![]()
This repository contains Python code to tweak the Interactive Recommender of Steam Labs.
The "Interactive Recommender" is a tool provided by Valve on July 11, 2019 to suggest personalized game recommendations. On March 18, 2020, the tool was officially released in production for the whole store.
The input is:
- the user's 50 most played games, along with normalized playtime, last play date, counter of the last played games,
- minimal external information about the game (the release date).
NB: It is not known whether the input is really limited to the 50 most played games. It is possible that the whole game library is actually taken into account, and that the 50 most played games only appear on the Recommender webpage for cosmetic purposes.
A neural network predicts the probability that a game is the next purchase of this user, based on the data available for millions of other users.
The output of the neural network is transformed with an unknown formula to give more or less importance to:
- popularity,
- release recency.
The most basic assumption for this formula would be such as:
tweaked_output = neural_network_output + popularity_bias * popularity + release_recency_bias * release_recency
It is likely that the release recency is simply used with a threshold to filter out older games. In this case, the suggested formula would be instead:
tweaked_output = neural_network_output + popularity_bias * popularity
The tweaked outputs are then scaled, so that the top recommendation is always assigned the score of 1000. The scale is stored.
tweaked_output = score_scale * score
Sorting the scores results in a ranking of game recommendations personalized to the user's data.
As of December 7, 2021, Valve filed a patent US 11,194,879 B2 (PDF file) which clarifies the situation:
- popularity, "as determined by sales of the game", is a biasing factor of the score,
- release recency is used upstream: different models are trained for different values of the release recency!
Moreover, popularity seems quantized into "levels", i.e. games fall in M=5 bins, which probably correspond to:
- very popular
- popular
- neutral
- unpopular (or "niche")
- very unpopular (or very "niche")
Therefore, popularity can be one-hot encoded for each game, and popularity bias can be expressed as a M-dimensional vector, which makes it easy to tweak the output and, at the same time, impossible for an observer to estimate popularity as a continuous value in terms of sales.
**Quotes from the patent**
In addition, the computing system may be configured to bias the score data based on different values of one or more biasing factors. The biasing factors may comprise any number of factors, such as a popularity of each game, a cost of each game, a genre of each game, or the like. In one example, the biasing factor may comprise a popularity of each game, as determined by sales of the game, an amount of gameplay of the game, and/or the like. In some instances, each score data (determined by an individual trained model) may be biased at different levels of popularity such that the resulting biased data will more closely match that particular level of popularity if so desired by the user. That is, the computing system may bias the score for each game title (and for each model) at a number of “M” target levels of popularity ranging from very popular to very unpopular (or very “niche”). As the reader will appreciate, the computed scores of those game titles that are very popular will be boosted for a target level of popularity of “very high” and will be penalized for a target level of popularity of “very low”. Conversely, the computed scores of more niche game titles will be penalized for a target level of popularity of “very high” and will be boosted for a target level of popularity of “very low”.
Finally, given that the computing system has now computed, for a particular user, score data for each of “N” number of trained models, and has biased each of these scores using “M” number of popularity values, then computing system may now have generated an amount of scores for the user in an amount of “M×N”. For example, if the computing system utilizes six models and five levels of popularity, then the computing system will have generated a total of thirty scores for any particular user (given that each of the six score data generated by the model will biased five times). Of course, it is to be appreciated that the computed score data may have any other number of values and may be sampled in any other (e.g., nonlinear) manner. Further, while this example describes inputting values of a first parameter prior to training the model (in this case, based on release date) and values of a second after the training (in this case, based on popularity), any other number of parameters may be applied as input to the model and/or as part of the postprocessing described with reference to the popularity data. It is also noted that while the postprocessing parameters are described as biasing factors, these biasing factor(s) represent parameter(s) that may be applied as inputs to the models or as part of postprocessing.
Data personalized to my Steam profile is available in the following folders:
data/,data_v2/after the update shipped on July 27, 2019,data_v3/after the update shipped on August 8, 2019.
- Install the latest version of Python 3.X.
- Install the required packages:
pip install -r requirements.txtYou could manually download the inputs and results of the recommender to data_v3/.
Otherwise, this process can be automated after providing the following personal information:
-
Fill-in your SteamID in the function
get_steam_id()found inutils.py. -
Fill-in your cookie information in a new file called
personal_info.json:
{
"sessionid": "PASTE_YOUR_COOKIE_VALUE_HERE",
"steamLoginSecure": "PASTE_YOUR_COOKIE_VALUE_HERE"
}Afterwards, run the following script to download the data:
python file_utils.pyThere are 30 pre-computed recommendation rankings of 200 games (algorithm_options) for the combinations of:
- 5 popularity biases,
- 6 release recency biases.
