[ English | 中文 ]
![]()
🤗 Hugging Face | 🤖 ModelScope | 🖥️ Demo | 📃Data | paper | WeChat (微信) | Wisemodel
Taiyi (太一): A Bilingual (Chinese and English) Fine-Tuned Large Language Model for Diverse Biomedical Tasks
Project Background
With the rapid development of deep learning technology, large language models (LLMs) like ChatGPT have made significant progress in the field of natural language processing. In the context of biomedical applications, large language models facilitate communication between healthcare professionals and patients, provide valuable medical information, and have enormous potential in assisting diagnosis, biomedical knowledge discovery, drug development, and personalized healthcare solutions, among others. However, in the AI community, there is a relative scarcity of existing open-source biomedical large models, with most of them primarily focused on monolingual medical question-answering dialogues in either Chinese or English. Therefore, this project embarks on research dedicated to large models for the biomedical domain and introduces the first version of a bilingual (Chinese and English) biomedical large language model named 'Taiyi', aiming to explore the capabilities of large models in handling a variety of bilingual natural language processing tasks in the biomedical field.
NEWs
- 2024/03/01 Our paper is online in JAMIA.
- 2024/01/05 We released our raw instruction data (Taiyi_Instruction_Data_001). The data is distributed under CC BY-NC-SA 4.0. The original benchmark datasets that support this study are available from the official websites of natural language processing challenges with Data Use Agreements.
- 2024/01/03 Due to limited resources, the demo was moved to huggingface space and used INT8 quantitative deployment. To experience better results, it is recommended to download weights and use scripts for non-quantitative deployment testing.
Project Highlights
- Rich Biomedical Training Resources:For the biomedical domain, this project has collected and organized a diverse set of bilingual (Chinese and English) Biomedical Natural Language Processing (BioNLP) training datasets. This collection includes a total of 38 Chinese datasets covering 10 BioNLP tasks and 102 English datasets covering 12 BioNLP tasks. To facilitate task-specific requirements, standardized data formats have been designed and applied for consistent formatting across all datasets.
- Promising Bilingual BioNLP Multi-Task Capability:Using rich bilingual instruction data (over 1 million samples) to fine-tune the LLM, the model show the bilingual capability in various BioNLP tasks including intelligent biomedical question-answering, biomedical dialogues, report generation, information extraction, machine translation, title generation, text classification, and more.
