Documentation Testing
This page covers how documentation and test cases are managed, both the manual process involved when making API modifications, and the automatic process involved in running tests.
The following figure gives an overview of how documentation is generated:
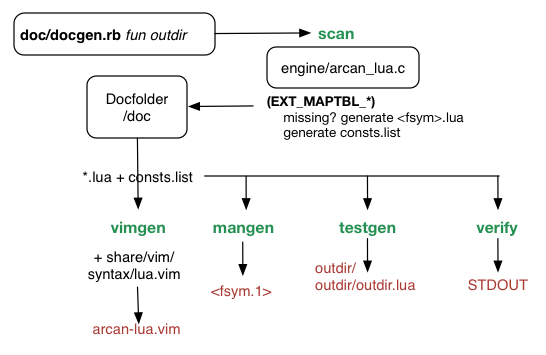
Documentation is managed by a rather crude ruby script (doc/docgen.rb) that accepts a single command and expects to be run with the current directory set to doc. The big one is scan that takes the engine Lua interface mapping code (src/engine/arcan_lua.c) and looks for the tables at the end that describe which functions are to be exposed as part of the API and checks against the existing files in the /doc folder that should match the pattern function_name.lua. If there are any files missing, empty stubs will be generated.
The contents of such a stub will look something like this:
-- function_name
-- @short: short description of the function and its purpose
-- @inargs: req_arg, *optional_arg*
-- @longdescr: multi line description that explains the use
of the function and interpretation of arguments e.g. *req_arg*
-- in more detail.
-- @note: there can be multiple note entries
-- @note: each note describes corner cases and details to consider
-- @group: functiongroup
-- @cfunction: function_inc
function main()
#ifdef MAIN
#endif
#ifdef MAIN2
#endif
#fidef ERROR
#endif
#ifdef ERROR2
#endif
end
While the basic fields of this format are simple enough, the use of ifdef MAIN etc. may need some explanation. These are combined with the C pre-parser (cpp) to generate code examples of both valid (MAIN) and invalid (ERROR) cases. This is used both when generating manpages and when running doc testing.
There are also a few possible but optional fields,
-- @exampleappl: tests/interactive/something
-- @flags: experimental, deprecated, incomplete
Exampleappl is used to link to a specific appl for more complex demonstration of how the function can be applied. The possible flags indicate if the function is planned for removal (deprecated) or will change radically (experimental) or possibly fail to work in the way described (incomplete).
The other commands works using doc/*.lua as basis.
The two commands mangen and testgen requires an outdir to be provided as the second command-line argument where the output will be saved.
The vimgen command looks for a lua.vim file in the usual places e.g. /usr/share/vim/syntax, /usr/local/share/vim/syntax then adds function and constant highlights to it and saves as arcan-lua.vim. In order for constant highlights to be generated, a consts.list file needs to be created in doc/constdump. This is generated by running arcan with doc/constdump set as appl.
Testgen will create a lot of subdirectories in two trees (test_ok, test_fail) of the pattern: function_nameNUM where NUM corresponds to the testcase index (MAIN, MAIN2, ...).
The reason for this is covered in the doc testing description further below.
The last command, verify scans for lua files that have not been filled in correctly (missing fields, examples, error examples). The implementation is rather primitive at the moment, it should be expanded to check changes to the corresponding code-block in the arcan_lua.c to make sure that API and documentation is synchronized.