A combination of sliders of the "Interactive Recommender" leads to an interpolation of the 4 closest rankings. If a game appears in a ranking but not in the 3 others, its score is set to 0 for the 3 other rankings, and the interpolation is then computed.
It is a nice trick to allow people to play with the sliders:
- without giving too much information away, especially the formula and the "popularity" values for each game,
- without overloading the browser with data. There are 30 rankings instead of 101x101.
Moreover, it is important to notice that the interpolation is bilinear, which is consistent with the linear formula
mentioned above for tweaked_output with respect to the popularity bias.
However, with respect to the release recency bias, it might be a hack ; further investigations would be required to figure it out.
Sliders can be misleading, especially if you filter rare tags.
For instance, recommendations for the past 10 years do NOT necessarily include recommendations for the past 6 months.

This is a consequence of cutting the pre-computed rankings after 200 entries, and then interpolating rankings.
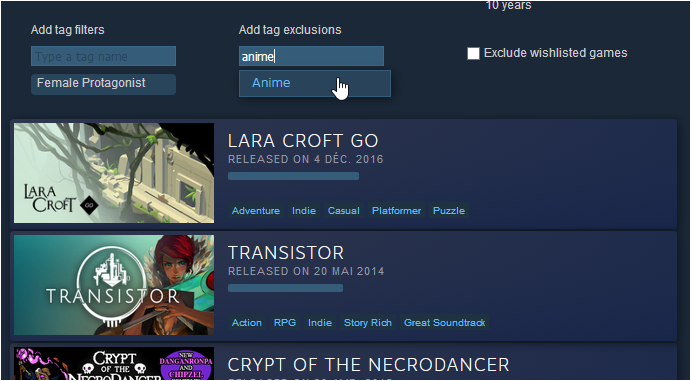
In order not to overwhelm people with 337 tags, most tags are not displayed in the drop-down menu.
However, you can manually add them, and the "Interactive Recommender" will work perfectly fine with them! All you need is the id for the tag of interest in the HTML page of the "Interactive Recommender". For instance:
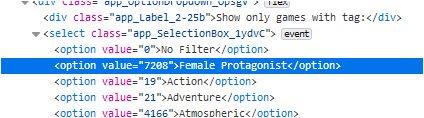
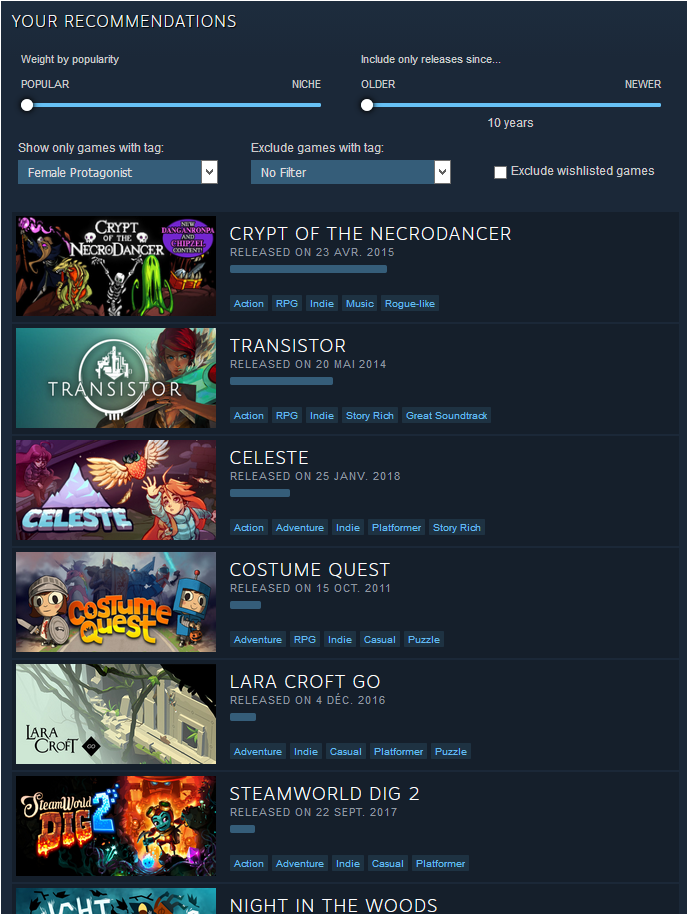
Caveat: if nothing appears, then do not forget to move the sliders. Indeed, you might have a recommendation in one of the other pre-computed rankings, and due to ranking interpolation, you would have to fiddle with the sliders for a new game to pop in.
Edit: Tag filtering was officially extended to every tag with the update shipped on August 8, 2019.
- Setting the slider to "popular" is mostly useful for new Steam users.
Looking for "popular" games makes sense for new Steam users. However, for long-time users, you likely know about the surfaced "popular" games, and discarded them for good reasons. Looking for more "niche" games increases the chance to discover a game which you might want to purchase and play.

