configuration! Right now, there is the git commit build and the nightly matrix build, but there are some issues that should be addressed:
- the build matrix is incomplete---it doesn't test different compilers, different architectures, different Boost versions
- there is no testing on OS X
- there is no testing on Windows
The idea behind this project would be to fix these issues. For the OS X and Windows build, a virtual machine could be used---or I can even supply physical systems with network connections that could be used. But the real focus of the project should be the matrix build, which is helpful in diagnosing hard-to-find issues that arise under different configurations. For the matrix build, we can build a number of Docker containers, each with a different set of libraries and compilers, that can be used to build mlpack and run the tests.
The completed project would include a running OS X and Windows build, plus a series of Docker containers used by the matrix build. Ideally, the Dockerfiles should be automatically generated, so that if, e.g., a new Armadillo version comes out, we can easily generate a new Docker container that can be used.
difficulty: 4/10
deliverable: Windows/OS X VMs, plus Docker containers for the matrix build, all integrated into Jenkins builds
necessary knowledge: some Windows/OS X familiarity, some C++ (for debugging compilation errors), Docker and Jenkins familiarity
relevant tickets: none are open at this time
potential mentor(s): Ryan Curtin
why not this year? Saurabh Gupta completed this in GSoC 2017. You can see the results at http://masterblaster.mlpack.org/
description: mlpack focuses heavily on dual-tree algorithms, which each rely on a type of space tree (data structure). These tree types include kd-trees, ball trees, cover trees, vantage point trees, R trees, R* trees, metric trees, principal axis trees, k-means trees, random projection trees, Bregman ball trees, UB trees, R+ trees, Hilbert trees, X trees, segment trees, interval trees, range trees, and others. However, mlpack only implements kd-trees, cover trees, ball trees, R trees, and R* trees. This project involves implementing other tree types for mlpack. A good project will select a handful of tree types and implement them (with tests and documentation) over the course of the summer. The trees must be implemented according to this example interface so that they work with any type of dual-tree algorithm. In addition, this project could possibly contain a research component -- benchmarking runtimes of dual-tree algorithms when different types of trees are used.
difficulty: 5/10
deliverable: Implemented tree types and proof (via tests) that the tree types work with mlpack's dual-tree algorithms
necessary knowledge: Data structures, C++, knowledge of memory management
relevant tickets: #184, #275, #272, #227, #228, #289
potential mentor(s): Ryan Curtin
why not this year? The past several years have seen the implementation of many types of trees---there are few left. If you are still interested, you are welcome to create an application for this project, but you will have to find some new types of trees that mlpack does not implement. The list above is now inaccurate.
description: A better alternative to writing bindings by hand would be to have some script which processed machine learning method information and automatically generated bindings for MATLAB, Python, R, and perhaps other languages. SWIG, unfortunately, is not really an option for this. This project is somewhat exploratory and may not end up producing results if nothing is available, so this project will be research-intensive. In all likelihood the project will involve building a binding generator which can take in mlpack executable code (such as src/mlpack/methods/neighbor_search/allknn_main.cpp) and can produce a binding to another language that gives the same options as the command-line interface.
deliverable: automatic binding generators for mlpack methods which are easy to maintain
difficulty: 6/10
necessary knowledge: a working knowledge of what bindings are and a good ability to do research on software
relevant tickets: #202
why not this year? Automatic bindings are (mostly) implemented now. There is another project for adding more languages to the automatic bindings---check that one out instead.
description: mlpack provides an extensible, flexible exact nearest neighbor search implementation in the src/mlpack/methods/neighbor_search/ directory. This is a state-of-the-art implementation, with the ability to do dual-tree nearest neighbor search instead of single-tree nearest neighbor search, like other packages (i.e. FLANN, ANN, scikit-learn) do. However, there is currently no support for approximate nearest neighbor search, despite the popularity of approximate nearest neighbor search. This is a relatively simple extension to the existing NeighborSearch code. This project would have two components: the first component would be the implementation of approximate nearest neighbor search and either modification of the existing mlpack_allknn program or implementation of a new approximate nearest neighbor search command-line program. The second component would be working with the benchmarking system (https://github.com/zoq/benchmarks/) in order to produce rigorous comparisons between mlpack's approximate nearest neighbor search implementation and other libraries, such as FLANN, ANN, or LSHKIT (and even mlpack's LSH implementation). Depending on the robustness of the comparisons, this could result in a nice publication exploring the empirical performance of approximate nearest neighbor search schemes as implemented by existing machine learning libraries.
The figure below is some output from the existing benchmarking system on exact nearest neighbor search (from http://mlpack.org/benchmarks.html ); ideally, this project should result in some similar nice figures.
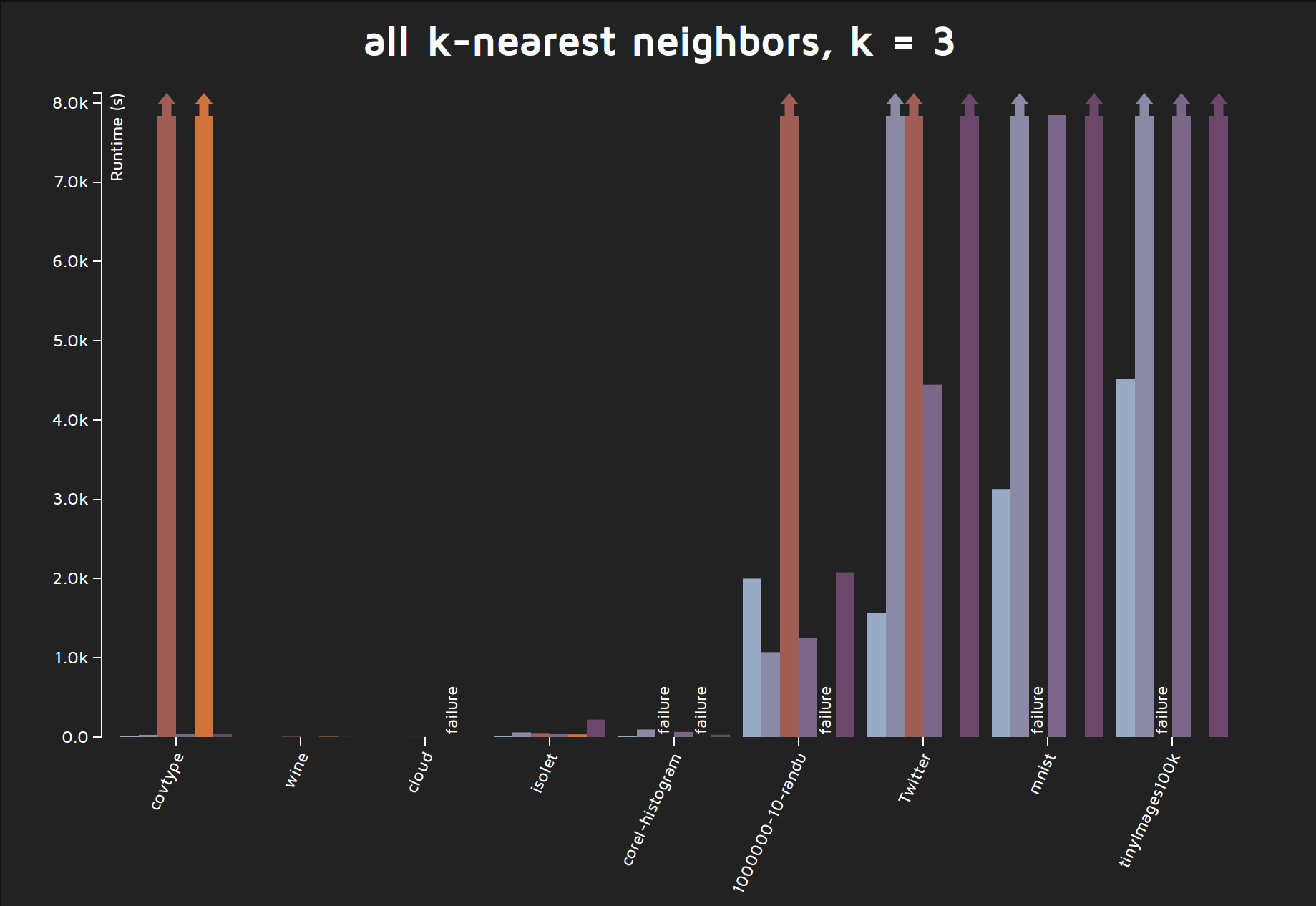
deliverable: working approximate kNN code with tests, benchmarking scripts, benchmark comparison numbers and figures
difficulty: 6/10
necessary knowledge: C++, Python, background on nearest neighbor search techniques
relevant tickets: (have not filled this out yet)
potential mentor(s): Ryan Curtin, Bill March
why not this year? This was already done by Marcos Pividori as part of GSoC 2016.
