基于ChatGLM-6B+LoRA在指令数据集上进行微调
本项目主要内容:
- 🚀 2023/4/9 发布了基于100万条由BELLE项目生成的中文指令数据的Lora权重,具体可见
output/belle/chatglm-lora.pt - 🚀 2023/4/8 基于deepspeed支持多卡微调,速度相比单卡提升8-9倍具体设置可见 微调3 基于DeepSpeed进行Lora微调
- 🚀 2023/3/28 开源了基于alpaca和belle数据指令微调后的lora权重,详情可见output
- 🚀 2023/3/25 针对ChatGLM-6B模型基于LoRA技术进行微调
- 🚀 2023/3/23 基于gradio的demo完善
- deepspeed支持
- 模型评估,如何评估微调后的模型效果
instruction:52K 条指令中的每一条都是唯一的,答案由text-davinci-003模型生成得到的
1百万数据:https://huggingface.co/datasets/BelleGroup/generated_train_1M_CN
生成方式基于种子prompt,调用openai的api生成中文指令
Guanaco 是在 Meta 的 LLaMA 7B 模型上训练的指令跟随语言模型。在 Alpaca 模型原始 52K 数据的基础上,我们添加了额外的 98,369 个条目,涵盖英语、简体中文、繁体中文(台湾)、繁体中文(香港)、日语、德语以及各种语言和语法任务。通过使用这些丰富的数据重新训练和优化模型,Guanaco 在多语言环境中展示了出色的性能和潜力。项目链接可以查看 https://guanaco-model.github.io/
与原始alpaca数据json格式相同,数据生成的方法是机器翻译和self-instruct
加入除了alpaca之外的其他中文聊天对话 人工微调,部分并不中文化的问题,我们将重新询问chatgpt或文心一言,重新获取回答并覆盖掉alpaca的回答
- firefly-train-1.1M , 一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。
斯坦福羊驼52k数据,原始数据格式如下:
{
"instruction": "Evaluate this sentence for spelling and grammar mistakes",
"input": "He finnished his meal and left the resturant",
"output": "He finished his meal and left the restaurant."
}
转化alpaca数据集为jsonl,这一步可以执行设置数据转换后格式,比如:
###Instruction:xxx###Input:xxxx###Response:xxx
python cover_alpaca2jsonl.py \
--data_path data/alpaca_data.json \
--save_path data/alpaca_data.jsonl 对文本进行tokenize,加快训练速度,文本长度可根据运行资源自行设置
python tokenize_dataset_rows.py \
--jsonl_path data/alpaca_data.jsonl \
--save_path data/alpaca \
--max_seq_length 320python train_lora.py \
--dataset_path data/alpaca \
--lora_rank 8 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 1 \
--max_steps 52000 \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--fp16 \
--remove_unused_columns false \
--logging_steps 50 \
--output_dir output包含543314条由BELLE项目生成的中文指令数据,数据格式如下:
| input | target |
|---|---|
| 用一句话描述地球为什么是独一无二的。\n | 地球上有适宜生命存在的条件和多样化的生命形式 |
数据集地址:https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN
转化bell数据集为jsonl
python cover_alpaca2jsonl.py \
--dataset_name BelleGroup/generated_train_0.5M_CN \
--save_path data/belle_data.jsonl 文本长度统计
count 543314.000000
mean 83.536944
std 95.665178
min 4.000000
25% 33.000000
50% 51.000000
75% 88.000000
90% 194.000000
max 4410.000000
Name: input_len, dtype: float64
count 543314.000000
mean 121.079030
std 165.472722
min 1.000000
25% 27.000000
50% 67.000000
75% 151.000000
90% 296.000000
max 9463.000000
Name: target_len, dtype: float64
分词处理
python tokenize_dataset_rows.py \
--jsonl_path data/belle_data.jsonl \
--save_path data/belle \
--max_seq_length 320转换后的数据:
input_ids seq_len
0 [20005, 92863, 20012, 20005, 83864, 87784, 871... 20
1 [20005, 92863, 20012, 20005, 91432, 86523, 885... 80
2 [20005, 92863, 20012, 104069, 85056, 86334, 89... 61
3 [20005, 92863, 20012, 91492, 89122, 83866, 852... 24
4 [20005, 92863, 20012, 20005, 83834, 99899, 927... 24
- 基于原始chatglm-6b训练
python train_lora.py \
--dataset_path data/belle \
--lora_rank 8 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 1 \
--max_steps 52000 \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--fp16 \
--remove_unused_columns false \