- Outstanding Generalization Capability Besides the biomedical conversation abilities, the model still retains general domain conversation abilities. Through the design of diverse instruction templates, it exhibits good generalization across various scenarios of similar tasks, and even stimulates the model's ability for zero-shot learning.
To promote the development of NLP in the biomedical field, this project releases Chinese-English BioNLP dataset curation details, Taiyi large model weights, and model inference usage scripts.
Overview of Framework
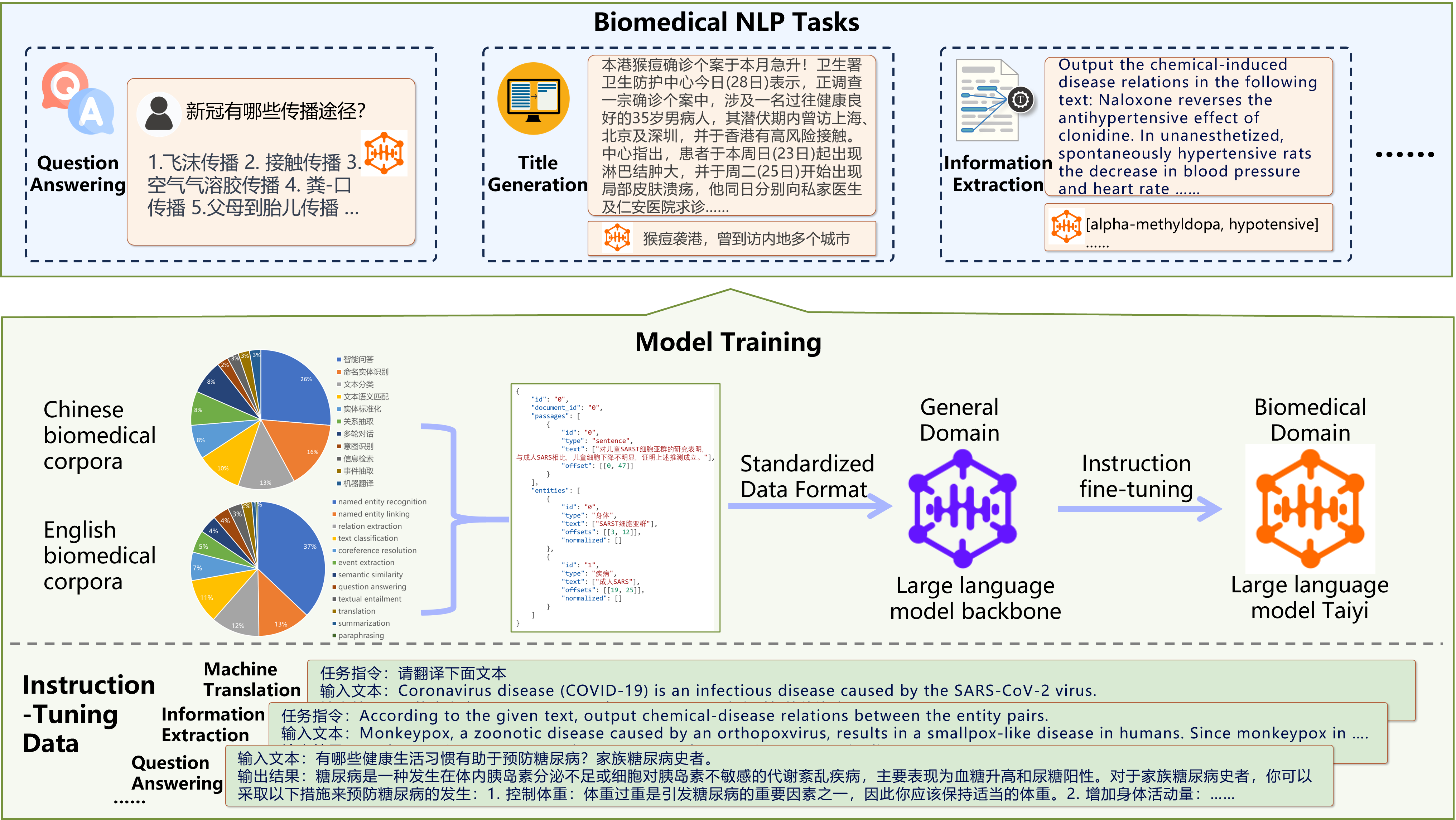
- Taiyi (太一):A Bilingual (Chinese and English) Biomedical Large Language Model Finetuned with Rich Biomedical Data
Task Introduction
Biomedical question answering is designed to assist users in obtaining answers and information related to the field of biomedical science through a question-and-answer format. It contributes to more effective management of biomedical information, enhances the quality of medical decision-making, and improves the effectiveness of biomedical education.
Examples
Example in Chinese
用户:最近肚子总是隐隐作痛,感觉胀胀的,吃下去的东西都没法吸收,胃疼的特别厉害,偶尔伴有恶心想吐的感觉,请问是什么回事?
太一:您好,根据您的描述,您可能正在经历胃肠道不适的症状。这些症状可能是由多种原因引起的,例如消化不良、胃炎、胃溃疡、胆囊炎、胆囊结石等。建议您尽快就医,进行相关检查以确定病因,并根据医生的建议进行治疗。同时,您可以注意饮食,避免辛辣、油腻、刺激性食物,多喝水,保持良好的生活习惯,避免过度劳累和情绪波动。希望您早日康复。
Example in English
User:What is the best treatment for sleep problems?
Taiyi:The best treatment for sleep problems depends on the specific cause of the sleep problem. There are many different factors that can contribute to sleep problems, including sleep disorders, stress, anxiety, depression, medication, and lifestyle habits. Some common treatments for sleep problems include:
1. Cognitive-behavioral therapy (CBT) for sleep disorders, which is a type of talk therapy that helps people identify and change negative thoughts and behaviors that are interfering with their sleep.
2. Relaxation techniques, such as deep breathing, progressive muscle relaxation, and visualization, which can help people relax and fall asleep.
3. Sleep hygiene, which is a set of practices that promote healthy sleep habits, such as avoiding caffeine and electronics before bedtime, maintaining a regular sleep schedule, and creating a relaxing bedtime routine.
4. Medications, such as sleep aids, which can help people fall asleep and stay asleep, but may have side effects and risks.
5. Lifestyle changes, such as exercise, avoiding alcohol and nicotine, and creating a relaxing bedtime routine, which can all help improve sleep quality..
Task Introduction
The Taiyi model is capable of simulating natural language conversations between medical experts and patients. These conversations can encompass various biomedical topics, including medical inquiries, disease prevention, medication consultations, and more.
Examples
Example in Chinese
用户:什么是鼠疫?
太一:鼠疫是由鼠疫杆菌引起的传染病,鼠疫杆菌是一种细菌,通常通过跳蚤叮咬传播。鼠疫杆菌主要存在于啮齿类动物的,如老鼠、土拨鼠等,当这些动物被感染后,它们会通过跳蚤叮咬传播给其他动物,包括人类。鼠疫杆菌主要通过跳蚤叮咬传播,也可以通过直接接触感染。
用户:它有什么预防方法吗?