description: During Google Summer of Code 2014, Udit Saxena implemented decision stumps as part of his AdaBoost project. More recently, an implementation of streaming decision trees (Hoeffding trees) has been added. What would complement these things well would be to extend the implementation of decision stumps to full-blown decision trees (like ID3, CART, or C4.5). This could be done in one of several ways: adapting the existing decision stump code, writing a new class, or adapting the tree construction algorithm in density estimation trees (src/mlpack/methods/det/) to handle arbitrary loss functions. Other ideas might include implementation streaming Mondrian trees (http://papers.nips.cc/paper/5234-mondrian-forests-efficient-online-random-forests.pdf), but the overall goal here is to boost the number of classification techniques that mlpack has available.
deliverables: implementation of decision trees or similar algorithms, with tests and benchmarks comparing against other libraries
difficulty: 5/10
relevant tickets: none open at this time
potential mentor(s): Parikshit Ram, Nick Vasiloglou, Ryan Curtin
recommendations for preparing an application: A good candidate should be familiar with all of the decision tree and density estimation tree functionality in mlpack, in order to make a good decision about how it could be refactored or integrated into one class (or if that is even possible). API design is one of the most important things here, so the proposal should definitely have a section focusing on the API of the finished project.
why not this year? Decision trees are now implemented in mlpack.
description: The Nintendo Entertainment System (NES) wasn't the first unforgettable gaming console most of us ever played, but with the unforgettable library of games it certainly made an iconic part of many of our childhoods. Countless hours spent in heated Mario Bros. matches, or battles against Dr. Wily's destructive robots in the Mega Man series. And who could forget their first foray into the magic world of The Legend of Zelda? This project revitalizes this passion and combines it with recent developments in evolutionary algorithms to train artificial neural networks to play some of the unforgettable games. In more detail, this project involves implementing different neuro-evolution algorithms applied to NES games for mlpack. A good project will select one or two algorithms and implement them (with tests and documentation) over the course of the summer, e.g.:
- CNE: simple weight evolution over a topologically static neural network.
- CMA-ES: Covariance Matrix Adaptation Evolutionary Strategy.
- NEAT: evolution of weights and topology from simple initial structures.
- HyperNEAT: indirect encoding of network weights, using Compositional Pattern Producing Networks.
The neuro-evolution algorithms must be implemented according to the mlpack's neural network interface so that they work with various layer and network structures. In addition, this project could possibly contain a research component -- benchmarking runtimes of different algorithms with other existing implementations.

Note: We have set up an NES emulator (FCEUX) system. We already also have written some code to remotely communicate with the NES emulator, that allows a user to initiate a connection from their machine to our machine, and open up a port back to itself over this connection to e.g. get the current frame as a matrix, get the position, set input, etc. We can also obtain a system that can be used to train the neural networks. You can find the code used to communicate with the NES emulator here: https://github.com/zoq/nes
difficulty: 7/10
deliverable: Implemented neuro-evolution algorithms and proof (via tests) that the algortihms work with mlpack's neural network structure.
necessary knowledge: a working knowledge of what neural networks are, willingness to dive into some literature on the topic, basic C++
recommendations for preparing an application: To be able to work on this you should be familiar with the source code of mlpack. We suggest that everyone who wishes to apply for this idea, try to compile the source code and explore the source code, especially the neural network code and the code to communicate with the emulator. Students should at least go through the source code of the existing neural network code to get a good idea of how much work each algorithm would involve. If you have more time, try to review the documents linked below, and in your application provide comments/questions/ideas/tradeoffs/considerations based on your brainstorming.