--logging_steps 50 \
--output_dir output- 基于alpaca的lora继续微调
python train_lora.py \
--dataset_path data/belle \
--lora_rank 8 \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 1 \
--max_steps 52000 \
--save_steps 10000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--fp16 \
--remove_unused_columns false \
--logging_steps 50 \
--output_dir output/belle \
--is_resume True \
--resume_path output/alpaca/chatglm-lora.pt支持多卡+zero方案,训练速度可提高8倍左右
accelerate launch --config_file config/default_config.yaml train_deepspeed.py- 安装所需要的包:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- 显卡:2xA100 80G
- 训练好的lora权重
└─output
├─alpaca:基于52k微调的lora权重
├─belle::基于52k微调的lora权重+belle微调的权重52000steps
└─belle_raw:belle微调的权重104000steps
链接:https://pan.baidu.com/s/1c-zRSEUn4151YLoowPN4YA?pwd=hxbr
提取码:hxbr
--来自百度网盘超级会员V3的分享
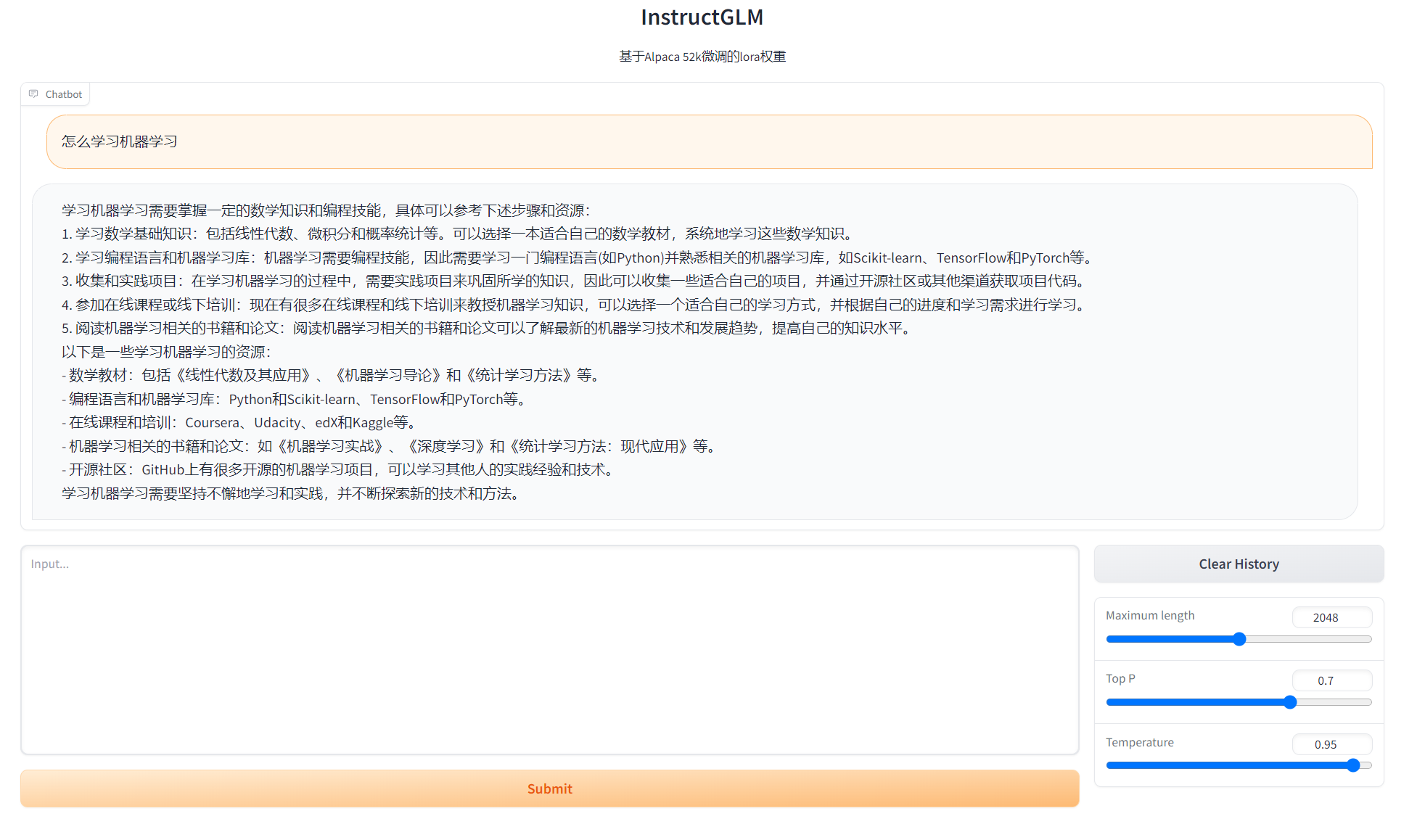
- alpaca数据微调效果
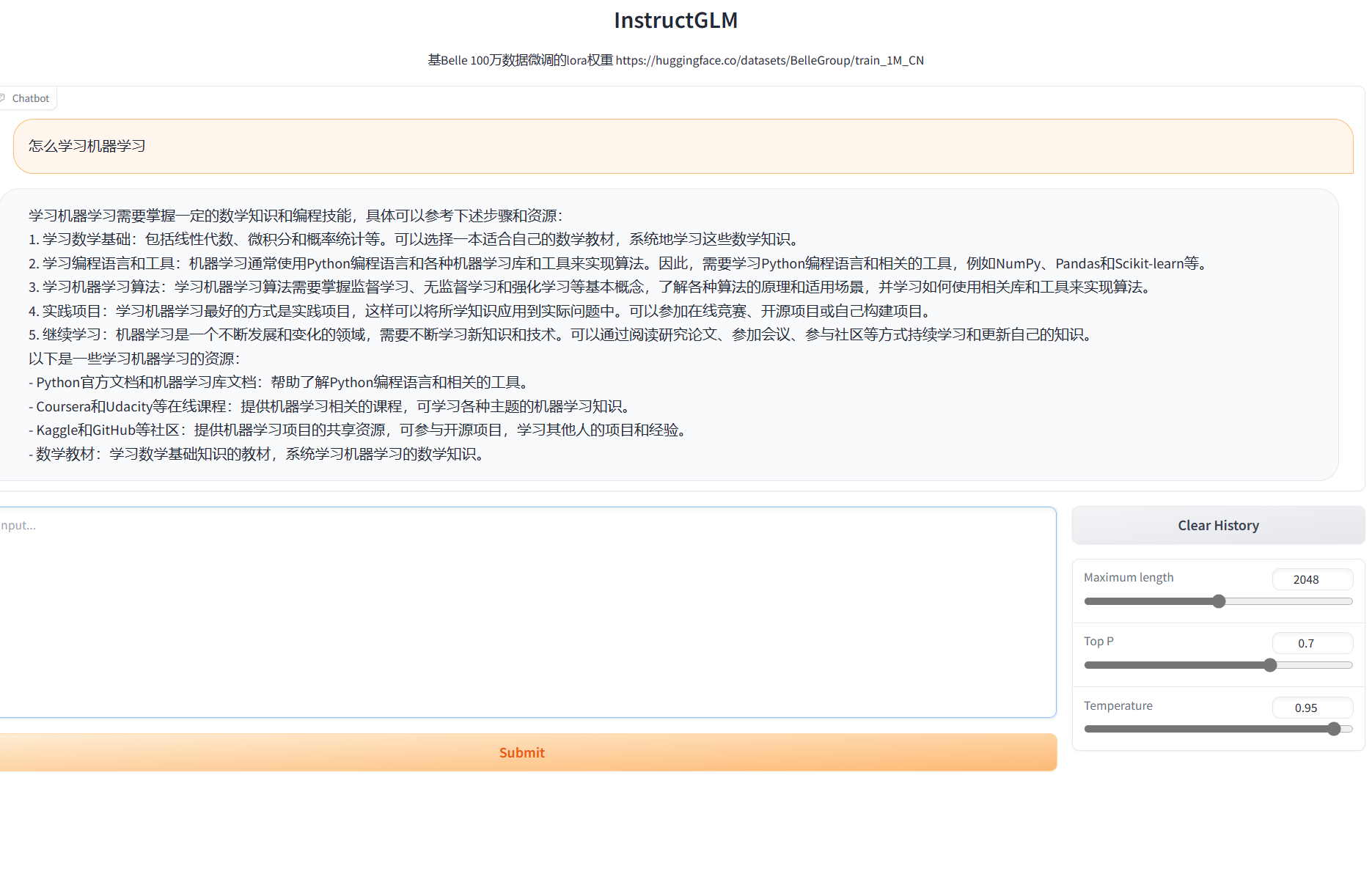
- belle数据微调效果
非常感谢以下作者的无私开源
- https://github.com/mymusise/ChatGLM-Tuning
- https://huggingface.co/BelleGroup/BELLE-7B-2M
- https://github.com/LianjiaTech/BELLE
- https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN
- https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
- https://guanaco-model.github.io/
- https://github.com/carbonz0/alpaca-chinese-dataset
- https://github.com/THUDM/ChatGLM-6B
- https://huggingface.co/THUDM/chatglm-6b
- https://github.com/lich99/ChatGLM-finetune-LoRA
- gcc版本升级
yum install centos-release-scl -y
yum install devtoolset-9 -y
#临时覆盖系统原有的gcc引用
scl enable devtoolset-9 bash
# 查看gcc版本
gcc -v