[ English | 中文 ]
![]()
🤗 Hugging Face | 🤖 ModelScope | 🖥️ Demo | 📃Data | paper | WeChat (微信) | Wisemodel
项目背景
随着深度学习技术的迅速发展,类ChatGPT这样的大语言模型在自然语言处理领域已经取得了显著的进展。面向生物医学领域,大语言模型有助于医生与患者之间的沟通,提供有用的医学信息,并在辅助诊疗、生物医学知识发现、药物研发、个性化医疗方案等方面具有巨大潜力。然而,在人工智能社区中,已有的开源生物医学大模型相对较少,且大多主要专注于单语(中文或英语)的医疗问答对话。因此,本项目开展了面向生物医学领域大模型的研究,并发布初版中英双语生物医学大模型——太一(Taiyi),旨在探索大模型在生物医学领域中双语自然语言处理多任务的能力。
更新
- 2024/03/01 太一论文在JAMIA期刊上线,论文地址:https://doi.org/10.1093/jamia/ocae037
- 2024/01/05 开源原始的指令数据集(Taiyi_Instruction_Data_001)。数据大部分遵循 CC BY-NC-SA 4.0协议,若原始数据集任务有其他协议的请遵循原始数据集相应协议。
- 2024/01/03 由于资源有限,demo迁移至huggingface space,采用INT8量化部署。若要体验更好效果,建议下载权重使用脚本非量化部署测试。
- 2023/10/29 CHIP2023专题论坛引导发言PPT
项目特色
- 丰富的生物医学训练资源:面向生物医学领域,本项目收集整理了丰富的中英双语生物医学自然语言处理(BioNLP)训练语料,总共包含38个中文数据集,覆盖10种BioNLP中文任务;102个英文数据集,覆盖12种BioNLP英文任务。本项目根据任务类型,设计制定任务数据统一格式,对数据集进行了统一格式转换。
- 出色的中英双语BioNLP多任务能力:通过丰富的中英双语任务指令数据(超过100W条样本)进行大模型指令微调,使模型具备了出色的中英双语生物医学智能问答、医患对话、报告生成、信息抽取、机器翻译、标题生成、文本分类等多种BioNLP能力。
- 优秀的泛化能力:除了生物医学领域,模型仍具备通用领域对话能力,并通过设计指令模板多样性,使模型具备了较优秀的指令理解能力,在同类任务的不同场景下具有较好的泛化能力,并激发了模型一定的零样本学习能力。
为了促进生物医学领域NLP发展,本项目开源了中英双语BioNLP数据集整理信息、“太一”大模型权重、模型推理使用脚本。
整体框架图

任务介绍
生物医学智能问答旨在通过问答形式帮助用户获取有关生物医学领域的答案和信息。有助于更有效地管理生物医学信息,提高医疗决策的质量,辅助生物医学教育。
样例展示
中文样例展示
用户:最近肚子总是隐隐作痛,感觉胀胀的,吃下去的东西都没法吸收,胃疼的特别厉害,偶尔伴有恶心想吐的感觉,请问是什么回事?
太一:您好,根据您的描述,您可能患有胃炎。胃炎是一种常见的胃部疾病,其症状包括胃部不适、胀气、恶心、呕吐等。建议您尽快就医,医生会根据您的症状进行检查,然后开出相应的药物治疗方案。同时,您也可以注意饮食,避免辛辣、油腻、刺激性食物,多吃易消化的食物,保持良好的饮食习惯和作息规律。如果症状加重或持续时间较长,建议及时就医。希望您早日康复。
英文样例展示
用户:Can Dexilant interfere with sleep?
太一:Dexilant (Dexlansoprazole) is a is a proton pump inhibitor that is used to treat gastroesophageal reflux disease (GERD) and other conditions. It is generally safe to take Dexilant before bedtime, but it may cause some people to have trouble sleeping. If you experience difficulty sleeping after taking Dexilant, you should talk to your doctor. They may suggest taking the Dexilant at a different time of day or switching to a different medication.
任务介绍
太一大模型可模拟生物医学专家与患者进行自然语言对话。这种对话可以涵盖病情咨询、疾病预防、药物咨询等多种生物医学主题。
样例展示
中文样例展示
用户:什么是鼠疫?
