Xubin Wang12 · Zhiqing Tang1 · Jianxiong Guo23 · Tianhui Meng2 · Chenhao Wang23 · Tian Wang23 · Weijia Jia23*
1Hong Kong Baptist University · 2Beijing Normal University · 3BNU-HKBU United International College
*corresponding authors


- 1. Background Knowledge
- 2. Our Survey
- 3. The Data-Model-System Optimization Triad
- 4. Important Surveys on Edge AI (Related to edge inference and model deployment)
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the sources of data. This is expected to improve response times and save bandwidth.
- Edge AI refers to the deployment of artificial intelligence (AI) algorithms and models directly on edge devices, such as mobile phones, Internet of Things (IoT) devices, and other smart sensors.
- By processing data locally on the device rather than relying on cloud-based algorithms, edge AI enables real-time decision-making and reduces the need for data to be transmitted to remote servers. This can lead to reduced latency, improved data privacy and security, and reduced bandwidth requirements.
- Edge AI has become increasingly important as the proliferation of edge devices continues to grow, and the need for intelligent and low-latency decision-making becomes more pressing.
- Edge AI – What is it and how does it Work?
- What is Edge AI?
- Edge AI – Driving Next-Gen AI Applications in 2022
- Edge Intelligence: Edge Computing and Machine Learning (2023 Guide)
- What is Edge AI, and how does it work?
- Edge AI 101- What is it, Why is it important, and How to implement Edge AI?
- Edge AI: The Future of Artificial Intelligence
- What is Edge AI? Machine Learning + IoT
- What is edge AI computing?
- 在边缘实现机器学习都需要什么?
- 边缘计算 | 在移动设备上部署深度学习模型的思路与注意点
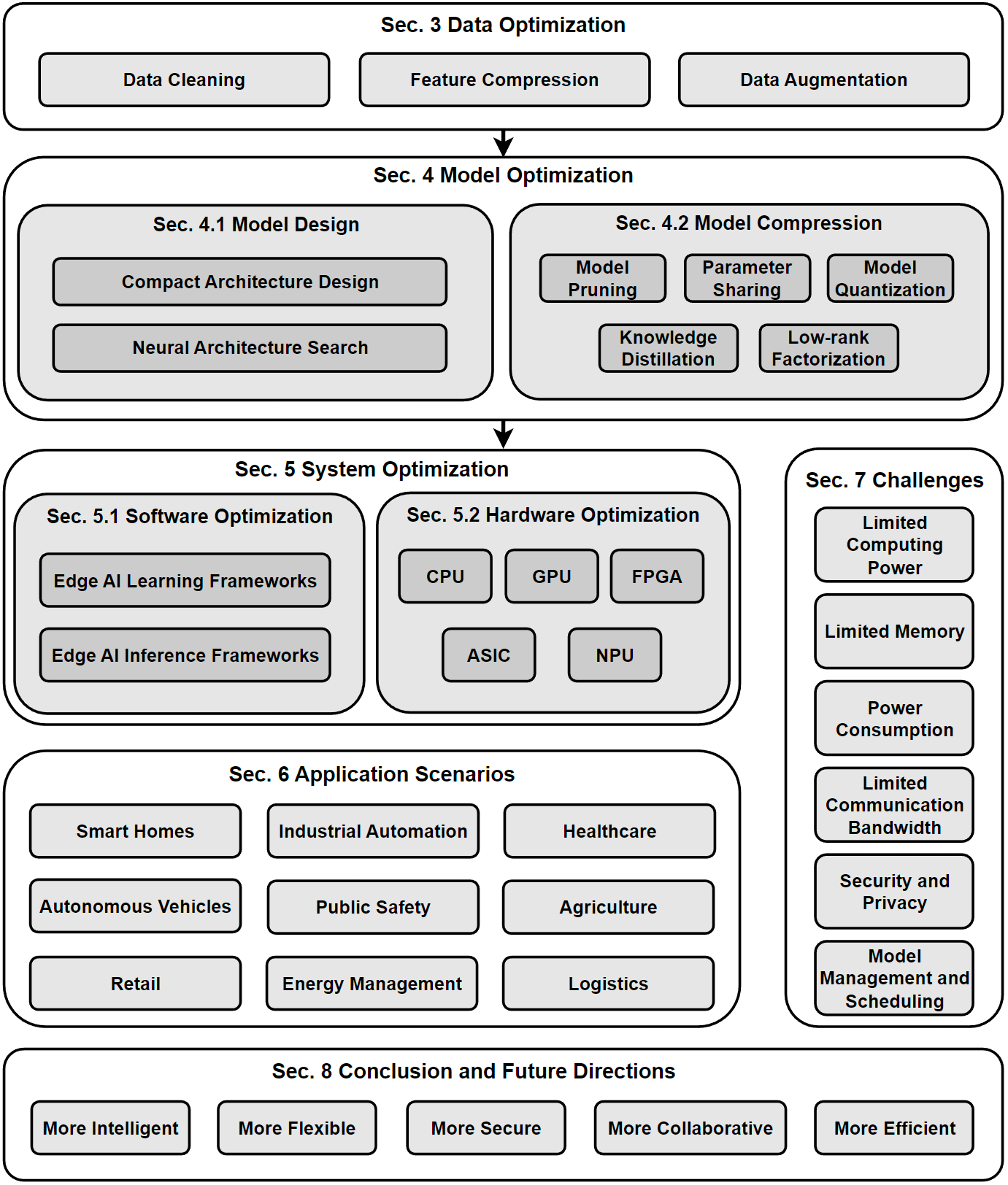
We introduce a data-model-system optimization triad for edge deployment.
