![]()
DISCLAIMER: This API Client is not associated with Finra in any kind - it is a pure personal - nonprofit/non commercial open source software project
The main purpose of this simple API client is the comfortable retrieval of data via Python. The original idea was to explore finra as free resource to get access to short sale data for the us-stock market, therefore a few related resources and valuable discussions for the interpretation are attached as well.
Further resources that were used for development and that need to be credited:
For details on the authorization see, the Official documentation.
pip install finra_client
or:
pip3 install finra_client
Via git clone:
git clone https://github.com/RobertHennings/FINRA_CLIENT
Setting up the personal Finra API in the Finra (Web) platform and obtain client id and client secret
In theory valid credentials are not needed for API calls, but some datasets exhibit access restrictions. To also load these ones, credentials are needed. Extensive etailed documentation available here.
The section in the official documentation shows how to get there:
-
- Create an Account (Individual use) here: https://ews.finra.org/auth/registration-type?AppName=FINRA_GATEWAY&Forward_URL=https://gateway.finra.org/app?rcpRedirNum=1
-
- Head to the API Console Tab and click: "ADD API CREDENTIAL":
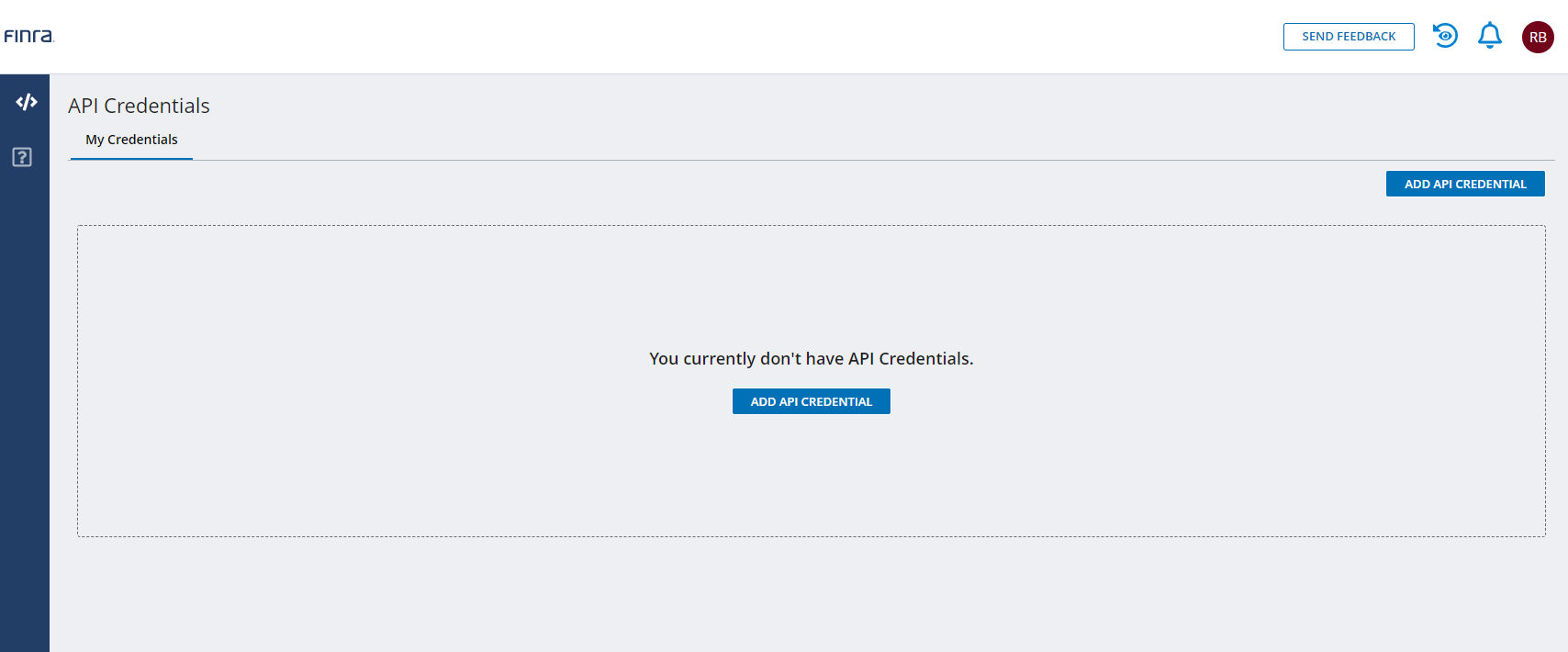
-
- Apply user settings to the API (name) and the selected type. The available dropdown types depend in the Account type, i.e. am individual account hat the options: "MOCK" or "PUBLIC". Select: PUBLIC
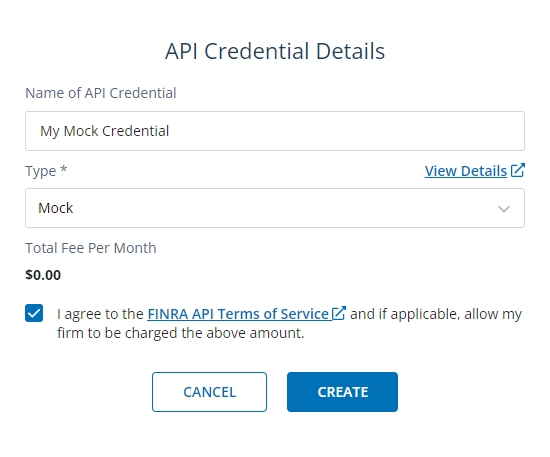
-
- The user account will receive an Email with the request to activate the API:
In case you wonder, yes indeed it is the same window that opens up when you click "Forgot Password" when trying to login. Here you have to be careful and fill in the field User ID the ID of the just created API and set the Password for it:
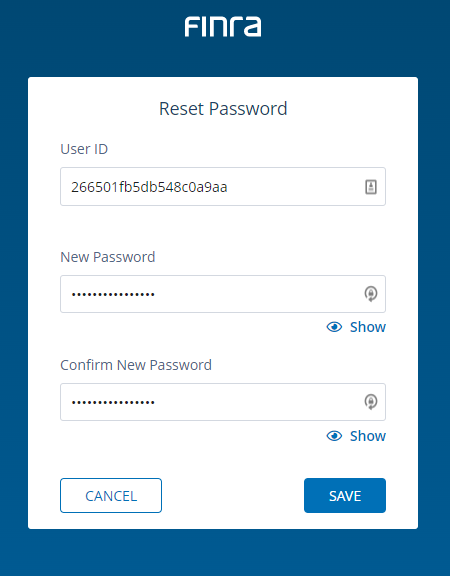
-
- After successfull setup, the activated API should be visible:

Some API Credential Creation Tips from the Finra documentation:
- The API Credential name is an alias that you provide to help you remember your use intention for the credential. It can be changed in the API Console at any time (feature coming soon).
- The Type dropdown allows you to select the type of credential you would like to create. The allowable selections are based on your user type. For example, if you are logged-in to the API Console as an Individual User, the allowable selections will include mock and public.
- The Total Fee Per Month will change to reflect any fees associated with a credential type. When you select the SAVE button to create a credential with an associated fee, your organization will be invoiced for that credential on E-Bill.
- The API Secret create link sent via email EXPIRES in 24 hours. If the link expires, you will need to contact the API Support team to have another create link sent via email (a client secret reset feature is coming soon).
- You will also receive the API Client Id in a separate email (subject: FINRA API Developer Center – Important Information). You will need the API Client Id when activating the API credential.
- Look in your Junk Mail/Spam Filters for the FINRA API email messages if you do not receive them within a few minutes. If you do not receive the email messages within an hour contact the API Support team to let us know.
- When activating the API Credential and choosing an API Secret note that the User ID you are asked to provide is the Client ID shown in the My Credentials tab for the API Credential you are activating and NOT the User ID you used to login to FINRA Gateway.
- Note that the API Secret expires in one year and will need to be reset it via the API Console (feature coming soon).