太一:鼠疫是由鼠疫杆菌引起的传染病,鼠疫杆菌是一种细菌,通常通过跳蚤叮咬传播。鼠疫杆菌主要存在于啮齿类动物的,如老鼠、土拨鼠等,当这些动物被感染后,它们会通过跳蚤叮咬传播给其他动物,包括人类。鼠疫杆菌主要通过跳蚤叮咬传播,也可以通过直接接触感染。
用户:它有什么预防方法吗?
太一:
预防鼠疫的方法包括以下几点:
避免接触感染源:尽量避免接触啮齿类动物,如老鼠、土拨鼠等,特别是在疫区或疫区附近。
保持个人卫生:勤洗手,保持身体清洁,避免接触感染源。
食用安全食品:在疫区或疫区附近,尽量避免食用未经煮熟的肉类、蛋类等食品。
做好防护措施:在疫区或疫区附近,佩戴口罩、手套等防护用品,避免直接接触感染源。
接种疫苗:在疫区或疫区附近,可以接种鼠疫疫苗,增强免疫力,预防感染。
用户:鼠疫常发生在哪些国家?
太一:鼠疫是一种全球性传染病,主要分布在温带和寒带地区。目前,鼠疫主要分布在亚洲、非洲和欧洲等地区。其中,亚洲地区是鼠疫的主要流行区,包括中国、蒙古、俄罗斯、朝鲜、韩国、日本等国家。非洲地区是鼠疫的高发区,包括非洲中部、南部、东部等地区。欧洲地区是鼠疫的高发区,包括欧洲中部、北部、东部等地区。
英文样例展示
用户:Do you know colchicine?
太一:Colchicine is a medication used to treat gout, a type of arthritis that causes joint pain, swelling, and redness. It works by reducing the amount of uric acid in the body.
用户:Does it have any potential side effects?
太一:Yes, Colchicine can have potential side effects. Some of the common side effects of Colchicine include nausea, vomiting, diarrhea, abdominal pain, and loss of appetite. However, there are also some rare but serious side effects of Colchicine, such as muscle weakness, confusion, and difficulty breathing. If you experience any of these side effects, you should seek medical attention immediately.
任务介绍
医疗报告自动生成旨在对问诊过程中进行信息的总结,依据病人自述和医患对话, 生成具有规定格式的医疗报告。这项任务可以帮助医生更有效地处理大量的医疗信息,并为患者提供准确的诊断和治疗建议。
样例展示
样例展示
用户输入:
问诊对话历史:
患者:小孩受凉了,流清鼻涕,咳嗽,应该是风寒咳嗽,去药店买哪种药好呢
医生:你好,宝宝咳嗽,流涕比较常见,西医角度上呼吸道感染可能性大,中医上叫做风寒咳嗽,请问宝宝除了咳嗽有没有其他不适症状呢?例如发热等,请详细描述一下,我好帮你诊治分析病情
患者:精神状态好,也没有发热,就是喉咙有一点痛,咳嗽
医生:先帮你分析一下病情,宝宝受凉之后免疫力降低,就会被细菌或病毒侵袭体内,气道分泌物增多,支气管平滑肌痉挛,咳嗽,咳痰,咽通。
医生:目前没有发热,宝宝病情不重,不用过分紧张的。
医生:我帮推荐治疗方法
医生:宝宝目前多大了?有没有再医院看过?做过化验检查
患者:嗯
患者:7岁,没去医院,做过很多检查,平常就是爱咳嗽,喉哝发炎
患者:医生说,扁桃体偏大
医生:近期这次有没有去医院看过?做过检查
医生:如果宝宝没有其他不适?可以口服氨溴索,桔贝合剂效果好
医生:另外如果条件允许,可以做做雾化吸入治疗直接作用与支气管粘膜,效果更直接
患者:不用做雾化吧,吃点药就行了
医生:也可以先吃药
患者:近期没有去过
医生:你们这次没有去医院看过?