太一:
预防鼠疫的方法包括以下几点:
避免接触感染源:尽量避免接触啮齿类动物,如老鼠、土拨鼠等,特别是在疫区或疫区附近。
保持个人卫生:勤洗手,保持身体清洁,避免接触感染源。
食用安全食品:在疫区或疫区附近,尽量避免食用未经煮熟的肉类、蛋类等食品。
做好防护措施:在疫区或疫区附近,佩戴口罩、手套等防护用品,避免直接接触感染源。
接种疫苗:在疫区或疫区附近,可以接种鼠疫疫苗,增强免疫力,预防感染。
用户:鼠疫常发生在哪些国家?
太一:鼠疫是一种全球性传染病,主要分布在温带和寒带地区。目前,鼠疫主要分布在亚洲、非洲和欧洲等地区。其中,亚洲地区是鼠疫的主要流行区,包括中国、蒙古、俄罗斯、朝鲜、韩国、日本等国家。非洲地区是鼠疫的高发区,包括非洲中部、南部、东部等地区。欧洲地区是鼠疫的高发区,包括欧洲中部、北部、东部等地区。
Example in English
User:Do you know colchicine?
Taiyi:Colchicine is a medication used to treat gout, a type of arthritis that causes joint pain, swelling, and redness. It works by reducing the amount of uric acid in the body.
User:Does it have any potential side effects?
Taiyi:Yes, Colchicine can have potential side effects. Some of the common side effects of Colchicine include nausea, vomiting, diarrhea, abdominal pain, and loss of appetite. However, there are also some rare but serious side effects of Colchicine, such as muscle weakness, confusion, and difficulty breathing. If you experience any of these side effects, you should seek medical attention immediately.
Task Introduction
Medical report auto-generation aims to summarize information during the diagnostic process. The task requires the language model to generate medical reports in a specified format based on patient self-reports and doctor-patient dialogues. This task can assist doctors in handling a large volume of medical information more effectively and provide accurate diagnoses and treatment recommendations to patients.
Examples
Example in Chinese
User Input:
问诊对话历史:
患者:小孩受凉了,流清鼻涕,咳嗽,应该是风寒咳嗽,去药店买哪种药好呢
医生:你好,宝宝咳嗽,流涕比较常见,西医角度上呼吸道感染可能性大,中医上叫做风寒咳嗽,请问宝宝除了咳嗽有没有其他不适症状呢?例如发热等,请详细描述一下,我好帮你诊治分析病情
患者:精神状态好,也没有发热,就是喉咙有一点痛,咳嗽
医生:先帮你分析一下病情,宝宝受凉之后免疫力降低,就会被细菌或病毒侵袭体内,气道分泌物增多,支气管平滑肌痉挛,咳嗽,咳痰,咽通。
医生:目前没有发热,宝宝病情不重,不用过分紧张的。
医生:我帮推荐治疗方法
医生:宝宝目前多大了?有没有再医院看过?做过化验检查
患者:嗯
患者:7岁,没去医院,做过很多检查,平常就是爱咳嗽,喉哝发炎
患者:医生说,扁桃体偏大
医生:近期这次有没有去医院看过?做过检查
医生:如果宝宝没有其他不适?可以口服氨溴索,桔贝合剂效果好
医生:另外如果条件允许,可以做做雾化吸入治疗直接作用与支气管粘膜,效果更直接
患者:不用做雾化吧,吃点药就行了
医生:也可以先吃药
患者:近期没有去过
医生:你们这次没有去医院看过?
患者:要吃消炎的吗
患者:没
患者:要吃消炎药吗
医生:你好,可以先不吃的
患者:那家里有蒲地蓝,可以吃吗
患者:口服液
患者:喉哝痛要吃吗
医生:先治疗看看,可以吃的,假如宝宝出现发热或咳嗽加重,医院就诊,复查血常规和胸片,那个时候再考虑加抗生素
患者:另外买个止咳的,行吗
医生:我们的观点是宝宝小,尽量少吃消炎药,可以先吃那几个药三天看看效果
患者:嗯谢谢
根据上述对话,给出诊疗报告
说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节。
Taiyi Output:
上述问诊对话的诊疗报告如下:
主诉:咳嗽、流涕。
现病史:患儿无明显诱因下出现咳嗽、流涕,无恶心呕吐,无其他明显不适症状。精神状态一般,胃纳一般,余如常。
辅助检查:暂无。
既往史:既往体健。
诊断:小儿咳嗽。
建议:口服氨溴索、桔贝合剂,密观。
Task Introduction
Biomedical named entity recognition aims to identify predefined biomedical entities from text. These entities can include biomedical concepts such as diseases, drugs, genes, proteins, and more.
Examples
Example in Chinese
User Input:
从下面文本中识别出指定的实体类型:
治疗以选用大环内酯类抗生素,沙眼衣原体肺炎也可用磺胺二甲基异唑,年长儿和成人用氟喹诺酮类效果也很好。
实体类型:疾病,药物
Taiyi Output:
疾病:沙眼衣原体肺炎
药物:大环内酯类抗生素; 磺胺二甲基异唑; 氟喹诺酮类
Example in English
User Input:
Extract the gene, disease entities from the following text:
Identification of a novel FBN1 gene mutation in a Chinese family with Marfan syndrome.