-
- Clone the repository or download the client via
piporpip3
- Clone the repository or download the client via
-
- Rename the
example_config.pytoconfig.pyand fill in the personal data here:
- Rename the
CLIENT_ID = "8q74qbbfbfkar8o3q" # personal client id - stays constant
CLIENT_SECRET = "oiww-bkaarg38-fgiq73r" # personal client secret - stays constant
CLIENT_CREDENTIAL_PATH = r'path/to/FinraProject' # location of projectThere are two main ways how to use and set up the client:
(Rename the example_config.py to config.py after cloning or downloading anf fill in your data)
-
- Defining all necessary default parameters in the
config.pyfile, importing them via:import config as cfginto the scripting file (.py file), then setting the needed client instance arguments from thecfgvariables explicitly when instantiating the client intance
- Defining all necessary default parameters in the
-
- Defining all necessary default parameters in the
config.pyfile, importing them via:import config as cfginto thestrava_client.py, there setting up the default variant of the strava client that can be directly imported with these pre-setting into the scripting file (.py file)
- Defining all necessary default parameters in the
IMPORTANT
For the first time use, it is necessary to follow the first procedure, described in more detail down below.
After the credentials have been obtained, saved and the needed static path and file name variables have been set, the second procedure can be used comfortably.
With custom settings (imported from the config.py file into the scripting file(.py) or directly set in the scripting file) - ASSUMED: first time use and no credentials are saved or existing:
import config as cfg
CLIENT_ID = cfg.CLIENT_ID
CLIENT_SECRET = cfg.CLIENT_SECRET
DIFFERENT_BASE_URL = "https://api.finra_new_api_adress.org" # i.e. setting the base url as custom parameter when it might change
from finra_client import FinraClient # import the general class
finra_client_instance = FinraClient(
base_url=DIFFERENT_BASE_URL,
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
override_credentials=True # For the first time use the override argument has to be set to True
)If the client has already been used and set up - credentials were loaded - they have to be provided:
import config as cfg
CLIENT_ID = cfg.CLIENT_ID
CLIENT_SECRET = cfg.CLIENT_SECRET
DIFFERENT_BASE_URL = "https://api.finra_new_api_adress.org"
CLIENT_CREDENTIAL_FILE_NAME = cfg.CLIENT_CREDENTIAL_FILE_NAME
CLIENT_CREDENTIAL_PATH = cfg.CLIENT_CREDENTIAL_PATH
from finra_client import FinraClient
finra_client_instance = FinraClient(
base_url=DIFFERENT_BASE_URL,
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
client_credential_file_name=CLIENT_CREDENTIAL_FILE_NAME,
client_credential_path=CLIENT_CREDENTIAL_PATH
)With using the defined default settings (imported from the config.py in the strava_client.py):
from finra_client import finra_client
finra_client_instance = finra_clientIn the finra_client.py file, the default settings can be changed:
finra_client = FinraClient(
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
client_credential_file_name=CLIENT_CREDENTIAL_FILE_NAME,
client_credential_path=CLIENT_CREDENTIAL_PATH
)With proxy settings:
from finra_client import FinraClient
proxies = {
'https':'https--proxy',
'http': 'http--proxy'
}
verify = True
finra_client_instance = FinraClient(
proxies=proxies,
verify=verify,
# potential other settings
)After installation or cloning of the respository, there are the following files present at the regarding location, that are important to obtain the needed credentials:
-
example_config.py
-
credentials.json
Rename the example_config.py to config.py
In the config.py define the following parameters, that will appear as:
CLIENT_ID = "8q74qbbfbfkar8o3q" # personal client id - stays constant
CLIENT_SECRET = "oiww-bkaarg38-fgiq73r" # personal client secret - stays constant
CLIENT_CREDENTIAL_PATH = r'path/to/FinraProject' # location of projectOther not utterly important static variables that can be imported, used and/or further customized are the following present:
PROJECT_PATH = r'path/to/FinraProject'
CLIENT_CREDENTIAL_FILE_NAME = r'credentials.json'
BASE_URL = "https://api.finra.org"
