
The goal of this Google Colab notebook is to capture the distribution of Steam banners and sample with a StyleGAN2.
- Acquire the data, e.g. as a snapshot called
256x256.zipin another of my repositories, - Run
StyleGAN2_training.ipynbto train a StyleGAN2 model from scratch, - Run
StyleGAN2_image_sampling.ipynbto generate images with a trained StyleGAN2 model, - To automatically resume training from the latest checkpoint, you will have to use my fork of StyleGAN2.
For a more thorough analysis of the trained model:
- Run
StyleGAN2_metrics.ipynbto compute metrics (FID, PPL, etc.), - Run
StyleGAN2_latent_discovery.ipynbto discover meaningful latent directions, - Run
Ganspace_colab_for_steam.ipynbto specifically use GANSpace for discovery,
The dataset consists of 14,035 Steam banners with RGB channels and resized from 300x450 to 256x256 resolution.
Our dataset (14k images) has a similar size to the FFHQ dataset (70k images, so about 5 times larger than our dataset).
The StyleGAN2 model is trained with configuration e to accommodate for Google Colab's memory constraints.
Training parameters are arbitrarily chosen, with an inspiration from the values detailed in the StyleGAN2 README for the FFHQ dataset:
--mirror-augment=true: data augmentation with horitontal mirroring,--total-kimg=5000: during training with our dataset, StyleGAN2 will be shown 5 million images, so 5 times fewer images than for FFHQ (25 million images:--total-kimg=25000).
With mirroring, the dataset size is about 28k images. So, the model ends up being trained for 178 epochs.
Caveat: there is no good rule-of-thumb! Indeed, the right value would depend on the difficulty of the task (the more complex the task to learn, the longer training is needed ; e.g. generating game banners vs. human faces, 256x256 resolution vs. 1024x1024 resolution, etc.), and not solely on the size of the training dataset (the more diverse data is available, the longer training is possible without over-fitting the training dataset).
The training is performed for 5,000 kimg, i.e. 5 million images, which translated into roughly 625 ticks of 8 kimg.
Given that each tick requires 15 minutes of computation, the total training time with 1 GPU on Google Colab is about 6.5 days.
During training, checkpoints of the model are saved every thousand epochs, and shared on Google Drive.
The last snapshot (network-snapshot-005000) can be directly downloaded from the following links for:
- TensorFlow (
.pkl), - PyTorch (
.pt), thanks to a model-weight converter.
The generated images are diverse, in terms of configuration and color palettes. Interestingly, it seems that an anime character (with large eyes, hair, mouth, ear and nose) has been learnt.
A grid of generated Steam banners is shown below:

For comparison, here is a grid of real Steam banners:

Moreover, a directory of 1000 generated images is shared on Google Drive:
The term 'truncation' refers to the truncation trick mentioned in Appendix B of the StyleGAN1 paper:
If we consider the distribution of training data, it is clear that areas of low density are poorly represented and thus likely to be difficult for the generator to learn. This is a significant open problem in all generative modeling techniques. However, it is known that drawing latent vectors from a truncated [42, 5] or otherwise shrunk [34] sampling space tends to improve average image quality, although some amount of variation is lost.
The influence of truncation can be studied with side-by-side comparison of generated images. In this folder, 25 side-by-side comparisons are provided:
- images to the left are obtained without truncation,
- images to the right are obtained with the same seed and with truncation.
A few examples are shown below:






In the grids below, styles from the first row and first column are mixed.
Similarly to style mixing of faces:
- the pose and geometrical shapes are similar for images in the same column,
- the color palette is similar for images in the same row.