患者:要吃消炎的吗
患者:没
患者:要吃消炎药吗
医生:你好,可以先不吃的
患者:那家里有蒲地蓝,可以吃吗
患者:口服液
患者:喉哝痛要吃吗
医生:先治疗看看,可以吃的,假如宝宝出现发热或咳嗽加重,医院就诊,复查血常规和胸片,那个时候再考虑加抗生素
患者:另外买个止咳的,行吗
医生:我们的观点是宝宝小,尽量少吃消炎药,可以先吃那几个药三天看看效果
患者:嗯谢谢
根据上述对话,给出诊疗报告
说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节。
太一输出:
上述问诊对话的诊疗报告如下:
主诉:咳嗽、流涕。
现病史:患儿无明显诱因下出现咳嗽、流涕,无恶心呕吐,无其他明显不适症状。精神状态一般,胃纳一般,余如常。
辅助检查:暂无。
既往史:既往体健。
诊断:小儿咳嗽。
建议:口服氨溴索、桔贝合剂,密观。
任务介绍
生物医学命名实体识别旨在从文本中识别出预定义的生物医学实体。这些实体可以包括疾病、药物、基因、蛋白质等生物医学概念。
样例展示
中文样例展示
用户输入:
从下面文本中识别出指定的实体类型:
治疗以选用大环内酯类抗生素,沙眼衣原体肺炎也可用磺胺二甲基异唑,年长儿和成人用氟喹诺酮类效果也很好。
实体类型:疾病,药物
太一输出:
上述文本中包含的疾病为:沙眼衣原体肺炎
上述文本中包含的药物为:大环内酯类抗生素; 磺胺二甲基异唑; 氟喹诺酮类
英文样例展示
用户输入:
Extract the gene and disease entities from the following text:
Identification of a novel FBN1 gene mutation in a Chinese family with Marfan syndrome.
太一输出:
gene: FBN1
disease: Marfan syndrome
任务介绍
生物医学关系抽取旨在从文本中自动提取出生物医学实体对之间的预定义关系,例如蛋白质与基因之间的相互作用、药物与疾病之间的治疗关系等。
样例展示
中文样例展示
用户输入:
给出句子中药物治疗关系类型的实体对:慢性阻塞性肺疾病@减少急性加重:有高质量的证据证实,β2 受体激动剂在减少 12-52 周急性加重方面比安慰剂更有效。
太一输出:
具有药物治疗关系的实体对如下:[慢性阻塞性肺疾病, β2 受体激动剂]
英文样例展示
用户输入:
Find the relations of drug entity pairs in the text:
Mitotane has been reported to accelerate the metabolism of warfarin by the mechanism of hepatic microsomal enzyme induction, leading to an increase in dosage requirements for warfarin. Therefore, physicians should closely monitor patients for a change in anticoagulant dosage requirements when administering Mitotane to patients on coumarin-type anticoagulants. In addition, Mitotane should be given with caution to patients receiving other drugs susceptible to the influence of hepatic enzyme induction.
Relation Types: ADVISE, MECHANISM, EFFECT, INT
太一输出:
ADVISE: [Mitotane, coumarin-type anticoagulants]
MECHANISM: [Mitotane, warfarin]
任务介绍
生物医学事件抽取任务的目标是从非结构化的海量生物医学文献中抽取结构化的生物医学事件,挖掘文献中所描述的生物实体,以及生物医学事件之间的细粒度关系。这项任务可以节约人工查阅文献的时间,为相关数据库的构建、疾病的诊断和预防等研究提供支持。
样例展示
中文样例展示
用户输入:
找出指定的临床发现事件属性:
因患者需期末考试,故予以口服“雷贝拉唑钠肠溶片”治疗,现腹痛情况明显好转。
事件抽取说明:临床发现事件由主体词,发生状态,描述词和解剖部位组成
太一输出:
上述句子中的临床发现事件如下:
主体词:疼痛;发生状态:;描述词:明显好转;解剖部位:腹
英文样例展示
用户输入:
Input text: "Contaminated drinking water is responsible for causing diarrheal diseases that kill millions of people a year. Additionally, toxin-producing blue-green algae associated with diarrhea and neurologic effects continues to be an issue for many drinking water supplies.
Even Types: Treatment of disease, Cause of disease
Role Types: Cause, Theme
Please extract events from the input text.