relevant tickets: #412, #413, #414, #555
references: Deep learning reading list, Deep learning bibliography, HyperNEAT-GGP, Evolving Neural Networks through Augmenting Topologies
potential mentor(s): Marcus Edel
why not this year? This was already done by Bang Liu as part of GSoC 2016. However if you are still interested, you are welcome to create an application for this project since there are still some really interesting ideas that aren't implemented.
description: I would say that 90% of any machine learning problem is getting the data into a workable format. Real-world data is noisy, has missing values, is encoded improperly, is in weird formats, and has all kinds of other problems. Diagnosing and fixing these issues, and then preparing the data for input into a machine learning system, is often the most time-consuming part of the process. Usually, this is done with a conglomeration of Python tools (like pandas for instance), but it would be useful if mlpack users did not need to preprocess their data in other software tools before putting it into mlpack. Thus, there are some useful pieces of functionality that could be added to mlpack:
- checking a dataset for loading problems and printing errors
- imputation strategies for missing variables
- splitting a dataset into a training and test set
- converting categorical features into binary features (or numeric features)
There should be a C++ API for these tools, but also a command-line program that could be used. Below is an example gif of what the interface might be able to do; this can be used as inspiration for a project proposal.

deliverable: command-line program for dataset tools and C++ API, plus extensive documentation and tutorials on how to use it
difficulty: 3/10
necessary knowledge: C++, preferably familiarity with data science workflows and tools
relevant tickets: none at this time
potential mentor(s): Ryan Curtin
recommendations for preparing an application: This is an open-ended project and a student should identify in their proposal which problems they intend to solve and clearly illustrate how they intend to solve them. Should this project be completed, it will likely see a high amount of use, so clear and comprehensive documentation is necessary. That means that the project proposal should be equally clear on how each of these goals should be accomplished. There is room for flexibility here, so, if the vision outlined above does not mesh with a vision that you have for this project, that's okay; let's discuss ideas!
why not this year? Keon Kim did this project last year. However, the mlpack_check_data tool was not implemented, so if you have a good idea for how to do that, feel free to bring it up for discussion!
description: Convolutional neural networks are the state-of-the-art algorithms for image classification. So it's not surprisingly, that almost everyone used some form of convolutional net for the annually held ImageNet competition. In 2012, it was won by DNNResearch using the convolutional neural network approach described in the paper by Krizhevsky et al. Last year the team named GoogLeNet placed first in the classification and detection challenges. The GoogLeNet team used a deep learning architecture that is more convolutional than previous network architectures which can increase the depth and width of the network without increasing significant the parameters, using a new module called inception. This project would involve implementing the components of the GoogLeNet architecture and afterwards evaluating the network on a smaller subset of the ImageNet data. While in principle, the basic implementation of the main module for the GoogLeNet the inception layer is quite simple, there are many fun spinoffs which has to be covered such as:
- Addressing the problem of generating possible object locations for use in object recognition step. The GoogLeNet Team used the Selective Search algorithm, which combines the strength of both an exhaustive search and segmentation in combination with the multi-box approach.
- Addressing the initialization of the network parameters. Since GoogLeNet contains over 100 individual models, the model initialization is tricky. Bad Initializations would produce no gradient for the learning process.
- Addressing the special structure which isn't linear at all, there are auxiliary classifiers connected to the intermediate layers that get also back propagated, to and provide additional regularization.
This project involves some really neat methods, and it would be great if mlpack provided a solid implementation of this architecture including a method to generate possible object locations.
deliverable: Implemented GoogLeNet architecture including a method to generate possible object locations such as selective search and proof (via tests) that the algorithms work with mlpack's neural network structure.
difficulty: 8/10
necessary knowledge: Some background in deep learning would be very useful. While the actual algorithms are simple, to really understand what is going on requires some level of familiarity with the math. But detailed knowledge of the methods is not necessary - only a willingness to read some documentation and papers.
recommendations for preparing an application: Being familiar with the mlpack codebase is important if you like to take up this idea. We suggest that you build the library and explore the functionality that needs to be touched during the summer. Another step would be to review the documents below, and to provide comments/questions/ideas/tradeoffs/considerations in your application and outline the primary steps you would follow.
relevant tickets: #412, #413, #414, #555
references:
- Going Deeper with Convolutions Description of the deep convolutional neural network architecture named "Inception".
- Selective Search for Object Recognition Description of the selective search algorithm that addresses the problem of generating possible object locations.