With truncation, color palettes are less diverse, which is expected, and seem to be darker.
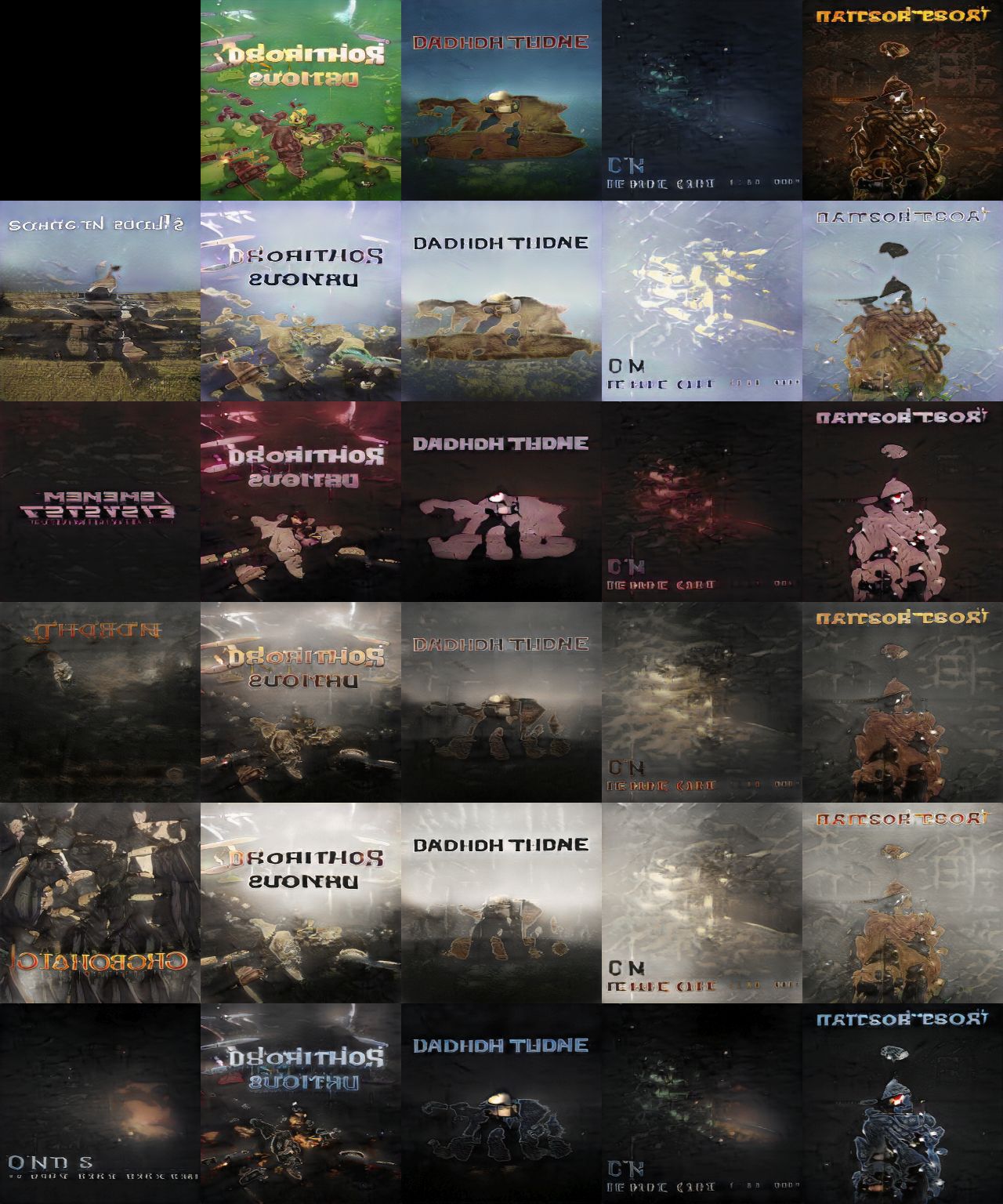
Real Steam banners can be projected to latent space. Projections obtained with 23 popular games are shown on the Wiki. A directory with similar data is also shared on Google Drive.
Each row corresponds to a different game. From left to right, the columns correspond to :
- the generated image obtained at the start of the projection,
- the generated image obtained at the end of the projection,
- the target (real) image.


















The title position is usually correct, even though the letters appear as gibberish. The color palette is correct. The appearance of characters is rough. For the last case (Hitman), the projected face is interesting, with the mouth, nose, and what appears to be glasses to reproduce the appearance of eyes in the shade.
- StyleGAN2:
- StyleGAN:
- DCGAN:
- Useful tools:
- My fork of StyleGAN2 to project a batch of images, using any projection (original or extended)
- A model-weight converter from TensorFlow (
.pkl) to PyTorch (.pt), with some instructions here
- Detailed tutorials:
- Papers about the unsupervised discovery of latent directions: