{kind=link}
The database allows Sparkify to perform queries in a simplified and intuitive way. With the organization of data in a database, it is possible to extract a list of the most heard songs, users who hear the songs, their levels and when they listen, allowing analytics time to create promotions for users who use the music service, suggest music according to style of each user and understand which songs make the most hits on the platform.
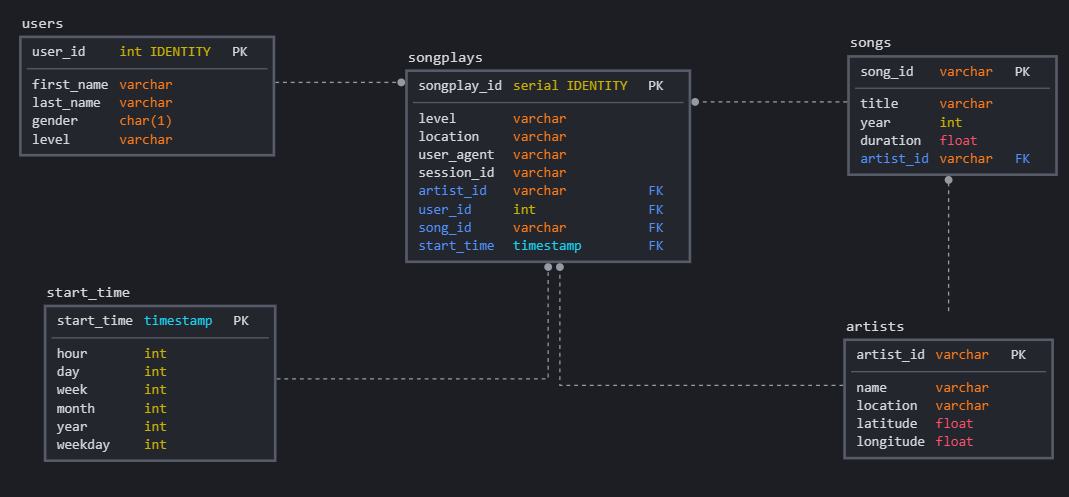
The project was built based on the star architecture. There are 4 dimension tables: users **, ** songs, **artistis ** and **time **, the 4 tables refer to the entities of our business model, there is also a fact table called **songplays ** that allows a performatic queries, without the use of JOINs. Songplays table contains the data of a specific song played, its user and artist.
- create_tables.py: This file is responsible for connect to postgresql and drop existing sparkifydb database. This script is also responsible for run create table queries and drop table queries defined at sql_queries.py;
- sql_queries.py: This file is responsible for define queries to create and drop tables at database, and insert/select data into tables;
- etl.py: This file is responsible for gets all files at data folder, clear data and insert into sparkifydb database tables correctly;
- etl.ipynb: This is a simples python notebook, that shows how etl.py file handles the data in the data folder and insert into the correct tables;
- test.ipynb: This is a simple python notebook, that you can use to run queries and test it.
For fill the songs table, we get all json files at data/song_data, so, we make a division in information, artists information are storage into artists table and songs information are storage on songs table, if we try insert artists or songs that have already been inserted, the insert script simply ignore the new register. The columns in tables follow the same json keys patterns.
For fill the users and start_time tables, we get all json files at data/log_data. Then, we filter the "next song" action registers and insert the timestamp information in start_time table, extracting the year, day, month, weekday and week from timestamp. If we try insert duplicated timestamps, the insert query will ignore the second register.
For users table, we also get the information from json files at data/log_data, filtering the user's information. But, in this case, if we try to insert a duplicated user, the query insert will update the level for this user. This occur because one user can change his level.
For this fact table, for each object in json file (at data/log data folder) we make a merge with the information and select the artist's id and songs id from the respective tables. After that, we make an insert into songplays table, that have information about the artist, song, user and start time, like the schema shows before. In this case, when we try to insert duplicated registers, the insert query will ignore the second register.
To run the project, follow the steps:
- Run create_tables.py for drop existents sparkifydb databases and create a new sparkifydb database;
- Run etl.py for insert all data from data folder files in respective tables. (Make sure that you have the data folder when you run this script)