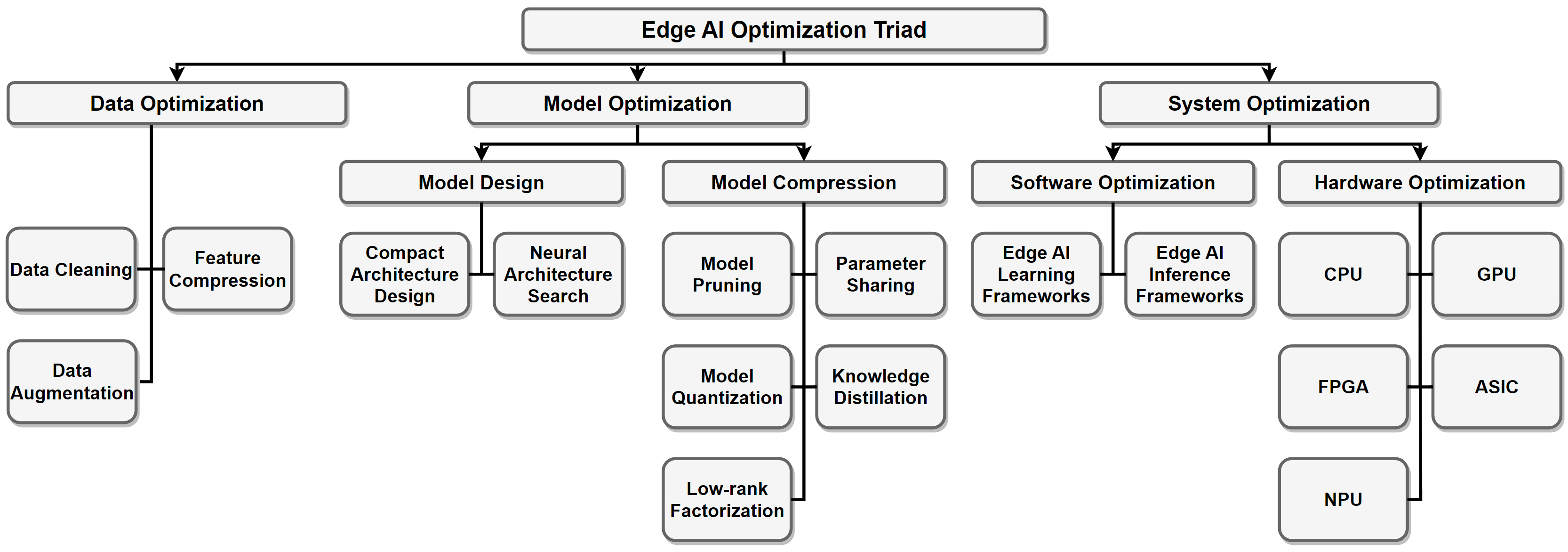
An overview of edge deployment. The figure shows a general pipeline from the three aspects of data, model and system. Note that not all steps are necessary in real applications.