- Deep learning reading list, Deep learning bibliography
potential mentor(s): Marcus Edel
why not this year? This was already done by Nilay Jain as part of GSoC 2016.
description: Currently, there are MATLAB bindings contributed by Patrick Mason, but they are not comprehensive; there are some mlpack methods which do not have MATLAB bindings. This project entails developing the rest of the mlpack MATLAB bindings and standardizing them. Detailed knowledge of the machine learning methods is not necessary for this project -- only a willingness to read some documentation. Regardless, someone working on this project can expect to, over the course of the project, become at least somewhat familiar with state-of-the-art machine learning methods and how they work. Each binding consists of a MATLAB script which provides documentation and handles input, and a MEX file which passes the input to mlpack methods.
deliverable: MATLAB bindings for all mlpack methods (about twenty) with standardized APIs
difficulty: 2/10
necessary knowledge: MATLAB familiarity and some C++
why not this year? Realistically, the automatic bindings project is far more useful and interesting, and reduces the maintenance load of bindings significantly.
description: Similar to the MATLAB bindings, Python and R bindings would be useful for mlpack users who don't know C++ or would prefer to use Python or R to do large-scale machine learning. This project entails developing bindings for Python and R which have consistent API and documentation. Detailed knowledge of the machine learning methods is not necessary -- only a willingness to read some documentation. Regardless, someone working on this project can expect to, over the course of the project, become at least somewhat familiar with state-of-the-art machine learning methods and how they work. Because no previous work has been done on these bindings, an investigation into options for bindings and the necessary CMake configuration to build the scripts.
deliverable: Python bindings or R bindings (or both) for all mlpack methods (about twenty) with standardized APIs
difficulty: 3/10
necessary knowledge: Python knowledge, R knowledge, and some C++; CMake knowledge would be helpful but is not necessary
relevant tickets: #202
why not this year? Like the MATLAB bindings, this project is superseded by automatic bindings.
description: For widespread adoption of mlpack to happen, it is very important that relevant and up-to-date benchmarks are available. This project entails writing support scripts which will run mlpack methods on a variety of datasets (from small to large) and produce runtime numbers. The benchmarking scripts will also run the same machine learning methods from other machine learning libraries (see OtherLibraries) and then produce runtime graphs. This can be integrated into Jenkins so that benchmarks are auto-generated nightly, which could be very helpful in informing developers which of their changesets have caused speedups or slowdowns.
deliverable: an automated benchmarking system built into Jenkins
difficulty: 7/10
necessary knowledge: bash scripting (or other scripting languages; Python could work), some machine learning familiarity
why not this year? This project was completed as part of GSoC 2013 by Marcus Edel and improved in 2014 by Anand Soni. It's very cool; see http://www.mlpack.org/benchmark.html .
description: mlpack is packaged in Fedora and RHEL, but currently not in Debian due to the stringent packaging requirements. To complete this project, mlpack would need to be properly packaged for Debian and Ubuntu and submitted in the proper manner. This would involve a package review process and probably would result in the project's undertaker becoming a Debian contributor or Debian developer. Because this process is generally somewhat slow and depends on other people's input, it may be best combined with another simple, low-difficulty project.
deliverable: mlpack in Debian or Ubuntu repositories (or at least an in-motion process)
difficulty: 2/10 but includes a lot of reading documentation
necessary knowledge: Linux familiarity, knowledge of how the open-source community works, and shell scripting
relevant tickets: #327
why not this year? This is far too little work for a good GSoC project. It could be part of another project, though.
Increasingly in data science projects, it's important to be able to deploy the trained models onto some small device, like, perhaps, a Raspberry Pi, or an IoT-enabled security camera, or an embedded router, or some other computing device that doesn't have much RAM. But a modern project like mlpack, with its dependencies, can be a little hard to get onto these devices because it can have a big footprint! When I compile mlpack_test on my system, it's 44 MB! (And its dependencies, like OpenBLAS, are pretty big too!)

Now, to some, like my cat (pictured above), it might be exciting to some to put mlpack on things like a Raspberry Pi, but personally I like vintage computers and I think it would be way more exciting to put mlpack on the 386 I have sitting on my floor:


I would love to be able to put some mlpack algorithm (like, say, mlpack_knn) on that 5.25" floppy and get it running on that 386. But... that means we only have 1.2 MB to store mlpack and all of its dependencies! Can we even do that? That is the challenge of this project.