- The recommender might be biased by game bundles.
The recommender might be biased by game bundles. Indeed, a few games could get recommended solely because they appeared in a bundle along with games which you own. Focusing on recent releases (max 2-3 years) should alleviate this issue, because recent games are less likely to have been featured in many bundles.

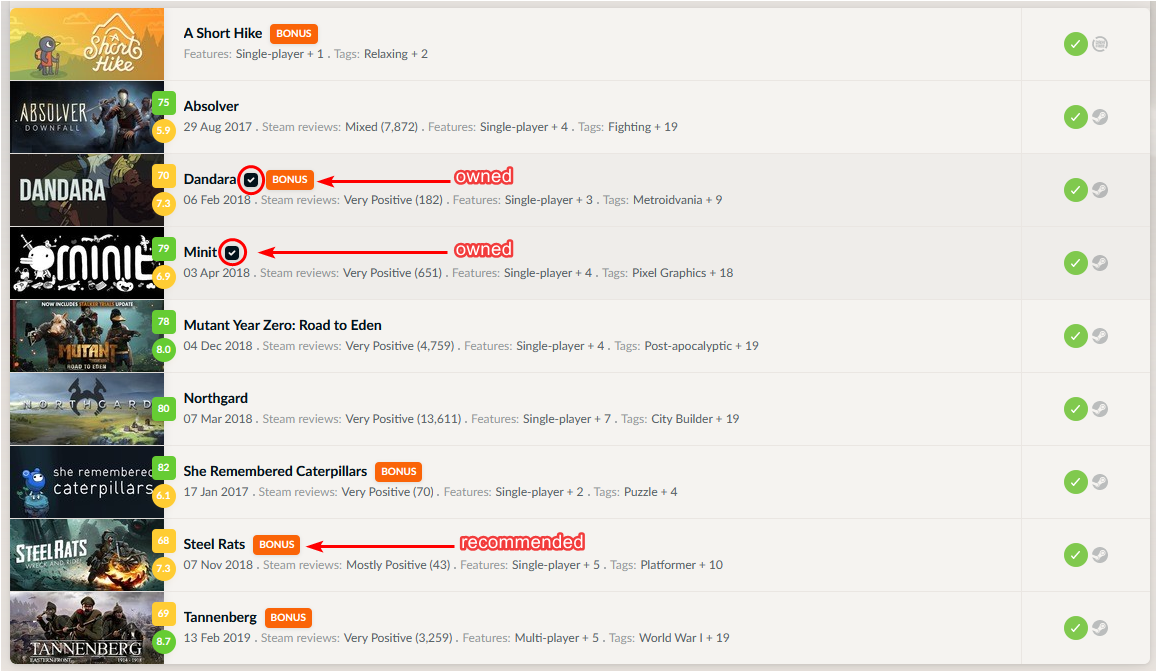
For instance, I suspect that the game "Steel Rats" is recommended to me because it was featured in a Humble Monthly bundle along with two games (MINIT and Dandara) which I have purchased with Group Buys and then played. That being said, I might be overestimating the impact of this issue, which may be toned down if the Recommender really only considers my 50 most played games, which do not include any of these two games.
On April 27, 2019, Valve shipped an update which allows to exclude games from the input data. This allows us to figure out whether the input data is limited to the top 50 games, or if it is larger, potentially up to the whole user library.
I have tried the recommender with a smurf account which has:
- three games (Dota2, Chivarly, Mirage),
- non-zero playtime only for Dota2.
As a first observation, the list shown on the left of the recommender only includes Dota2. This confirms that, at least cosmetically, owned games with zero playtime are ignored.
Second, if Dota2 is manually excluded from the input data, then there is no recommendation at all. This shows that:
- there is no default recommendation,
- games with zero playtime are effectively ignored.

Now, if I go back to my main account, and manually exclude all of the top 50 games from the input data, there are still recommended games. This implies that the input data is not empty, and thus a bigger part of my library had to be taken into account.
In conclusion, the recommender is fed more than your top 50 games, likely your whole library data (with positive playtime), including all of these idled games.
- Valve's patent US 11,194,879 B2 (PDF file)
- Microsoft's "Best Practices on Recommendation Systems",
- Posts on ResetERA to figure out the meaning of:
- the variables,
- some interpolation javascript code,
- the updates shipped on July 27, 2019,
- the definition of popularity (here and there): sales and wishlist activity over a time window,
- Explanations regarding the interpolation of rankings: here and there,
Steam-Hype: a possible measure of the popularity of a game,- A tweak to filter any of the 337 tags with the current Interactive Recommender,
- An article on PC Gamer which provides nice insights regarding my approach to discover hidden gems.