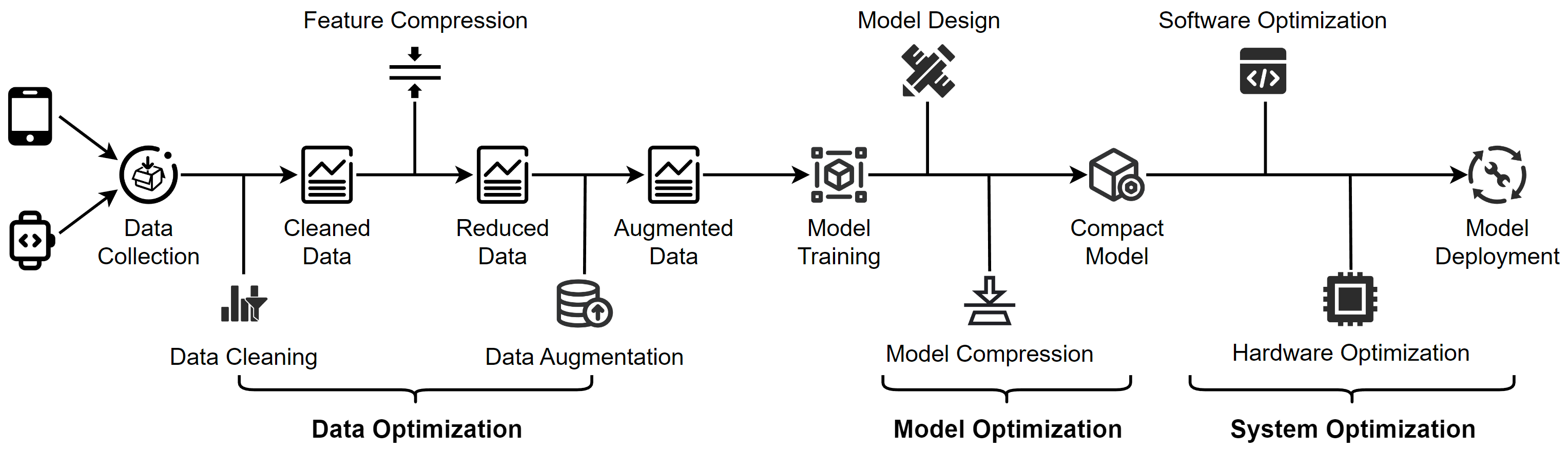
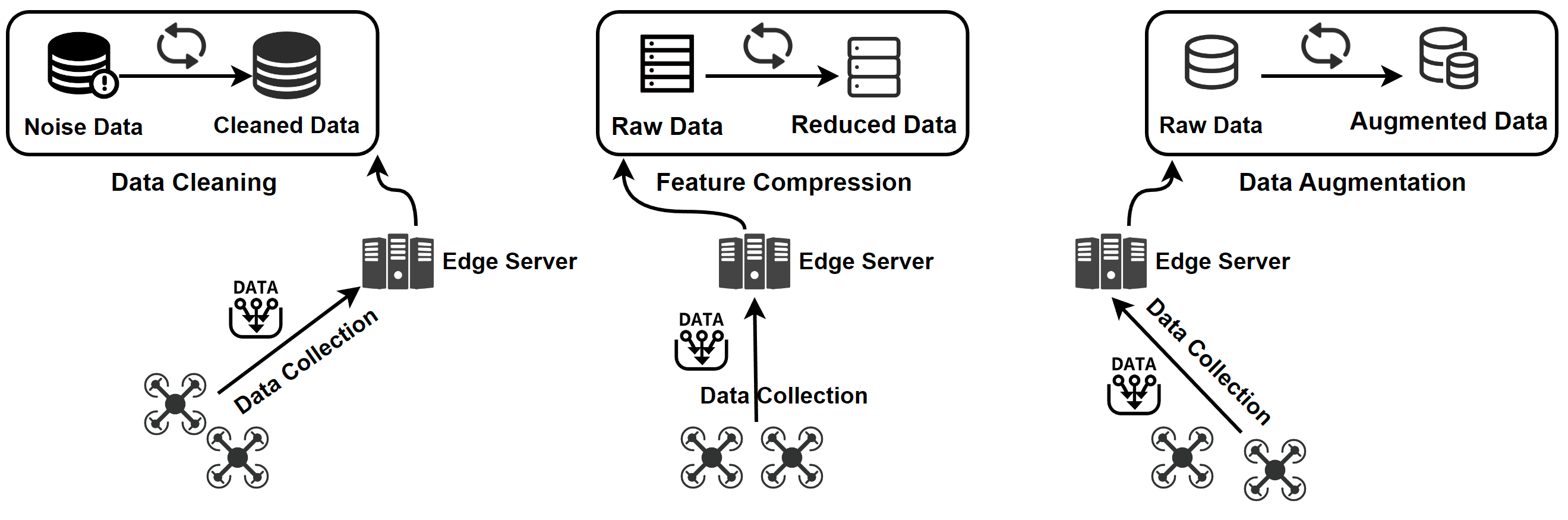
An overview of data optimization operations. Data cleaning improves data quality by removing errors and inconsistencies in the raw data. Feature compression is used to eliminate irrelevant and redundant features. For scarce data, data augmentation is employed to increase the data size.