It could also be really cool to get mlpack running on something like a VoCore, and I'll happily buy one and set it up for a student to use. I'll also make anything else in my collection available to play with remotely (an old Sun SparcStation 10, a SunBlade 350, an SGI Octane, an SGI Onyx, a 486 that I have to get a new motherboard for, my MIPS router, old phones, a Nokia N810 (does that thing even still work?), anything else I can dig up...), and I can serve as the onsite hands to burn the mlpack floppy and put it in the 386.
And if you aren't interested in vintage computing, well, maybe I can dig up something newer. But it will still be resource-constrained since that's the point of the project! mlpack would be really useful for real-world applications if someone could train their model on a powerful desktop with mlpack, but then still be able to run it out in the field on whatever is available to them. 1.2 MB is an ambitious goal for sure. How do we get there? Below are some ideas:
- See what compiling with
-Osgets us. (You can do that way before the project starts, that might be a nice warmup and it shouldn't take long.) - Statically link mlpack against all its dependencies and strip unused code.
- Find any unused functions that are being compiled into mlpack programs and strip them too.
- Identify excessive RAM usage for resource-constrained devices, once the program is running.
- Set up QEMU with some limited systems that might serve as decent testbeds.
That's just a starting point. It would be up to you to figure out how to proceed with this one, and in the end, the goal would be that we could not only get mlpack running on the 386, but have a nice writeup detailing how we did it, and we could make it easy for others to get mlpack models running on their resource-constrained devices.
difficulty: 6/10
deliverable: build system changes for mlpack that allow it to be run on severely resource-constrained devices, a nice writeup of how it can be adapted for other uses, and perhaps a 5.25" floppy disk with some mlpack algorithm on it :)
necessary knowledge: good knowledge of C++ and low-level Linux details; linker knowledge and systems knowledge is a necessity; machine learning knowledge is somewhat helpful but not a huge prerequisite; cross-compilation will be necessary so you will need to know how to do that
recommendations for preparing an application: You should strive to submit an application that shows that you have a plan for how to put mlpack on something really small. Ideally, you should have already played with mlpack enough to have identified how large the applications built with mlpack already are, and how large their dependencies are. It will be crucial here to provide a good plan of how to approach the problem, since after all before you do the work you can't know how small mlpack will be after each improvement you make.
potential mentor(s): Ryan Curtin, Marcus Edel, Shikhar Jaiswal
As of last year, mlpack now has an automatic bindings system documented here. So far, bindings exist for Python, command-line programs, Markdown documentation, and PRs are in progress for Go and Julia; it would be really useful to add bindings for even more languages.

A couple of ideas for languages are given above---MATLAB, Octave, Java, Scala. But these are certainly not the only language for which bindings could (and should) be provided.
For this project, once you select your target language, you will have to design a handful of components:
-
The build system workflow and CMake infrastructure so that the bindings are properly built. i.e., for the command-line bindings, this is a single-step compilation, but for Python, this involves generating a Cython .pyx file, generating a setuptools setup.py file, then compiling the Cython bindings.
-
Handling and conversion of the different types from the input language. It's extremely important that matrices aren't copied during this step, so it is important to think this through beforehand as that may guide the design of the bindings in other ways.
-
Generation of the code for the target language from the PARAM_*() macros and PROGRAM_INFO() macros.
Any design process should certainly start by looking at the existing bindings, and thinking about how to make a proof-of-concept to the new language. It's important to use the existing automatic bindings system so that the bindings we do provide in the files like logistic_regression_main.cpp and others can work for all languages. So, unfortunately, hand-written bindings for each language will not suffice here, since they are difficult to maintain and keep in sync.
difficulty: 6/10
deliverable: working and tested binding generator to the target language, plus some simple examples of how they can be used for user documentation
necessary knowledge: strong knowledge of the details of the target language is necessary, as well as familiarity with the existing automatic bindings system
recommendations for preparing an algorithm: Start with the basics; think about how you would hand-write an efficient binding to the target language, and perhaps prepare a simple proof-of-concept for binding with the same functionality as of the simple programs like src/mlpack/methods/pca_main.cpp. Then, think about how you would automatically generate that hand-written binding from the sources in pca_main.cpp, and this will guide the design that you will use for the automatic binding generator to your target language. In your application, be sure to include a reasonable level of detail about the implementation; specifically, how the overall generator will work, how unnecessary copies will be avoided, how users will interact with the bindings, and so forth.