Taiyi Output:
gene: FBN1
disease: Marfan syndrome
Task Introduction
Biomedical relationship extraction aims to automatically extract predefined relationships or associations between biomedical entities from text, such as interactions between proteins and genes, therapeutic relationships between drugs and diseases, and more.
Examples
Example in Chinese
User Input:
给出句子中药物治疗关系类型的实体对:慢性阻塞性肺疾病@减少急性加重:有高质量的证据证实,β2 受体激动剂在减少 12-52 周急性加重方面比安慰剂更有效。
Taiyi Output:
具有药物治疗关系的实体对如下:[慢性阻塞性肺疾病, β2 受体激动剂]
Example in English
User Input:
Find the relations of drug entity pairs in the text:
Mitotane has been reported to accelerate the metabolism of warfarin by the mechanism of hepatic microsomal enzyme induction, leading to an increase in dosage requirements for warfarin. Therefore, physicians should closely monitor patients for a change in anticoagulant dosage requirements when administering Mitotane to patients on coumarin-type anticoagulants. In addition, Mitotane should be given with caution to patients receiving other drugs susceptible to the influence of hepatic enzyme induction.
Relation Types: ADVISE, MECHANISM, EFFECT, INT
Taiyi Output:
ADVISE: [Mitotane, coumarin-type anticoagulants]
MECHANISM: [Mitotane, warfarin]
Task Introduction
Biomedical event extraction is to extract structured biomedical events from unstructured and vast biomedical literature, mining the described biological entities in the literature, as well as the fine-grained relationships between biomedical events. This task can save time in manually reviewing literature and provide support for the construction of relevant databases, disease diagnosis, prevention research, and more.
Examples
Example in Chinese
User Input:
找出指定的临床发现事件属性:
因患者需期末考试,故予以口服“雷贝拉唑钠肠溶片”治疗,现腹痛情况明显好转。
事件抽取说明:临床发现事件由主体词,发生状态,描述词和解剖部位组成
Taiyi Output:
上述句子中的临床发现事件如下:
主体词:疼痛;发生状态:;描述词:明显好转;解剖部位:腹
Example in English
User Input:
Input text: "Contaminated drinking water is responsible for causing diarrheal diseases that kill millions of people a year.
Even Types: Treatment of disease, Cause of disease
Role Types: Cause, Theme
Please extract events from the input text.
Taiyi Output:
Cause of disease: (Trigger: responsible, Theme: diarrheal diseases, Cause: Contaminated drinking water]
Task Introduction
Machine translation can convert biomedical texts from one natural language to another. This task can assist in translating various medical questions and recommendations, disease names, symptoms, and other information between English and Chinese.
Examples
Chinese to English Translation Example
User Input:
将下面文本翻译成英文:
光动力疗法(PDT)作为一种新兴的肿瘤治疗手段,因其不良反应较少、靶向性好、可重复治疗等优点,已广泛应用于临床多种肿瘤的治疗。相比于手术、化疗及放疗等传统治疗策略,光动力疗法不仅可杀伤原位肿瘤,还可通过激活机体的免疫效应对转移瘤发挥抑制作用。然而,PDT诱导免疫效应的高低受多种因素影响,包括光敏剂在细胞内的定位和剂量、光参数、肿瘤内的氧浓度、免疫功能的完整性等。本文针对PDT介导抗肿瘤免疫效应的相关机制,以及PDT免疫效应的主要影响因素进行综述,以探讨PDT用于肿瘤治疗的未来发展方向。
Taiyi Output:
As a new tumor treatment method, photodynamic therapy (pdt) has been widely used in clinical practice because of its advantages of few side effects, good targeting, and repeatability. Compared with traditional treatment strategies, such as surgery, chemotherapy, and radiotherapy, pdt can not only kill the primary tumor, but also inhibit the metastatic tumor by activating the body's immune effect. However, the induction of immune effect by pdt is affected by many factors, including the localization and dose of photosensitizers in cells, light parameters, oxygen concentration in tumor, and the integrity of immune function. In this review, we focus on themechanisms of antitumor immune effect mediated by pdt, and the main influencing factors of immune effect of pdt, to discuss the future development direction of pdt in thetumor treatment.
English to Chinese Translation Example
User Input:
Translate the following text into Chinese:
Metabolic-associated fatty liver disease (MAFLD), formerly known as non-alcoholic fatty liver disease (NAFLD), is one of the most popular chronic liver diseases in the world. There are many explorations on the epidemiology and risk factors of the disease published in recent years. With the increasing burden of MAFLD on medical care and social economy, drug treatment of MAFLD has become an urgent research hotspot. Based on this, the current epidemiological status, risk factors, diagnostic criteria and treatment of MAFLD were summarized in this review in order to enlighten the clinical practice and scientific research of MAFLD.