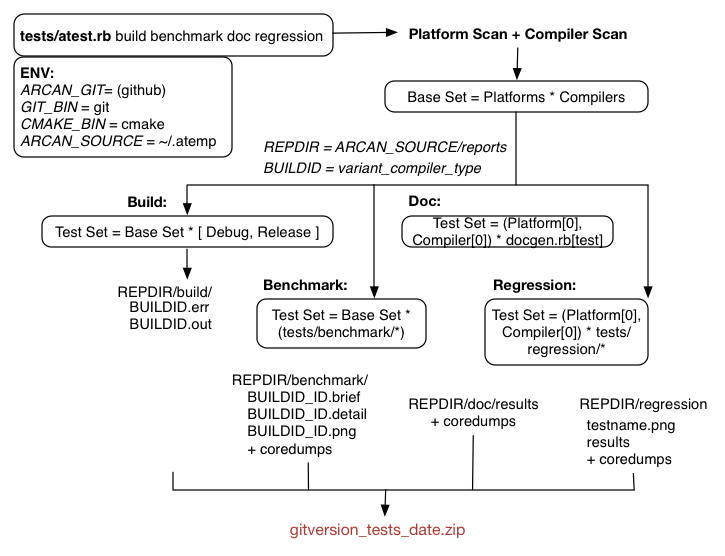
The following figure gives an overview of how testing is done:
Automated test setups is still very much a work in progress, particularly in terms of tracking results and controlling operating systems and environments.
With environments, we mean that due to the nature of arcan, we cannot rely on virtual machines for testing anything more complicated than the build setups, and many platforms require exclusive resource access that may be in conflict with display servers that are already running etc. so the testing environment requires rather dedicated OS control.
To explain the figure above, we have a ruby script for managing testing much like docgen.rb for generating documentation. This script relies on a few environment variables (as indidicated by the ENV box where the defaults are specified to the right of the assignment operator).
It is invoked by simply stating which test cases (build benchmark doc regression) to run through, and multiple ones can be specified in the same batch.
If there is no valid repository in the ARCAN_SOURCE directory, the script will first clone and set up a git repository there (or attempt to pull in updates), along with a temporary report directory for intermediate output files.
This directory is first populated with positive / failing outputs from the various stages along with copies of eventual core-dumps and stdout/stderr of executing arcan. At the end, all possibly relevant results are collated into an output directory that is compressed into a report archive.
The build- stage takes varying length depending on operation system and mode as it configures and compiles a normal arcan build for each available video platform for each available compiler and in both release and debug-mode.
This is primarily to verify that the engine configures and compiles properly and that any possible warnings or errors gets recorded.
The doc stage uses the tool mentioned above to generate a test case for every Lua function. The engine is built in debug mode with a specialized tracing function that records Lua to C function calls along with their respective arguments to track the functions covered, and in that way also get the list of functions that are not covered (estimate coverage).
For each MAIN- case, the engine is invoked with a hook- script that shuts down after a certain number of ticks. The reason for this is that a lot of the documentation examples will just perform some action then leave the engine in a living state.
For each ERROR- case, it is checked to make sure that the engine shuts down with a real warning and that the return value from executing the engine is something other than success.
The benchmark cases are all created using the support script benchmark.lua. The principle behind this script is that we define a load function that is used to increment engine load until a lower threshold is reached.
For every increment, data is logged to a detailed report and the values of the cutoff point are logged to a brief report. The detailed report is also plotted (if gnuplot is installed and available) and saved as an image.
The set of regression tests is increased whenever an engine component is refactored or when there is a known and reported bug (proper bug fixed should include a regression testing appl that provokes the issue) that have been addressed.
Regression testing is done on release builds with a reference image that has been manually verified. Each test case will run for a number of seconds then store a screenshot that is compared against the reference image.
There are two additional testing categories that is not part of the automated testing setup, security and appl specific. The security tests cover manually controlled tests that either generates nasty data patterns and sends across trust boundaries in the hopes of exposing bugs (fuzzing). There is also as a specialized insecurity build of the engine that only permits one appl to be run that is hardcoded to the name insecure.
This appl gets access to a new set of functions that can be used to develop and test exploits against the engine given certain common subset of vulnerabilities (stack overflow, wild pointers, use after free etc). The primary reason for this feature is to hasten the development of protection and monitoring mechanisms.
The appl specific test cases concern the larger support appls that have been developed: gridle, awb, durden and senseye. These are combined with either the event layer record and replay mechanism, or the corresponding post-hook script for replaying previous inputs. The reason for these cases not being automated and part of the previously mentioned setup is that they the appls are not entirely completed and that there is overlap with future profile- based optimization and parameter trimming techniques (estimated around 0.8).