references: automatic bindings documentation
potential mentor(s): Ryan Curtin
project size: large project (~350 hours)
mlpack is used and developed in a wide variety of contexts. As a result of this, the CMake configuration files have to support different operating systems, compilers, and library paths. While the current solution works sufficiently, users with even slightly nonstandard setups often have a difficult time building mlpack from the source. In addition, some suboptimal compromises have been made, such as preventing the system to search for boost-cmake. Luckily, CMake has seen some new features in 3.0.0 and forward which can be used to fundamentally restructure the build process to be clearer and more portable. Note that the mlpack build process is reasonably complex and includes multiple other language bindings.
difficulty: 4/10
deliverable: working CMakeList files matching modern conventions
necessary knowledge: build system tools such as cmake and makefiles. Some resources for "modern" CMake can be found here, here, and here
relevant tickets: #2113, #2215
potential mentor(s): Ryan Birmingham
recommendations for preparing an application: It may be a good idea to prepare or adopt a simple project or proof of concept which uses "modern" CMake, to demonstrate an understanding of the requirements of this project.
project size: medium (~175 hours)
Various machine learning algorithms are implemented in C++ using mlpack. Thus, users should also be to visualize various metrics and data generated by these models. There are visualization libraries like OpenCV which helps in visualizing the model in C++, but in order to do so, the user is required to know the nitty-gritty of those libraries as well which is not feasible for time-constrained projects. So to improve visualizing mlpack models, there is a need for a visualization tool that will log various model metrics and would help in visualizing the training of models. There are various solutions to provide this feature. One solution is to develop the tool from scratch. Another idea would be to write code to integrate with the existing visualization tool like TensorBoard.
Note: As integrating with existing tools leads to limitations in features and also adds a dependency, a tool of our own would be the solution for the problem.
difficulty: 5/10
deliverable: working visualization tool/code that helps visualize different metrics of mlpack models (e.g loss, images, etc.) on TensorBoard.
necessary knowledge: Knowledge of event writing and projecting values using graphs.
relevant tickets: None
potential mentor(s): Ryan Birmingham
recommendations for preparing an application: It may be a good idea to prepare or adopt a simple project or proof of concept which helps in visualizing machine learning models, to demonstrate an understanding of the requirements of this project.
project size: medium (~175 hours) and large project (~350 hours)
Right now the basic solution to stacking Artificial Neural network(ANN) layers is to use a vector and stack layers in that, which works fine for basic networks but gets complicated if someone wants to design a more complex model which requires them to stack layer arbitrarily and connect the input and output of a single layer to multiple different layers.
We have been thinking of a DAG class that would aim to eliminate this constraint. A good way to go for this project would be by developing some simple DAG-structured networks as tests, and then implementing the code in a test-driven way: first implement the tests, then implement the basic DAG class so that the easiest test works, then generalize it to the more complicate classes.
deliverables: Working DAG class for ANN
difficulties: 7/10, That's obviously a number which I could think on top of my head knowing things that would go in but given the time it shouldn't be a hard project but could be one that requires a lot of testing and going back to the code to make sure it works.
relevant tickets: #2777
necessary knowledge: Knowledge of DAGs and their implementation and a good understanding of the ANN code base in mlpack.
potential mentor(s): Aakash Kaushik
project size: medium (~175 hours) and large project (~350 hours)
mlpack has a great ANN module but when compared to Tensorflow or Pytorch it still lags behind in terms of features and flexibility. Hence it would be great if the missing features can be hunted down and implemented/fixed. It often happens that when we need a specific feature, we open an issue, get that particular feature implemented and move on. In this context, a feature can be an extra parameter in one of the layers (for eg: padding support in maxpool layers) or implementation of a new layer, activation function, etc. from scratch. Research papers keep coming up and often there are improvements over existing layers. Another thing that comes to mind is the absence of accessor functions for some layers which can be fixed. There are quite some shortcomings that I cannot recall but they keep cropping up while using the library. The applicant is expected to be thorough with the ANN module structure of both libraries, i.e., mlpack and Pytorch (or anything else that you might use for reference) and also be comfortable with the basic maths behind the layers/functions he/she would be modifying or implementing from scratch. In addition to this, there are a number of open issues related to the ANN module which can be solved as part of this project. The entire project is to be done in such a way that all changes are backward compatible, i.e., previously written code shall still run without any issue.