OAUTH_URL = "https://ews.fip.finra.org/fip/rest/ews/oauth2/access_token"
REQUEST_TIMEOUT = 90
DATA_ENDPOINT = "/data"
METADATA_ENDPOINT = "/metadata"
PARTITIONS_ENDPOINT = "/partitions"
MOCK_DATA_ENDING = "MOCK"
USE_MOCK = False
HISTORIC_DATA_ENDING = "/HISTORIC"
REPORTING_FACILITY_DICT_TXT_FILES = {
"FINRA Consolidated NMS": "CNMS",
"FINRA/NASDAQ TRF Chicago": "FNQC",
"ADF": "FNRA",
"FINRA/NASDAQ TRF Carteret": "FNSQ",
"FINRA/NYSE TRF": "FNYX",
"ORF": "FORF",
}
ERROR_CODES_DICT = {
400: {
"message": "Bad request",
"return_": None
},
401: {
"message": "Failed to authenticate, check your authenticat…",
"return_": None
},
410: {
"message": "Unauthorized",
"return_": None
},
403: {
"message": "Forbidden",
"return_": None
},
404: {
"message": "Not Found",
"return_": None
},
405: {
"message": "Method not allowed",
"return_": None
},
406: {
"message": "Not acceptable",
"return_": None
},
409: {
"message": "Conflict",
"return_": None
},
415: {
"message": "Unsopprted Media Type",
"return_": None
},
500: {
"message": "Internal Server Error",
"return_": None
},
502: {
"message": "Bad Gateway",
"return_": None
},
503: {
"message": "Service Unavailable",
"return_": None
},
504: {
"message": "Gateway Timeout",
"return_": None
}
}
SUCCESS_CODES_DICT = {
200: {
"message": "OK",
"return_": "Success"
},
201: {
"message": "Created",
"return_": "Success"
},
204: {
"message": "No content",
"return_": "Success"
}
}
DATASET_DICT = {
"Equity": {
"otcMarket": ["blocksSummary", "consolidatedShortInterest", "monthlySummary"
"otcBlocksSummary", "regShoDaily", "thresholdList", "weeklySummary",
]
},
"FINRA Content": {
"finra": ["finraRulebook", "industrySnapshotFirmsByRegistrationType"]
},
"Firm": {
"firm": ["4530filings"]
},
"Fixed Income": {
"fixedIncomeMarket": ["agencyMarketBreadth", "agencyMarketSentiment",
"corporate144AMarketBreadth", "corporate144AMarketSentiment",
"corporatesAndAgenciesCappedVolume", "corporateMarketBreadth",
"corporateMarketSentiment", "securitizedProductsCappedVolume",
"treasuryDailyAggregates", "treasuryDailyAggregates",
"treasuryMonthlyAggregates"]
},
"Registration": {
"registration": ["accounting"]
}
}Brief explanation of the main config parameters:
| Parameter | Setting (example) | Data type (python) | Description |
|---|---|---|---|
| CLIENT_ID | "8q74qbbfbfkar8o3q" | str | The obtained athlete or user id that is displayed in the online API section of the Finra website. |
| CLIENT_SECRET | "oiww-bkaarg38-fgiq73r" | str | The obtained athlete or user secret that is displayed in the online API section of the Finra website. |
| CLIENT_CREDENTIAL_PATH | r"path/to/FinraProject" | raw str | This defines where the credential file credentials.json exists and will be read from. |
Brief explanation of the optional config parameters:
| Parameter | Setting (example) | Data type (python) | Description |
|---|---|---|---|
| PROJECT_PATH | r"path/to/FinraProject" | raw str | Defining the general, overarching project loaction. Can be used in f-strings to define where the credentials.json is or should be saved and where the files should be saved or loaded from. |
| CLIENT_CREDENTIAL_FILE_NAME | r'credentials.json' | raw str | Name of the file that holds the credentials, saved as .josn format |
| BASE_URL | "https://api.finra.org" | str | Base endpoint of the Finra API, details |
| OAUTH_URL | "https://ews.fip.finra.org/fip/rest/ews/oauth2/access_token" | str | Endpoint for authorization |
| ERROR_CODES_DICT | {400: {"message": "Error", "return_": None}, 401: {"message": "Error", "return_": None}} | Dict[int, Dict[str, str]] | Customizable error codes dict for more precise logging and control flows, details can be found here |
| SUCCESS_CODES_DICT | {200: {"message": "URL succesfully retrived", "return_": "Success"}} | Dict[int, Dict[str, str]] | Customizable success codes dict for more precise logging and control flows, details can be found here |
| REQUEST_TIMEOUT | 90 | int | Default seconds before a request timeout will be raised |
| DATA_ENDPOINT | "/data" | str | Default enpoint to load data from, details get request, details post request |
| METADATA_ENDPOINT | "/metadata" | str | Default endpoint to load the metadata from, details |