Taiyi Output:
代谢相关脂肪肝病(Metabolic Associated Fatty Liver Disease,MAFLD)又称非酒精性脂肪性肝病(Non Alcoholic Fatty Liver Disease,NAFLD),是目前全球最为流行的慢性肝病之一。近年来,关于该病的的流行病学和危险因素的探索性研究颇多。随着MAFLD对医疗和经济的负担日益加重,其药物治疗已成为研究的热点。基于此,本文对该病的流行病学现状、危险因素、诊断标准和治疗进行了总结,以期为临床实践和科学研究提供参考。
Task Introduction
Title generation aims to generate informative article titles for input biomedical text paragraphs with summarization.
Examples
Example in Chinese
User Input:
请给下面摘要起标题:
气管食管瘘是指气管或支气管与食管之间的病理性瘘道,包括气管-食管瘘和支气管-食管瘘,临床以气管-食管瘘较多见。气管食管瘘致病原因较多,可引起严重的并发症,是对患者生活质量影响显著、治疗困难和病死率较高的疾病。气管食管瘘目前治疗方式较多,但多数疗效欠佳,对新兴治疗手段的需求迫切。胸腹部X线摄影检出鼻胃管滞留是气管食管瘘诊断的金标准,其主要治疗方法包括外科手术治疗、支架置入、局部生物胶水封闭、干细胞治疗等。本文综述近年气管食管瘘诊断与治疗的主要研究进展,旨在为该病的临床诊治提供参考。
Taiyi Output:
气管食管瘘诊断与治疗进展
Example in English
User Input:
Output a title for the following abstract:
The incidence of diabetes mellitus has been increasing, prompting the search for non-invasive diagnostic methods. Although current methods exist, these have certain limitations, such as low reliability and accuracy, difficulty in individual patient adjustment, and discomfort during use. This paper presents a novel approach for diagnosing diabetes using high-frequency ultrasound (HFU) and a convolutional neural network (CNN). This method is based on the observation that glucose in red blood cells (RBCs) forms glycated hemoglobin (HbA1c) and accumulates on its surface. The study incubated RBCs with different glucose concentrations, collected acoustic reflection signals from them using a custom-designed 90-MHz transducer, and analyzed the signals using a CNN. The CNN was applied to the frequency spectra and spectrograms of the signal to identify correlations between changes in RBC properties owing to glucose concentration and signal features. The results confirmed the efficacy of the CNN-based approach with a classification accuracy of 0.98. This non-invasive diagnostic technology using HFU and CNN holds promise for in vivo diagnosis without the need for blood collection.
Taiyi Output:
A novel approach for diagnosing diabetes using high-frequency ultrasound and a convolutional neural network
Task Introduction
Biomedical text classification aims to automatically categorize biomedical texts into predefined class labels, aiding healthcare professionals, researchers, and institutions in better managing and analyzing medical information.
Examples
Example in Chinese
User Input:
现有以下文本:
治皮肤病费用大概多少?
请将上述文本分类至指定类别中:医疗费用,后果表述,指标解读,病情诊断,就医建议,疾病描述,其他,治疗方案,病因分析,功效作用,注意事项
Taiyi Output:
上述文本被分类为:医疗费用
Example in English
User Input:
Document triage: "Will my mask from sherwin williams paint store with filters protect me from corona virus along with paint fumes?"
Labels: patient, doctor
Taiyi Output:
Result: patient
Task Introduction
Text Semantic Similarity aims to determine the degree of association or similarity between two medical texts. This task typically involves text matching, similarity measurement, and semantic understanding and can be used in various applications such as medical information retrieval and document matching.
Examples
Example in Chinese
User Input:
语句1:乙肝小二阳会转成小三阳吗?
语句2:乙肝小三阳会不会转成肝硬化、肝癌?
请从下面选项中评估这段文本的语义相似度:语义不相同,语义相同
Taiyi Output:
语义不相同
Example in English
User Input:
1. How can someone's happiness level affect someone's health?
2. Can staying happy improve my health? What specific steps should I take?
Assess the semantic similarity of the text pairs based on the following labels: dissimilar, similar
Taiyi Output:
similar
To fully leverage existing biomedical natural language processing datasets, this project collected a total of 170 open-source datasets in both Chinese and English. Among these, there are 38 Chinese datasets covering 10 BioNLP tasks and 131 English datasets covering 12 BioNLP tasks. An overview of the datasets is provided in the following figure.