difficulty: 6/10 (depends more on what exactly you are seeking to change)
deliverable: A reformed and more robust ANN module
necessary knowledge: Thorough knowledge of how mlpack layers are implemented, sufficient experience with Pytorch (or any other standard framework) and fundamental clarity about forward propagation, backward propagation and gradient mathematics. Extensive experimentation/work with mlpack will help you to build a strong proposal.
relevant tickets: Any open issue related to the ANN module.
potential mentor(s): Sreenik Seal
recommendations for preparing an application: This project is scalable to a certain degree, that is, by implementing only a couple of layers properly, one should be comfortable enough to work with the remaining layers. That being said, the application should also describe a solid design approach with respect to the reformed ANN codebase and explicitly mention the changes to be brought about in detail. To be kept in mind is also the fact that writing tests is as vital as the implementation of the feature itself. The proposal should also highlight how you are going to use the entire three months of coding period efficiently. This idea is open to some extent, i.e., the applicant has certain liberty in choosing the direction of the project. However, it is advisable to discuss your approach in the IRC before writing the proposal. Best of luck!
project size: medium (~175 hours) and large project (~350 hours)
Models repository aims to showcase the power of mlpack, with pre-trained, ready-to-use models written in mlpack. To the same effect, the goals of the project are listed below :

-
Adding ready to use state of the art deep learning models : Models repo currently has DarkNet(tiny, 19 and 53) and YOLOv1. Last year there were also attempts to add YOLOv3 and Bert models as well. Following the same trend, it would be nice to see various object classification / detection / segmentation. Since training these models without GPU might be cumbersome, we will depend on the weight conversion between mlpack and PyTorch (or any other framework). Refer to the PyTorch-mlpack Weight Converter. For more details refer to this models wiki-page.
-
Showcasing usage of models repo in examples repo : Demonstrate the usage of models repo API in examples repo, to show how easy it is to use pre-trained models in mlpack.
-
Building on the existing dataloader : models repo provides an awesome dataloader that allows you read image / object detection datasets. It would be really nice to see support for other types as well. For more details refer to this dataloaders wiki-page.
-
Adding support for more standard datasets : Currently, the dataloader allows user to download and load datasets like Pascal VOC in single line. This can be extended to other datasets as well. For more details on supported datasets refer to the supported datasets section.
-
Building on Augmentation class : The Augmentation class allows users to manipulate / augment their dataset. Currently it supports only resize feature for images. This provides room to add new augmentations.
-
Showcase usage of augmentation class in examples repo : Demonstrate the usage of augmentation class in examples repo, to show how easy it is to augment datasets in a single line.
-
Adding visualisation tools for computer vision models : Add functions like
PlotBoundingBoxesthat take in an image and coordinates of a bounding box and displays an image with bounding boxes. -
Adding CLI for features in models repo
Note : A potential student doesn't need to implement everything listed above. The goals chosen will vary with difficulty of model / algorithm chosen to implement.
deliverable: State of the art pre-trained model. Support for standard datasets. Improved Data-loaders. More augmentation tools.
difficulty: Difficulty will depend on the algorithms selected for implementation.
necessary knowledge: Familiarity with general NN algorithms and analyzing results with plotting tools. Being able to hack around mlpack ANN and RL codebase.
relevant tickets: None so far
potential mentor(s): Kartik Dutt
recommendations for preparing an application : The application should ideally have some pseudo-code explaining the API of the new model / dataset / dataloader and how it would help the organization (i.e. usage of the model / dataset). It should also mention timeline and targets for each phase. This idea can be stretched to very complex algorithms ergo the applicant has certain liberty in choosing the direction of the project. It is advisable to discuss your algorithms / datasets in the mailing list before writing the proposal. Looking forward to working with you!
project size: large project (~350 hours)