太一输出:
Cause of disease: (Trigger: responsible, Theme: diarrheal diseases, Cause: Contaminated drinking water]
任务介绍
机器翻译可将生物医学文本从一种自然语言转换成另一种自然语言。该任务可以帮助人们将各种医疗问题与建议、疾病名称与症状等信息进行中英文互译。
样例展示
中译英样例展示
用户输入:
将下面文本翻译成英文:
光动力疗法(PDT)作为一种新兴的肿瘤治疗手段,因其不良反应较少、靶向性好、可重复治疗等优点,已广泛应用于临床多种肿瘤的治疗。相比于手术、化疗及放疗等传统治疗策略,光动力疗法不仅可杀伤原位肿瘤,还可通过激活机体的免疫效应对转移瘤发挥抑制作用。然而,PDT诱导免疫效应的高低受多种因素影响,包括光敏剂在细胞内的定位和剂量、光参数、肿瘤内的氧浓度、免疫功能的完整性等。本文针对PDT介导抗肿瘤免疫效应的相关机制,以及PDT免疫效应的主要影响因素进行综述,以探讨PDT用于肿瘤治疗的未来发展方向。
太一输出:
As a new tumor treatment method, photodynamic therapy (pdt) has been widely used in clinical practice because of its advantages of few side effects, good targeting, and repeatability. Compared with traditional treatment strategies, such as surgery, chemotherapy, and radiotherapy, pdt can not only kill the primary tumor, but also inhibit the metastatic tumor by activating the body's immune effect. However, the induction of immune effect by pdt is affected by many factors, including the localization and dose of photosensitizers in cells, light parameters, oxygen concentration in tumor, and the integrity of immune function. In this review, we focus on themechanisms of antitumor immune effect mediated by pdt, and the main influencing factors of immune effect of pdt, to discuss the future development direction of pdt in thetumor treatment.
英译中样例展示
用户输入:
Translate the following text into Chinese:
Metabolic-associated fatty liver disease (MAFLD), formerly known as non-alcoholic fatty liver disease (NAFLD), is one of the most popular chronic liver diseases in the world. There are many explorations on the epidemiology and risk factors of the disease published in recent years. With the increasing burden of MAFLD on medical care and social economy, drug treatment of MAFLD has become an urgent research hotspot. Based on this, the current epidemiological status, risk factors, diagnostic criteria and treatment of MAFLD were summarized in this review in order to enlighten the clinical practice and scientific research of MAFLD.
太一输出:
代谢相关脂肪肝病(Metabolic Associated Fatty Liver Disease,MAFLD)又称非酒精性脂肪性肝病(Non Alcoholic Fatty Liver Disease,NAFLD),是目前全球最为流行的慢性肝病之一。近年来,关于该病的的流行病学和危险因素的探索性研究颇多。随着MAFLD对医疗和经济的负担日益加重,其药物治疗已成为研究的热点。基于此,本文对该病的流行病学现状、危险因素、诊断标准和治疗进行了总结,以期为临床实践和科学研究提供参考。
任务介绍
标题生成旨在对输入的生物医学文本段落,生成对具有概括性的文章标题。
样例展示
中文样例展示
用户输入:
请给下面摘要起标题:
气管食管瘘是指气管或支气管与食管之间的病理性瘘道,包括气管-食管瘘和支气管-食管瘘,临床以气管-食管瘘较多见。气管食管瘘致病原因较多,可引起严重的并发症,是对患者生活质量影响显著、治疗困难和病死率较高的疾病。气管食管瘘目前治疗方式较多,但多数疗效欠佳,对新兴治疗手段的需求迫切。胸腹部X线摄影检出鼻胃管滞留是气管食管瘘诊断的金标准,其主要治疗方法包括外科手术治疗、支架置入、局部生物胶水封闭、干细胞治疗等。本文综述近年气管食管瘘诊断与治疗的主要研究进展,旨在为该病的临床诊治提供参考。
太一输出:
气管食管瘘诊断与治疗进展
英文样例展示
用户输入:
Provide a title for the abstract:
The incidence of diabetes mellitus has been increasing, prompting the search for non-invasive diagnostic methods. Although current methods exist, these have certain limitations, such as low reliability and accuracy, difficulty in individual patient adjustment, and discomfort during use. This paper presents a novel approach for diagnosing diabetes using high-frequency ultrasound (HFU) and a convolutional neural network (CNN). This method is based on the observation that glucose in red blood cells (RBCs) forms glycated hemoglobin (HbA1c) and accumulates on its surface. The study incubated RBCs with different glucose concentrations, collected acoustic reflection signals from them using a custom-designed 90-MHz transducer, and analyzed the signals using a CNN. The CNN was applied to the frequency spectra and spectrograms of the signal to identify correlations between changes in RBC properties owing to glucose concentration and signal features. The results confirmed the efficacy of the CNN-based approach with a classification accuracy of 0.98. This non-invasive diagnostic technology using HFU and CNN holds promise for in vivo diagnosis without the need for blood collection.
