anaGo is a state-of-the-art library for sequence labeling using Keras.
anaGo can performs named-entity recognition (NER), part-of-speech tagging (POS tagging), semantic role labeling (SRL) and so on for many languages.
For example, English Named-Entity Recognition is shown in the following picture:
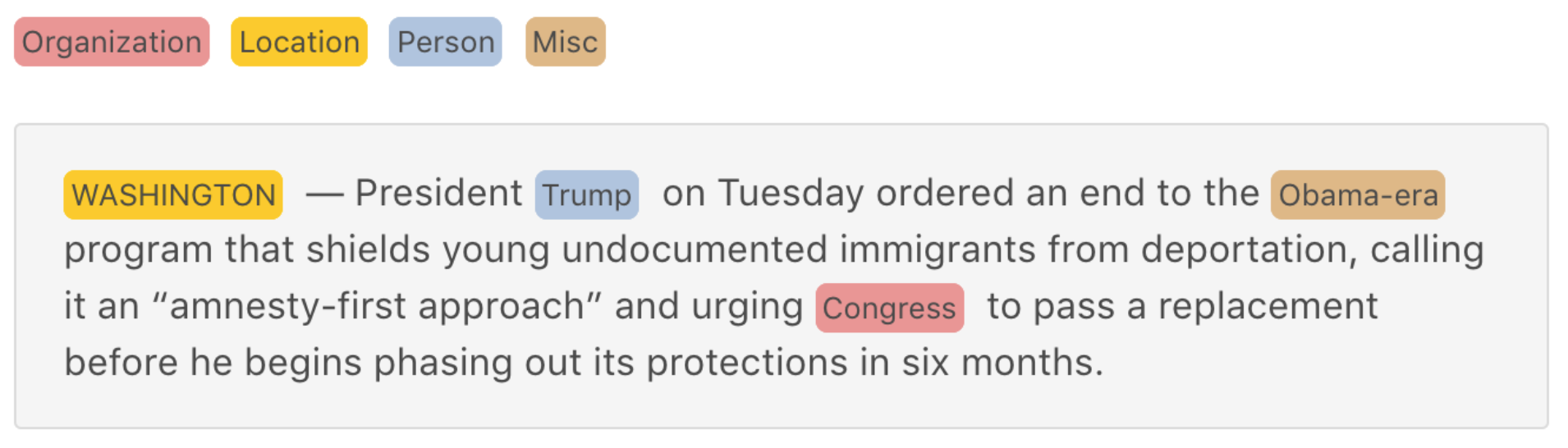
Japanese Named-Entity Recognition is shown in the following picture:

Similarly, you can solve your task for your language. You have only to prepare input and output data. :)
anaGo provide following features:
- learning your own task without any knowledge.
- defining your own model.
(Not yet supported)downloading learned model for many tasks. (e.g. NER, POS Tagging, etc...)
To install anaGo, simply run:
$ pip install anago
or install from the repository:
$ git clone https://github.com/Hironsan/anago.git
$ cd anago
$ pip install -r requirements.txt
The data must be in the following format(tsv). We provide an example in train.txt:
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
Peter B-PER
Blackburn I-PER
You also need to download GloVe vectors and store it in data/glove.6B directory.
First, import the necessary modules:
import os
import anago
from anago.data.reader import load_data_and_labels, load_word_embeddings
from anago.data.preprocess import prepare_preprocessor
from anago.config import ModelConfig, TrainingConfigThey include loading modules, a preprocessor and configs.
And set parameters to use later:
DATA_ROOT = 'data/conll2003/en/ner'
SAVE_ROOT = './models' # trained model
LOG_ROOT = './logs' # checkpoint, tensorboard
embedding_path = './data/glove.6B/glove.6B.100d.txt'
model_config = ModelConfig()
training_config = TrainingConfig()After importing the modules, read data for training, validation and test:
train_path = os.path.join(DATA_ROOT, 'train.txt')
valid_path = os.path.join(DATA_ROOT, 'valid.txt')
test_path = os.path.join(DATA_ROOT, 'test.txt')
x_train, y_train = load_data_and_labels(train_path)
x_valid, y_valid = load_data_and_labels(valid_path)
x_test, y_test = load_data_and_labels(test_path)After reading the data, prepare preprocessor and pre-trained word embeddings:
p = prepare_preprocessor(x_train, y_train)
embeddings = load_word_embeddings(p.vocab_word, embedding_path, model_config.word_embedding_size)
model_config.vocab_size = len(p.vocab_word)
model_config.char_vocab_size = len(p.vocab_char)Now we are ready for training :)
Let's train a model. For training a model, we can use Trainer. Trainer manages everything about training. Prepare an instance of Trainer class and give train data and valid data to train method:
trainer = anago.Trainer(model_config, training_config, checkpoint_path=LOG_ROOT, save_path=SAVE_ROOT,
preprocessor=p, embeddings=embeddings)
trainer.train(x_train, y_train, x_valid, y_valid)
If training is progressing normally, progress bar will be displayed as follows:
...
Epoch 3/15
702/703 [============================>.] - ETA: 0s - loss: 60.0129 - f1: 89.70
703/703 [==============================] - 319s - loss: 59.9278
Epoch 4/15
702/703 [============================>.] - ETA: 0s - loss: 59.9268 - f1: 90.03
703/703 [==============================] - 324s - loss: 59.8417
Epoch 5/15
702/703 [============================>.] - ETA: 0s - loss: 58.9831 - f1: 90.67
703/703 [==============================] - 297s - loss: 58.8993
...
To evaluate the trained model, we can use Evaluator. Evaluator performs evaluation. Prepare an instance of Evaluator class and give test data to eval method:
weights = 'model_weights.h5'
evaluator = anago.Evaluator(model_config, weights, save_path=SAVE_ROOT, preprocessor=p)
evaluator.eval(x_test, y_test)
After evaluation, F1 value is output:
- f1: 90.67
To tag any text, we can use Tagger. Prepare an instance of Tagger class and give text to tag method:
weights = 'model_weights.h5'
tagger = anago.Tagger(model_config, weights, save_path=SAVE_ROOT, preprocessor=p)
Let's try tagging a sentence, "President Obama is speaking at the White House." We can do it as follows:
>>> sent = 'President Obama is speaking at the White House.'
>>> print(tagger.tag(sent))
[('President', 'O'), ('Obama', 'PERSON'), ('is', 'O'),
('speaking', 'O'), ('at', 'O'), ('the', 'O'),
('White', 'LOCATION'), ('House', 'LOCATION'), ('.', 'O')]
>>> print(tagger.get_entities(sent))
{'Person': ['Obama'], 'LOCATION': ['White House']}This library uses bidirectional LSTM + CRF model based on Neural Architectures for Named Entity Recognition by Lample, Guillaume, et al., NAACL 2016.