| PARTITIONS_ENDPOINT | "/partitions" | str | Default endpoint to load the partitions from, details |
| MOCK_DATA_ENDING | "MOCK" | str | Default Mock dataset ending that will be appended to the given dataset name: datasetNameMOCK |
| USE_MOCK | False | bool | Determines if per default only Mock data should be used (for testing for example) |
| HISTORIC_DATA_ENDING | "/HISTORIC" | str | Default endpoint to load historic versions from, more details can be found here |
| REPORTING_FACILITY_DICT_TXT_FILES | {"FINRA Consolidated NMS": "CNMS", "FINRA/NASDAQ TRF Chicago": "FNQC", "ADF": "FNRA", "FINRA/NASDAQ TRF Carteret": "FNSQ", "FINRA/NYSE TRF": "FNYX", "ORF": "FORF"} | Dict[str, str] | Default encoding for the reporting facilities |
| DATASET_DICT | {"Equity": {"otcMarket": ["blocksSummary", "consolidatedShortInterest", "monthlySummary", "otcBlocksSummary", "regShoDaily", "thresholdList", "weeklySummary"]},"FINRA Content": {"finra": ["finraRulebook", "industrySnapshotFirmsByRegistrationType"]},"Firm": {"firm": ["4530filings"]},"Fixed Income": {"fixedIncomeMarket": ["agencyMarketBreadth", "agencyMarketSentiment", "corporate144AMarketBreadth", "corporate144AMarketSentiment", "corporatesAndAgenciesCappedVolume", "corporateMarketBreadth", "corporateMarketSentiment", "securitizedProductsCappedVolume", "treasuryDailyAggregates", "treasuryDailyAggregates", "treasuryMonthlyAggregates"]},"Registration": {"registration": ["accounting"]}} | Dict[str, Dict[str, List[str]]] | Default mapping for the available datasets for each (asset-) category |
IMPORTANT
Set parameters for the arguments: client_credential_path and client_credential_file_name and especially set the argument override_credentials to True
import config as cfg
CLIENT_ID = cfg.CLIENT_ID
CLIENT_SECRET = cfg.CLIENT_SECRET
finra_client_instance = FinraClient(
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
override_credentials=True,
client_credential_path=CLIENT_CREDENTIAL_PATH,
client_credential_file_name=CLIENT_CREDENTIAL_FILE_NAME
)After calling, the command line will display the for every called URL performed testing function and the set place and file name of the credentials:
OK for URL: https://ews.fip.finra.org/fip/rest/ews/oauth2/access_token?grant_type=client_credentials
Strava credentials saved at: client_credential_path/client_credential_file_nameAfterwards the active client instance can be used for all remaining methods.
Here an example:
groupName = "fixedIncomeMarket"
datasetName = "treasuryWeeklyAggregates" # daily blocked by authorization
# Starting point: Request the metadata for a dataset to explore what (data-) fields are available
metadata = finra_client_instance.get_dataset_metadata(groupName=groupName, datasetName=datasetName)
print(f"Metadata for groupName: {groupName} and datasetName: {datasetName}: \n{metadata}")
Metadata for groupName: fixedIncomeMarket and datasetName: treasuryWeeklyAggregates:
{'datasetGroup': 'FIXEDINCOMEMARKET', 'datasetName': 'TREASURYWEEKLYAGGREGATES', 'description': 'Treasury Weekly Aggregates', 'partitionFields': ['beginningOfWeekDate'], 'fields': [{'name': 'beginningOfWeekDate', 'type': 'Date', 'format': 'yyyy-MM-dd', 'description': 'Date of the beginning of the week - Monday.'}, {'name': 'productCategory', 'type': 'String', 'description': 'Category of the Treasury product'}, {'name': 'yearsToMaturity', 'type': 'String', 'description': 'Range of years to maturity'}, {'name': 'benchmark', 'type': 'String', 'description': 'Run Code'}, {'name': 'atsInterdealerVolume', 'type': 'Number', 'description': 'Volume in Dollars for ATS-Interdealer'}, {'name': 'dealerCustomerVolume', 'type': 'Number', 'description': 'Volume in Dollars for Dealer-Customer'}]}At a later stage when a new instance is initiated or used, the saving location and the credential file name can be directly set:
from strava_client import StravaClient
finra_client_instance = FinraClient(
client_credential_file_name="credentials.json",
client_credential_path="path/to/credentials",
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET
)Alternatively the arguments client_credential_file_name and client_credential_path can be specified in the config.py and directly loaded in the finra_client.py or in the scripting file itself set and imported from the config.py.
Here the respective part in the finra_client.py file:
finra_client = FinraClient(
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
client_credential_file_name=CLIENT_CREDENTIAL_FILE_NAME,
client_credential_path=CLIENT_CREDENTIAL_PATH
)Later in the scripting file us the client:
from finra_client import finra_client
finra_client_instance = finra_clientAt a later stage when a new instance is initiated or used, the saving location and the credential file name can be directly set and used from now on:
from finra_client import FinraClient
finra_client_instance = FinraClient(
client_credential_file_name="credentials.json",
client_credential_path="path/to/FinraProject",
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET
)Alternatively the arguments client_credential_file_name and client_credential_path can be specified in the config.py and directly loaded in the finra_client.py or in the scripting file itself set and imported from the config.py.
The easiest and fastest way to create an instance is then:
from finra_client import finra_client
finra_client_instance = finra_clientDuring the later use, the refreshing of the credentials is automatically taken care of by the client_instance itself and nothing else remains to be done, since the expiry datetime is part of the loaded credentials and also can be viewed:
print(dt.datetime.fromtimestamp(finra_client_instance.credentials["expires_in"]).strftime("%Y-%m-%d %H:%M:%S"))
2025-04-01 05:22:52After the client has been loaded and instanciated, the first go to point is to get an overview of all the available datasets per (asset-) category, that can be loaded.
import config as cfg
DATASET_DICT = cfg.DATASET_DICT
# See the DATASET_DICT, for example pick a data group (i.e.) Fixed Income and pick a dataset name
print(f"Available Groups:\n{DATASET_DICT.keys()}")
# dict_keys(['Equity', 'FINRA Content', 'Firm', 'Fixed Income', 'Registration'])
data_group = "Fixed Income"
print(f"Available Datasets for the group: {data_group}\n{DATASET_DICT.get(data_group).get(list(DATASET_DICT.get(data_group).keys())[0])}")
Available Datasets for the group: Fixed Income
['agencyMarketBreadth', 'agencyMarketSentiment', 'corporate144AMarketBreadth', 'corporate144AMarketSentiment', 'corporatesAndAgenciesCappedVolume', 'corporateMarketBreadth', 'corporateMarketSentiment', 'securitizedProductsCappedVolume', 'treasuryDailyAggregates', 'treasuryDailyAggregates', 'treasuryMonthlyAggregates']From this starting point the user can inspect and load additional details for a chosen dataset via the method: get_dataset_metadata:
groupName = list(DATASET_DICT.get(data_group).keys())[0]
datasetName = DATASET_DICT.get(data_group).get(groupName)[0]
# Starting point: Request the metadata for a dataset to explore what (data-) fields are available
metadata = finra_client_instance.get_dataset_metadata(groupName=groupName, datasetName=datasetName)
print(f"Metadata for groupName: {groupName} and datasetName: {datasetName}\n{metadata}")
Metadata for groupName: fixedIncomeMarket and datasetName: agencyMarketBreadth
{'datasetGroup': 'FIXEDINCOMEMARKET', 'datasetName': 'AGENCYMARKETBREADTH', 'description': 'Trace Agency Market Breadth', 'partitionFields': ['tradeReportDate'], 'fields': [{'name': 'tradeReportDate', 'type': 'Date', 'format': 'yyyy-MM-dd', 'description': 'Trade date'}, {'name': 'productCategory', 'type': 'String', 'description': 'Category of the product'}, {'name': 'totalTrades', 'type': 'Number', 'description': 'Total number of trades'}, {'name': 'advances', 'type': 'Number'}, {'name': 'declines', 'type': 'Number'}, {'name': 'unchanged', 'type': 'Number'}, {'name': 'fiftyTwoWeekHigh', 'type': 'Number', 'description': '52 weeks high'}, {'name': 'fiftyTwoWeekLow', 'type': 'Number', 'description': '52 weeks low'}, {'name': 'totalVolume', 'type': 'Number', 'description': 'total volume count'}]}The loaded metadata can serve as later starting point for applying filters. This will be shown later on.
Some datasets have available partitions that can be obtained via the method: get_dataset_partitions:
datasetName = "treasuryweeklyaggregates"
partitions = finra_client_instance.get_dataset_partitions(groupName=groupName, datasetName=datasetName)
print(f"Partitions for groupName: {groupName} and datasetName: {datasetName}\n{partitions}")
Partitions for groupName: fixedIncomeMarket and datasetName: treasuryweeklyaggregates
{'datasetGroup': 'fixedincomemarket', 'datasetName': 'treasuryweeklyaggregates', 'partitionFields': ['beginningOfWeekDate'], 'availablePartitions': [{'partitions': ['2023-02-06']}, {'partitions': ['2023-01-30']}, {'partitions': ['2023-01-23']}, {'partitions': ['2023-01-16']}, {'partitions': ['2023-01-09']}, {'partitions': ['2023-01-02']}, {'partitions': ['2022-12-26']}, {'partitions': ['2022-12-19']}]}Once the user has chosen a dataset from a (asset-) category, the data can be loaded via the method: get_dataset:
groupName = "fixedIncomeMarket"
datasetName = "treasuryWeeklyAggregates" # daily blocked by authorization
dataset = finra_client_instance.get_dataset(groupName=groupName, datasetName=datasetName)
print(f"Data for groupName: {groupName} and datasetName: {datasetName}\n{pd.DataFrame.from_dict(dataset)}")
Data for groupName: fixedIncomeMarket and datasetName: treasuryWeeklyAggregates
beginningOfWeekDate yearsToMaturity ... atsInterdealerVolume productCategory
0 2022-12-19 None ... 249.2 Bills
1 2022-12-19 None ... 0.8 FRNs
2 2022-12-19 <= 2 years ... 109.7 Nominal Coupons
3 2022-12-19 <= 2 years ... 67.2 Nominal Coupons
4 2022-12-19 > 2 years and <= 3 years ... 94.0 Nominal Coupons
.. ... ... ... ... ...
171 2023-02-06 <= 5 years ... 5.8 TIPS
172 2023-02-06 > 5 years and <= 10 years ... 6.1 TIPS
173 2023-02-06 > 5 years and <= 10 years ... 1.4 TIPS
174 2023-02-06 > 10 years ... 1.8 TIPS
175 2023-02-06 > 10 years ... 0.2 TIPS
[176 rows x 6 columns]As before mentioned, filters can be applied when loading data up front.
Sorting restrictions can be viewed here.
But how do we now what can be filtered? For that the metadata of a dataset needs to be requested via the method: get_dataset_metadata:
groupName = "otcMarket"
datasetName = "regShoDaily"
metadata = finra_client_instance.get_dataset_metadata(groupName=groupName, datasetName=datasetName)
# The available Metadata shows the attributes (columns) that can be used for filteringNext, say we want to load short sale related data for a specific stock ticker (say Google with its ticker: GOOG) and a specific date range for a project. Since we are looking for equity related data, we can inspect the available equity datasets:
asset_category = "Equity"
print(finra_client_instance.dataset_dict.get(asset_category))
{'otcMarket': ['blocksSummary', 'consolidatedShortInterest', 'monthlySummaryotcBlocksSummary', 'regShoDaily', 'thresholdList', 'weeklySummary']}When we want to try out a specific dataset, say regShoDaily, we then retreive the metadata exactly as already above, via the method: get_dataset_metadata:
groupName = "otcMarket"
datasetName = "regShoDaily"
metadata = finra_client_instance.get_dataset_metadata(groupName=groupName, datasetName=datasetName)
print(metadata)
{'datasetGroup': 'OTCMARKET', 'datasetName': 'REGSHODAILY', 'description': 'Reg SHO Daily File', 'partitionFields': ['tradeReportDate'], 'fields': [{'name': 'tradeReportDate', 'type': 'Date', 'format': 'yyyy-MM-dd', 'description': 'Trade Date'}, {'name': 'securitiesInformationProcessorSymbolIdentifier', 'type': 'String', 'description': 'Security symbol'}, {'name': 'shortParQuantity', 'type': 'Number', 'description': 'Aggregate reported share volume of executed short sale and short sale exempt trades during regular trading hours'}, {'name': 'shortExemptParQuantity', 'type': 'Number', 'description': 'Aggregate reported share volume of executed short sale exempt trades during regular trading hours'}, {'name': 'totalParQuantity', 'type': 'Number', 'description': 'Aggregate reported share volume of all executed trades during regular trading hours'}, {'name': 'marketCode', 'type': 'String', 'description': 'Market Code'}, {'name': 'reportingFacilityCode', 'type': 'String', 'description': 'Reporting Facility identifier. Values are : N = NYSE TRF, Q = NASDAQ TRF Carteret, B = NASDAQ TRF Chicago, D = ADF'}]}Here we can see the columns of the dataset and their metadata. We can filter for the specific stock ticker (GOOG) using the column: securitiesInformationProcessorSymbolIdentifierand for the specific date range using the column: tradeReportDate. The full code is shown down below, with all available filtering mechanics, including the domainFilters, that are not available for this exact dataset we are loading here in this example.