太一输出:
A novel approach for diagnosing diabetes using high-frequency ultrasound and a convolutional neural network
任务介绍
生物医学文本分类旨在将生物医学文本自动分类到预定义的类别标签中,以帮助医疗专业人员、研究人员和机构更好地管理和分析医疗信息。
样例展示
中文样例展示
用户输入:
现有以下文本:
治皮肤病费用大概多少?
请将上述文本分类至指定类别中:医疗费用,后果表述,指标解读,病情诊断,就医建议,疾病描述,其他,治疗方案,病因分析,功效作用,注意事项
太一输出:
上述文本被分类为:医疗费用
英文样例展示
用户输入:
Document triage: "Will my mask from sherwin williams paint store with filters protect me from corona virus along with paint fumes?"
Labels: patient, doctor
太一输出:
Result: patient
任务介绍
文本相关性判断旨在确定两段医疗文本之间的关联程度或相似性。这种任务通常涉及文本匹配、相似性度量和语义理解,可用于各种应用,如医疗信息检索、文档匹配。
样例展示
中文样例展示
用户输入:
语句1:乙肝小二阳会转成小三阳吗?
语句2:乙肝小三阳会不会转成肝硬化、肝癌?
请从下面选项中评估这段文本的语义相似度:语义不相同,语义相同
太一输出:
语义不相同
英文样例展示
用户输入:
1. How can someone's happiness level affect someone's health?
2. Can staying happy improve my health? What specific steps should I take?
Assess the semantic similarity of the text pairs based on the following labels: dissimilar, similar
太一输出:
similar
为了充分利用现存生物医学自然语言处理数据集,本项目收集了现存开源现存140个中英双语数据集,其中中文数据集38个,覆盖10种BioNLP任务;英文数据集102个,覆盖12种BioNLP任务,数据集总览图如下图所示。
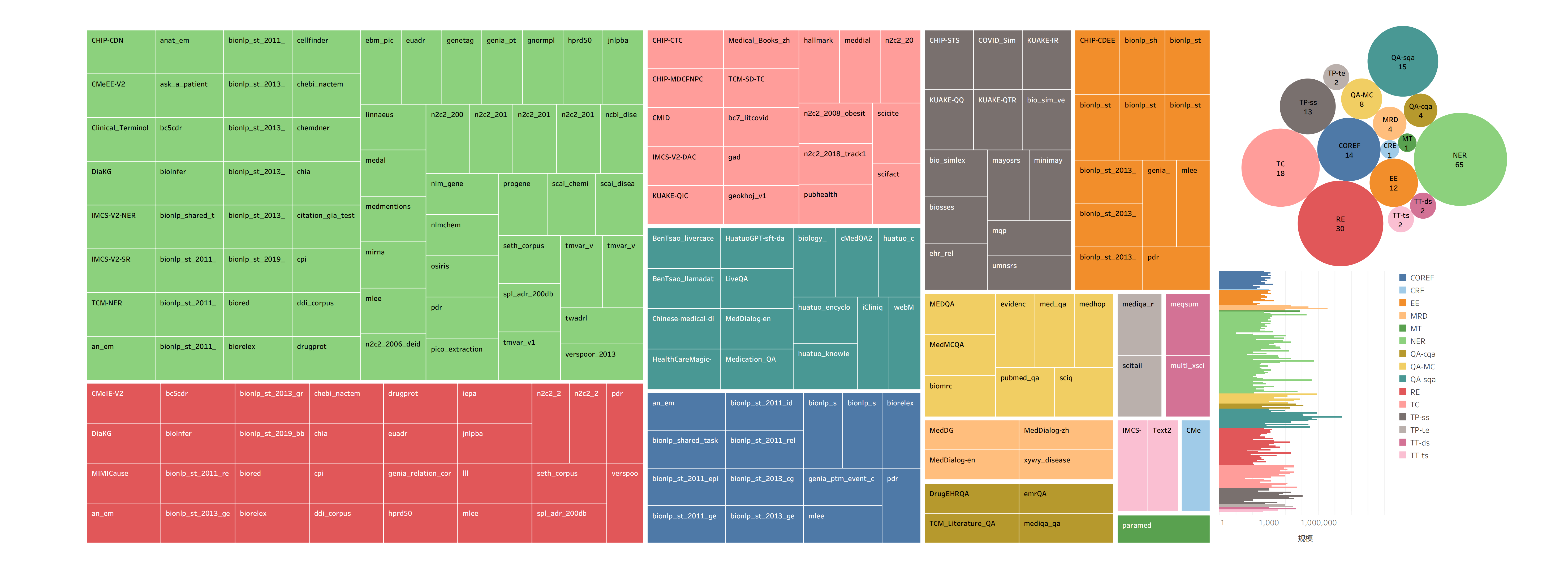
本项目整理了每个数据集的任务类型、数据规模、任务简介和数据相关链接,具体信息见《数据总表》。
为了后续进行指令数据转换,本项目借鉴了BigBio项目,在其基础上根据任务类型设计制定了数据的统一格式,具体数据统一格式见《DUTIR BioNLP数据统一格式》,并将数据处理成制定的统一格式。
根据数据集质量筛选和过滤后,在数据统一格式基础上,借鉴PromptCBLUE项目设计了多种指令模板并进行指令数据转换。此外,为了保留通用领域的对话能力和增强模型的推理能力,本项目还加入了通用领域的对话,最终用于大模型训练的指令数据简表统计如下表:
| 任务类型 | 中文数据规模 | 英文数据规模 |
|---|---|---|
| 命名实体识别 | 44,667 | 28,603 |
| 关系抽取 | 26,606 | 17,279 |
| 事件抽取 | 2,992 | 2,022 |
| 文本分类 | 37,624 | 40,339 |
| 文本对任务 | 45,548 | 11,237 |
| 机器翻译 | 74,113 | |
| 单轮问答 | 129,562 | 57,962 |
| 多轮对话 | 16,391 | 10,000 |
| 其他额外任务 | 9,370 | |
| 通用对话数据 | 560,000 | |
| 总计 | 1,114,315 | |
训练用到的最终指令数据详细信息请见《指令数据表》。
当前版本的太一是基于Qwen-7B-base通过指令微调得到。通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模的模型,在超过2万亿tokens数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。
本项目在6张Nvidia A40 48 GB显卡上使用Qlora进行指令微调测试。训练代码在 Firefly 项目的基础上进行了修改。其中的主要超参数设置如下:
num_train_epochs:3
per_device_train_batch_size:12
gradient_accumulation_steps:2
earning_rate:0.0002
max_seq_length:1024
lr_scheduler_type:"constant_with_warmup"
warmup_ratio:0.1
lora_rank:64
lora_alpha:16
lora_dropout:0.05
weight_decay:0
max_grad_norm:0.3
项目训练集包含约100w条训练样本,每个epoch的训练时间约为两天。
本项目训练和测试使用的环境配置如下:
torch==1.13.0
accelerate==0.21.0
transformers==4.30.2
peft==0.4.0
bitsandbytes==0.39.0
loguru==0.7.0
numpy
pandas==1.2.5
tqdm==4.62.3
deepspeed==0.9.5
tensorboard
sentencepiece
transformers_stream_generator
tiktoken
einops
scipy
可使用如下命令按照环境包:
$ pip install -r requirements.txt
本项目将多轮对话拼接成如下格式,然后进行tokenize。其中eod为qwen tokenizer中的特殊字符<|endoftext|>
<eod>input1<eod>answer1<eod>input2<eod>answer2<eod>.....