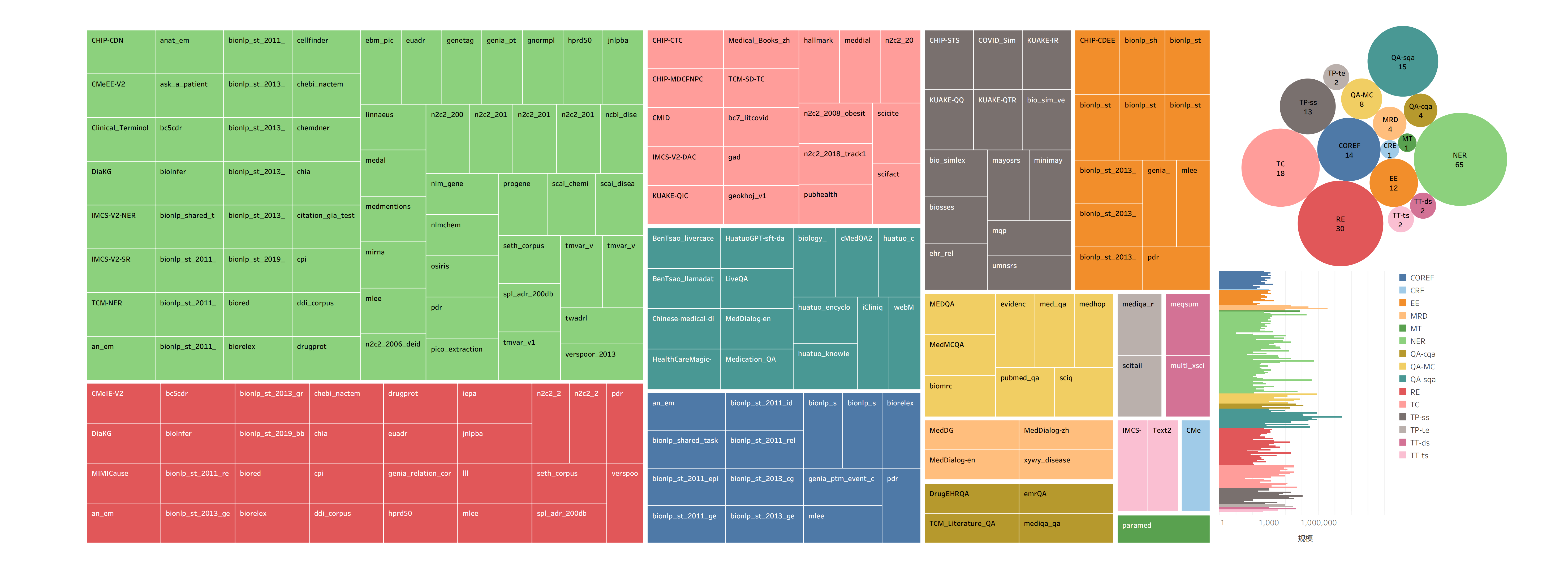
This project compiled information on each dataset, including task type, data scale, task description, and relevant data links. For specific details, please refer to the "Overview of the Biomedical Datasets".
To facilitate subsequent data conversion, this project drew inspiration from the BigBio project and, based on the type of tasks, devised a unified data format. For specific details about this standardized data format, please refer to the "DUTIR-BioNLP Data Schema Documentation", and the data has been transformed to adhere to this standardized format.
After filtering and selecting datasets based on data quality, instructional templates were designed based on the PromptCBLUE Project and data was transformed according to the standardized data format. The summary of the instruction-tuning data is presented in the following table:
| Task Type | Chinese Data Scale | English Data Scale |
|---|---|---|
| Named Entity Recognition | 44,667 | 28,603 |
| Relation Extraction | 26,606 | 17,279 |
| Event Extraction | 2,992 | 2,022 |
| Text Classification | 37,624 | 40,339 |
| Text Pair Task | 45,548 | 11,237 |
| Machine Translation | 74,113 | |
| Single-turn Question and Answer | 129,562 | 57,962 |
| Multi-Round Dialogue | 16,391 | 10,000 |
| Other Additional Tasks | 9,370 | |
| General Dialogue Data | 560,000 | |
| Total | 1,114,315 | |
For detailed information on the instructional data used for training, please refer to the "Instruction-Tuning Data Details".
The current version of Taiyi is based on the Qwen-7B-base model, which has been fine-tuned through Instruct-tuning. Qwen-7B is a 7 billion-parameter model in the Alibaba Cloud's Qwen large model series. It has been pre-trained on over 200 trillion tokens, encompassing high-quality data in Chinese, English, multiple languages, code, mathematics, and more. The training corpus covers both general and specialized domains.
We conducted instruction-guided fine-tuning using Qlora on 6 Nvidia A40 48 GB GPUs. Our training code was modified based on project Firefly. The key hyperparameters used in the training process are as follows:
num_train_epochs:3
per_device_train_batch_size:12
gradient_accumulation_steps:2
learning_rate:0.0002
max_seq_length:1024
lr_scheduler_type:"constant_with_warmup"
warmup_ratio:0.1
lora_rank:64
lora_alpha:16
lora_dropout:0.05
weight_decay:0
max_grad_norm:0.3
Our training dataset consists of approximately 1 million training samples. Each epoch of training takes approximately two days to complete.