Per default the retrieved dataset records are set to 1000, we can increase it up to 5000, for additional information see the Rate limit page of the official documentation.
The filters are lists of dictionaries, because theoretically a filter or even multiple ones can be applied to every column of the dataset, therefore stacking them up in lists as structural explanation.
ticker = "GOOG"
fieldName = "securitiesInformationProcessorSymbolIdentifier"
compareType = "equal"
compareFilters = [{"compareType": compareType,
"fieldName": fieldName,
"fieldValue": ticker}]
startDate = "2020-01-01" # YYYY-MM-DD
endDate = "2023-05-10" # YYYY-MM-DD
fieldName = "tradeReportDate"
dateRangeFilters = [
{"startDate": startDate,
"endDate": endDate,
"fieldName": fieldName
}
]
fieldName = "MarketCenter" # not available for the exemplary dataset
values = ["A", "B", "C", "J"] # not available for the exemplary dataset
domainFilters = [
{"fieldName": fieldName,
"values": values
}
] # not available for the exemplary dataset
limit = 5000
groupName = "otcMarket"
datasetName = "regShoDaily"
dataset = finra_client_instance.get_dataset(
groupName=groupName,
datasetName=datasetName,
limit=limit,
compareFilters=compareFilters,
dateRangeFilters=dateRangeFilters
)
pd.DataFrame.from_dict(dataset)
reportingFacilityCode ... shortExemptParQuantity
0 NCTRF ... 0
1 NQTRF ... 9650
2 NYTRF ... 1200
3 NCTRF ... 0
4 NQTRF ... 477
... ... ... ...
4995 NCTRF ... 0
4996 NQTRF ... 0
4997 NYTRF ... 0
4998 NQTRF ... 0
4999 NYTRF ... 0
[5000 rows x 7 columns]To run the finra client locally (i.e. after cloning the repository), one can just simply create a virtual environment. See the dedetailed documentation here
Depending on your python version, open a terminal window, move to the desired loaction via cd and create a new virtual environment.
ON MAC
Python < 3:
python -m venv name_of_your_virtual_environmentOr provide the full path directly:
python -m venv /path/to/new/virtual/name_of_your_virtual_environmentPython >3:
python3 -m venv name_of_your_virtual_environmentOr provide the full path directly:
python3 -m venv /path/to/new/virtual/name_of_your_virtual_environmentActivate the virtual environment by:
source /path/to/new/virtual/name_of_your_virtual_environment/bin/activateor move into the virtual environment directly and execute:
source /bin/activateDeactivate the virtual environment from anywhere via:
deactivateMove to the virtual environment or create a new one, activate it and install the dependencies from the requirements.txt file via:
pip install -r requirements.txtor:
pip3 install -r requirements.txtAlternatively by providing the full path to the requirements.txt file:
pip3 install -r /Users/path/to/project/requirements.txtMake sure the dependencies were correctly loaded:
pip listor:
pip3 listSome further examples on how to run and set up the client in a scripting file can be found
in the tests folder in the local.py file.
Please also consider writting meaningful messages in your commits.
API: an (incompatible) API change
BENCH: changes to the benchmark suite
BLD: change related to building numpy
BUG: bug fix
DEP: deprecate something, or remove a deprecated object
DEV: development tool or utility
DOC: documentation
ENH: enhancement
MAINT: maintenance commit (refactoring, typos, etc.)
REV: revert an earlier commit
STY: style fix (whitespace, PEP8)
TST: addition or modification of tests
REL: related to releasing numpyRobert Hennings, 2025