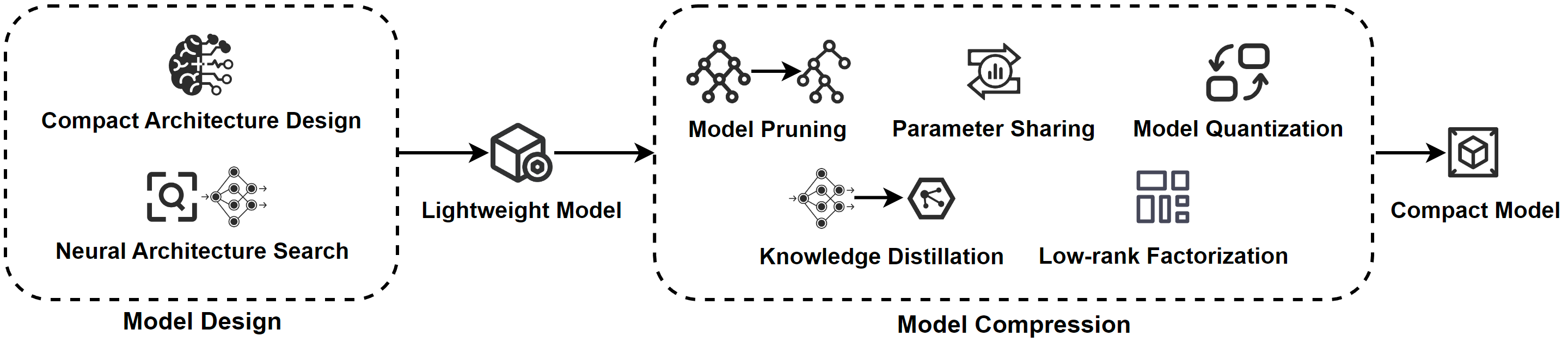
An overview of model optimization operations. Model design involves creating lightweight models through manual and automated techniques, including architecture selection, parameter tuning, and regularization. Model compression involves using various techniques, such as pruning, quantization, and knowledge distillation, to reduce the size of the model and obtain a compact model that requires fewer resources while maintaining high accuracy.
| Title & Basic Information | Affiliation | Code |
|---|---|---|
| Learning low-rank deep neural networks via singular vector orthogonality regularization and singular value sparsification[C] CVPR workshops. 2020. | Duke University | -- |
| MicroNet: Towards image recognition with extremely low FLOPs[J]. arXiv, 2020. | UC San Diego | -- |
| Locality Sensitive Hash Aggregated Nonlinear Neighborhood Matrix Factorization for Online Sparse Big Data Analysis[J]. ACM/IMS Transactions on Data Science (TDS), 2022. | Hunan University | -- |
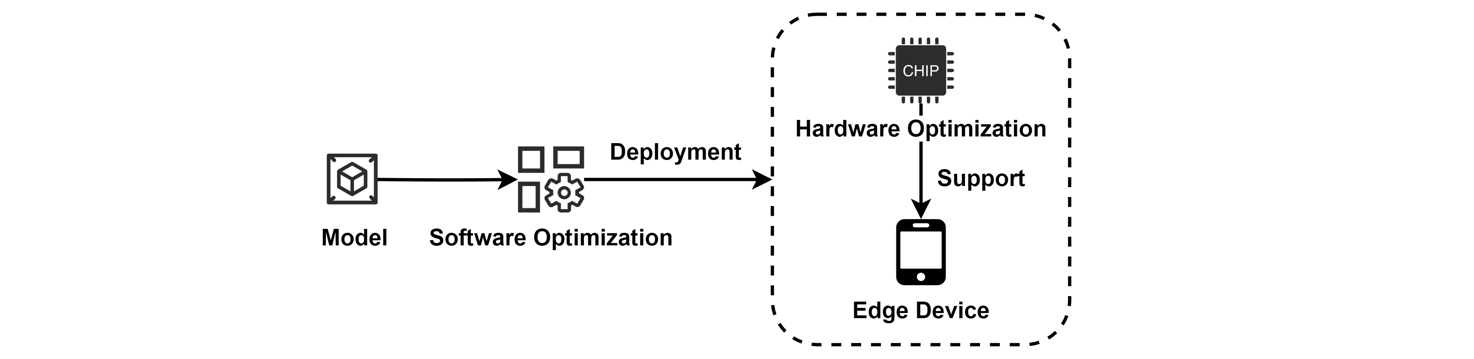
An overview of system optimization operations. Software optimization involves developing frameworks for lightweight model training and inference, while hardware optimization focuses on accelerating models using hardware-based approaches to improve computational efficiency on edge devices.
- Convergence of edge computing and deep learning: A comprehensive survey. IEEE Communications Surveys & Tutorials, 22(2), 869-904.

- Deep learning with edge computing: A review. Proceedings of the IEEE, 107(8), 1655-1674.

- Machine learning at the network edge: A survey. ACM Computing Surveys (CSUR), 54(8), 1-37.

- Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet of Things Journal, 7(8), 7457-7469.

- Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proceedings of the IEEE, 107(8), 1738-1762.

- Edge intelligence: Empowering intelligence to the edge of network. Proceedings of the IEEE, 109(11), 1778-1837.