The environment configuration we used for training and testing is as follows:
torch==1.13.0
accelerate==0.21.0
transformers==4.30.2
peft==0.4.0
bitsandbytes==0.39.0
loguru==0.7.0
numpy
pandas==1.2.5
tqdm==4.62.3
deepspeed==0.9.5
tensorboard
sentencepiece
transformers_stream_generator
tiktoken
einops
scipy
To install all dependencies automatically using the command:
$ pip install -r requirements.txt
We concatenate multi-turn dialogues into the following format, and then tokenize them. Where eod is the special character <|endoftext|> in the qwen tokenizer.
<eod>input1<eod>answer1<eod>input2<eod>answer2<eod>.....
The following code can be used to perform inference using our model:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "DUTIR-BioNLP/Taiyi-LLM"
device = 'cuda:0'
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map = device
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True
)
import logging
logging.disable(logging.WARNING)
tokenizer.pad_token_id = tokenizer.eod_id
tokenizer.bos_token_id = tokenizer.eod_id
tokenizer.eos_token_id = tokenizer.eod_id
history_token_ids = torch.tensor([[]], dtype=torch.long)
max_new_tokens = 500
top_p = 0.9
temperature = 0.3
repetition_penalty = 1.0
# begin chat
history_max_len = 1000
utterance_id = 0
history_token_ids = None
user_input = "Hi,could you please introduce yourself?"
input_ids = tokenizer(user_input, return_tensors="pt", add_special_tokens=False).input_ids
bos_token_id = torch.tensor([[tokenizer.bos_token_id]], dtype=torch.long)
eos_token_id = torch.tensor([[tokenizer.eos_token_id]], dtype=torch.long)
user_input_ids = torch.concat([bos_token_id,input_ids, eos_token_id], dim=1)
model_input_ids = user_input_ids.to(device)
with torch.no_grad():
outputs = model.generate(
input_ids=model_input_ids, max_new_tokens=max_new_tokens, do_sample=True, top_p=top_p,
temperature=temperature, repetition_penalty=repetition_penalty, eos_token_id=tokenizer.eos_token_id
)
response = tokenizer.batch_decode(outputs)
print(response[0])
#<|endoftext|>Hi,could you please introduce yourself?<|endoftext|>Hello! My name is Taiyi,.....<|endoftext|>We provide two test codes for dialogue. You can use the code in dialogue_one_trun.py to test single-turn QA dialogue, or use the sample code in dialogue_multi_trun.py to test multi-turn conversational QA.
Note: To ensure fast inference speed, we recommend using a 4090 GPU.
| Task Type | Dataset | Taiyi | ChatGPT3.5 | SOTA |
|---|---|---|---|---|
| NER(Micro-F1) | BC5CDR-Chem | 80.2 | 60.3 | 93.3(PubMedBERT) |
| BC5CDR-Dise | 69.1 | 51.8 | 85.6(PubMedBERT) | |
| CHEMDNER | 79.9 | 36.5 | 92.4(BioBERT) | |
| NCBIdisease | 73.1 | 50.5 | 87.8(PubMedBERT) | |
| CMeEE-dev | 65.7 | 47.0 | 74.0(CBLUE) | |
| RE(Micro-F1) | BC5CDR | 37.5 | 14.2 | 45.0(BioGPT) |
| CMeIE-dev | 43.2 | 30.6 | 54.9(CBLUE) | |
| TC(Micro-F1) | BC7LitCovid | 84.0 | 63.9 | 91.8(Bioformer) |
| HOC | 80.0 | 51.2 | 82.3(PubMedBERT) | |
| KUAKE_QIC-dev | 77.4 | 48.5 | 85.9(CBLUE) | |
| QA(Accuracy) | PubMedQA | 54.4 | 76.5 | 55.8(PubMedBERT) |
| MedQA-USMLE | 37.1 | 51.3 | 36.7(BioBERT-large) | |
| MedQA-MCMLE | 64.8 | 58.2 | 70.1(RoBERTA-large) | |
| ALL | AVE | 64.8 | 49.3 | 73.5 |
Limitations
The goal of this project is to explore the Chinese English bilingual natural language processing capabilities of the large model in the biomedical field. However, there are some shortcomings that must be considered in Taiyi model at present:
-
Misunderstanding: Like all major language models, there is a risk of misunderstanding or misinterpretation, especially when dealing with specialized terminology or complex concepts in the biomedical field. In this case, our model may provide inaccurate answers or explanations.
-
Hallucinations: Large language models sometimes generate meaningless or completely unrelated responses to a given input. This' hallucination 'may be particularly problematic when users are unfamiliar with the discussion topic, as they may not be able to easily identify errors in the model output.
-
Limited information: Despite our commitment to becoming a comprehensive language model in the biomedical field, the knowledge of the model is still limited and may not cover all aspects of each field or profession. Users should be aware that the information in the model may not be comprehensive and use it with caution when in-depth or professional knowledge is needed.