可使用如下代码完成使用我们的模型完成推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "DUTIR-BioNLP/Taiyi-LLM"
device = 'cuda:0'
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map = device
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True
)
import logging
logging.disable(logging.WARNING)
tokenizer.pad_token_id = tokenizer.eod_id
tokenizer.bos_token_id = tokenizer.eod_id
tokenizer.eos_token_id = tokenizer.eod_id
history_token_ids = torch.tensor([[]], dtype=torch.long)
max_new_tokens = 500
top_p = 0.9
temperature = 0.3
repetition_penalty = 1.0
# 开始对话
history_max_len = 1000
utterance_id = 0
history_token_ids = None
user_input = "你好,请问你是谁?"
input_ids = tokenizer(user_input, return_tensors="pt", add_special_tokens=False).input_ids
bos_token_id = torch.tensor([[tokenizer.bos_token_id]], dtype=torch.long)
eos_token_id = torch.tensor([[tokenizer.eos_token_id]], dtype=torch.long)
user_input_ids = torch.concat([bos_token_id,input_ids, eos_token_id], dim=1)
model_input_ids = user_input_ids.to(device)
with torch.no_grad():
outputs = model.generate(
input_ids=model_input_ids, max_new_tokens=max_new_tokens, do_sample=True, top_p=top_p,
temperature=temperature, repetition_penalty=repetition_penalty, eos_token_id=tokenizer.eos_token_id
)
response = tokenizer.batch_decode(outputs)
print(response[0])
#<|endoftext|>你好,请问你是谁?<|endoftext|>您好,我是医疗语言大模型Taiyi。<|endoftext|>本项目提供两个用于对话的测试代码。可使用dialogue_one_trun.py中的程序进行单轮问答对话测试,或者使用dialogue_multi_trun.py中的示例代码进行多轮对话问答测试。
注:为了保证推理速度,建议使用4090显卡。
| 任务类型 | 数据集 | 太一 | ChatGPT3.5 | SOTA |
|---|---|---|---|---|
| 实体识别(Micro-F1) | BC5CDR-Chem | 80.2 | 60.3 | 93.3(PubMedBERT) |
| BC5CDR-Dise | 69.1 | 51.8 | 85.6(PubMedBERT) | |
| CHEMDNER | 79.9 | 36.5 | 92.4(BioBERT) | |
| NCBIdisease | 73.1 | 50.5 | 87.8(PubMedBERT) | |
| CMeEE-dev | 65.7 | 47.0 | 74.0(CBLUE) | |
| 关系抽取(Micro-F1) | BC5CDR | 37.5 | 14.2 | 45.0(BioGPT) |
| CMeIE-dev | 43.2 | 30.6 | 54.9(CBLUE) | |
| 文本分类(Micro-F1) | BC7LitCovid | 84.0 | 63.9 | 91.8(Bioformer) |
| HOC | 80.0 | 51.2 | 82.3(PubMedBERT) | |
| KUAKE_QIC-dev | 77.4 | 48.5 | 85.9(CBLUE) | |
| 填空问答(Accuracy) | PubMedQA | 54.4 | 76.5 | 55.8(PubMedBERT) |
| MedQA-USMLE | 37.1 | 51.3 | 36.7(BioBERT-large) | |
| MedQA-MCMLE | 64.8 | 58.2 | 70.1(RoBERTA-large) | |
| 全部 | 均值AVE | 64.8 | 49.3 | 73.5 |
局限性
本项目致力探索大模型在生物医学领域的中英双语自然语言处理多任务的能力,然而,“太一”大模型仍存在大模型的一些常见缺点:
-
误解:与所有大语言模型一样,存在误解或错误解释的风险,尤其是在处理生物医学领域的专业术语或复杂概念时。在这种情况下,我们的模型可能提供不准确的答案或解释。
-
幻觉:大语言模型有时会生成毫无意义或与给定输入完全无关的回应。这种“幻觉”可能在用户不熟悉讨论主题时尤为问题,因为他们可能无法轻易识别模型输出中的错误。
-
信息有限性:尽管本项目致力于成为生物医学领域的全面语言模型,但模型的知识仍然有限,可能无法覆盖每个领域或专业的所有方面。用户应该意识到模型的信息可能不全面,并在需要深入或专业知识时谨慎使用。
-
偏见:模型的训练数据可能会包含偏见,这可能会在模型的回应中体现出来。我们努力减少偏见,但不能完全消除它。用户应该谨慎处理模型回应中的潜在偏见问题。
-
多轮长对话能力不稳定:受限于我们团队当前的算力条件,我们训练过程中的截止token长度仅能设置为1024。因此,当前我们的模型只在较短轮数(约5轮左右)的对话场景下具有较强竞争力。
-
话题转换能力弱:受限于当前信息和算力资源,我们的模型可能在包含多个跨度较大主题的多轮对话中表现出不稳定性。
注意:太一模型旨在提供信息和知识,但不应被用于替代医疗专业人员的建议或诊断。任何涉及个人健康的决策都应咨询专业医疗人员。
未来工作
-
开源数据和技术手稿:整理完善数据资源和模型训练技术手稿,也将这些资源陆续发布。
-
继续预训练:由于目前计算资源限制,当前的太一版本主要进行了指令数据微调,并未采用海量生物医学资源继续预训练,未来本项目将探索大模型基座在生物医学领域资源上继续预训练。
-
强化学习增强性能:本项目将探索如何利用基于强化学习方法来进一步增强模型的性能和对齐人类意图。
-
增强可解释性:相比通用领域,生物医学领域对模型预测结果的可解释性要求更高。未来我们将探索太一在多种BioNLP任务上的可解释性方法。
-
增强安全性:虽然目前本项目加入了安全性数据进行训练,但在生物医学领域模型安全性仍不足,我们将继续探索如何利用生物医学知识库提升模型安全性。
-
......
太一由大连理工大学信息检索研究室(DUTIR)开发完成。
指导教师:罗凌、杨志豪、王健、孙媛媛、林鸿飞
学生成员:宁金忠、赵颖闻、丁泽源、陈鹏、付伟茹、韩钦宇、徐广涛、邱云志、潘丁豪、李记如、汪志军、李浩、凤文铎、涂森博、刘宇奇
本项目的工作受到以下开源项目与技术的启发和帮助,在此对相关项目和研究开发人员表示感谢,包括但不限于:
- Qwen: https://github.com/QwenLM/Qwen
- Firefly: https://github.com/yangjianxin1/Firefly
- BigBIO: https://github.com/bigscience-workshop/biomedical
- PromptCBLUE: https://github.com/michael-wzhu/PromptCBLUE
- 太一logo 由文心一言AI合成
本项目相关资源仅供学术研究之用,严禁用于商业用途。对本仓库源码的使用遵循开源许可协议 Apache 2.0。在使用过程中,用户需认真阅读并遵守以下声明:
- 请您确保您所输入的内容未侵害他人权益,未涉及不良信息,同时未输入与政治、暴力、色情相关的内容,且所有输入内容均合法合规。
- 请您确认并知悉使用太一大模型生成的所有内容均由人工智能模型生成,生成内容具有不完全理性,本项目对其生成内容的准确性、完整性和功能性不做任何保证,亦不承担任何法律责任。
- 本模型中出现的任何违反法律法规或公序良俗的回答,均不代表本项目的态度、观点或立场,本项目将不断完善模型回答以使其更符合社会伦理和道德规范。
- 对于模型输出的任何内容,使用者需自行承担风险和责任,本项目不承担任何法律责任,亦不对因使用相关资源和输出结果而可能产生的任何损失承担责任。
- 本项目中出现的第三方链接或库仅为提供便利而存在,其内容和观点与本项目无关。使用者在使用时需自行辨别,本项目不承担任何连带责任;
- 若使用者发现项目出现任何重大错误,请向我方反馈,以助于我们及时修复。
使用本项目即表示您已经仔细阅读、理解并同意遵守以上免责声明。本项目保留在不预先通知任何人的情况下修改本声明的权利。
如果你使用到了本项目的仓库,请引用。
@article{Taiyi,
title="{Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks}",
author={Ling Luo, Jinzhong Ning, Yingwen Zhao, Zhijun Wang, Zeyuan Ding, Peng Chen, Weiru Fu, Qinyu Han, Guangtao Xu, Yunzhi Qiu, Dinghao Pan, Jiru Li, Hao Li, Wenduo Feng, Senbo Tu, Yuqi Liu, Zhihao Yang, Jian Wang, Yuanyuan Sun, Hongfei Lin},
journal={Journal of the American Medical Informatics Association},
year={2024},
doi = {10.1093/jamia/ocae037},
url = {https://doi.org/10.1093/jamia/ocae037},
}