Active learning is typically used when unlabeled data is abundant, but labels are expensive or difficult to obtain. It aims at learning an optimal model with a limited labeling budget. Proximity-based active learning utilizes the underlying structure of the unlabeled data, selecting representatives of local distributions. Some of the algorithms also takes informativeness of samples regarding an existing model. The implemented active learning alogrithms include
- Medoid-based active learning [1]
- Mismtatch-first farthest-traversal [2]
- Largest neighbourhood.
Mismatch-first farthest-traversal is designed for cases where some of the classes are rare. The original medoid-based active learning and largest neigbhourhood method is suitable for the cases that classes are generally evenly distributed.
[1] Active learning for sound event classification by clustering unlabeled data. Zhao S.Y., T. Heittola, T. Virtanen. In proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), p. 751--755, 2017. https://ieeexplore.ieee.org/document/7952256
[2] An active learning method using clustering and committee-based sample selection for sound event classification. Zhao S.Y., T. Heittola, T. Virtanen. In proc. 16th International Workshop on Acoustic Signal Enhancement (IWAENC), 2018. https://ieeexplore.ieee.org/document/8521336
git clone https://github.com/zhao-shuyang/active_learning.git
cd active_learning
python setup.py install
Three example codes using the actiev learning implementations are currently given.
- News20, a text classification dataest.
- An imaginary dataset described below. Visualization is given.
- ESC-10, a sound classification dataset. This will be added later.
python example_news20.py
python example_imaginary.py
python example_esc10.py
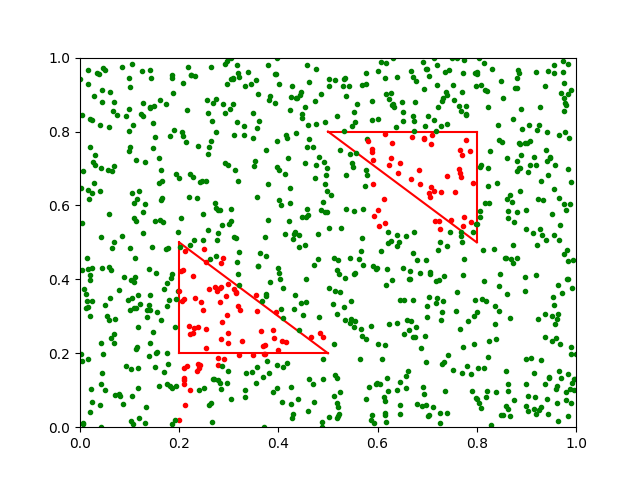
The visualization of the algorithm uses a binary classification problem, with 5000 randomly generated data points. The data points belong to two classes, visualized with green and blue. The traget decision boundaries are marked with two blue triangles. The labeling budget is 500. In each batch, 100 data points are queried for labels.

| Sample selection | Model prediction |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
It maximizes the diversity of selected samples. It does not rely on a model, simply select the farthest data point to the traversed set.

It completely relies on a model, selecting the samples with lowest prediction certainty.

It relies on both a existing model and the structure of data points. The primary criterion is prediction mismatch between model-predicted labels and nearset-neighbour predicted labels. The second criterion is the distance to the selected samples.