-
Bias: The training data of the model may contain biases, which may be reflected in the model's response. We strive to reduce bias, but we cannot completely eliminate it. Users should handle potential bias issues in model responses with caution.
-
Limited long multi-turn conversational ability: Due to the current computational constraints of our team, the max token length we could set during training was 1024. Therefore, our current model is most competitive in relatively short conversations (around 5 turns).
-
Limited topic switching ability: Due to current constraints on information and computational resources, our model may exhibit instability in multi-turn conversations covering multiple topics with large spans. Therefore, when conversing with Taiyi, users should try to maintain consistency in the dialogue topic.
Note: The Taiyi model is intended to provide information and knowledge, but should not be used as a substitute for medical professionals' advice or diagnosis. Any decision involving personal health should be consulted with professional medical personnel.
Future Work
-
Open source data and technical manuscripts: Organize and improve data resources and model training technical manuscripts, and will be released as open source in the future.
-
Continuing pretraining: Due to current computing resource limitations, the current version of Taiyi mainly performs instruction data fine-tuning and does not use massive biomedical resources to continue pretraining. In the future, this project will explore the use of large model bases in the biomedical field resources to futher pretraining.
-
Reinforcement learning enhances performance: This project will explore how to further enhance the performance of models and align human intentions using reinforcement learning methods.
-
Enhanced interpretability: Compared to the general field, the biomedical field requires higher interpretability of model prediction results. In the future, we will explore the interpretability methods of Taiyi on various BioNLP tasks.
-
Enhanced security: Although security data has been added for training in this project, model security in the biomedical field is still insufficient. We will continue to explore how to use biomedical knowledge bases to enhance model security.
-
......
Taiyi was developed by the Dalian University of Technology Information Retrieval Research Laboratory(DUTIR)
Supervisors: Ling Luo, Zhihao Yang, Jian Wang, Yuanyuan Sun, Hongfei Lin
Student Members: Jinzhong Ning, Yingwen Zhao, Zeyuan Ding, Peng Chen, Weiru Fu, Qinyu Han, Guangtao Xu, Yunzhi Qiu, Dinghao Pan, Jiru Li, Zhijun Wang, Hao Li, Wenduo Feng, Senbo Tu, Yuqi Liu
The work of this project has been inspired and assisted by the following open-source projects and technologies. We would like to express our gratitude to the developers and contributors of these projects, including but not limited to:
- Qwen: https://github.com/QwenLM/Qwen
- Firefly: https://github.com/yangjianxin1/Firefly
- BigBIO: https://github.com/bigscience-workshop/biomedical
- PromptCBLUE: https://github.com/michael-wzhu/PromptCBLUE
- The Taiyi logo was synthesized by ERNIE Bot
The resources related to this project are for academic research purposes only and are strictly prohibited from commercial use. The use of the source code of this warehouse follows the open source license agreement Apache 2.0. During use, users are required to carefully read and comply with the following statements:
- Please ensure that the content you input does not infringe on the rights and interests of others, does not involve harmful information, and does not contain any content related to politics, violence, or pornography, and all input content is legal and compliant.
- Please confirm and be aware that all content generated using the Taiyi model is generated by artificial intelligence models, and the generated content is not entirely rational. This project does not guarantee the accuracy, completeness, and functionality of the generated content, nor assumes any legal responsibility.
- Any responses that violate laws, regulations, public order, or good customs in this model do not represent the attitude, viewpoint, or stance of this project. This project will continuously improve the model responses to make them more in line with social ethics and moral norms.
- For any content output by the model, the user shall bear their own risks and responsibilities. This project does not assume any legal responsibility, nor shall they be liable for any losses that may arise from the use of relevant resources and output results.
- The third-party links or libraries appearing in this project are for convenience only, and their content and viewpoints are not related to this project. Users need to distinguish themselves when using, and this project does not assume any joint liability;
- If users discover any significant errors in the project, please provide feedback to us to help us fix them in a timely manner.
By using this project, you have carefully read, understood, and agreed to abide by the above disclaimer. This project reserves the right to modify this statement without prior notice to anyone.
If you use the repository of this project, please cite it.
@article{Taiyi,
title="{Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks}",
author={Ling Luo, Jinzhong Ning, Yingwen Zhao, Zhijun Wang, Zeyuan Ding, Peng Chen, Weiru Fu, Qinyu Han, Guangtao Xu, Yunzhi Qiu, Dinghao Pan, Jiru Li, Hao Li, Wenduo Feng, Senbo Tu, Yuqi Liu, Zhihao Yang, Jian Wang, Yuanyuan Sun, Hongfei Lin},
journal={Journal of the American Medical Informatics Association},
year={2024},
doi = {10.1093/jamia/ocae037},
url = {https://doi.org/10.1093/jamia/ocae037},
}