The goal of this project is to implement a text based question answering system which can be used for different sectors. The system was designed that finds the closest questions among the previously asked questions by user and also the system returns correct answer to the user. In case of the answer could not be found, this system informs the user and finds soon a suitable answer. If the chosen answer is satisfactory for the user, the new question-answer binary is added to the database. After a certain period of time, the data is retrained to increase the success of system.
To find correct answer the closest question among the previously asked questions need to be found. This problem was solved with two different approaches. First approach is using neural network and second approach is using string similarity methods( Cosine similarity, Levenhstein distance, Qgram similarity) as a solution of the problem.
Neural networks models depend on size of data significantly, therefore string similarity methods can be used in some circumstances which insufficient sample exist in dataset. On the other hand, in case of the size of data increases, the accuracy of the neural network model will also increase.
Report of Project: https://github.com/umutguneri/Question-Answering-Assistant/blob/master/project_report.pdf
Apk file of mobile application: https://github.com/umutguneri/Question-Answering-Assistant/blob/master/mobileAssistant/mobileAssistant.apk
Jar file of desktop application: https://github.com/umutguneri/Question-Answering-Assistant/blob/master/Desktop%20Application%20(Java%20GUI)/Chatbot%20Assistant/Assistant.jar
Literature Review
On this project, it is aimed to response with appropriate answers to the questions asked by the user. It is expected that the system will only answer the questions in specific sector because this question answering system will be prepared for a specific sector purpose.
Objective of the Thesis
The project is a question answering system that improves learning with the logic that is set up at the back. It is aimed to create more accurate and meaningful answers over time. Methods to be used;
- Determining the needs and deficiencies in the first stage and eliminating the data and other needs for the project,
- Collection of question and answer text data from specific sectors,
- Cleaning of collected data,
- Training of different approaches of gathered data deep learning framework, application of optimization, regulation methods,
- Testing various methods to find similar questions to the question asked,
- If there are no similar questions, asking the user for new questions and getting the correct answer,
- If the system fails, re-arrange, train and test the new model.
Hypothesis
On this project my purpose is to give correct answers to the questions asked by users, although the level of achievement can not be reached in the first stage, it is aimed to reaching the acceptable levels of this level step by step.
System Requirements
- The web interface requires the following dependencies:
- python 3.5
- tensorflow (tested with v1.0)
- numpy
- CUDA (for using GPU)
- nltk (natural language toolkit for tokenized the sentences)
- tqdm (for the nice progression bars)
For The web interface requires these packages: –django –channels –Redis –asgi-redis
Workflow Schema for question answering system is shown in Figure:
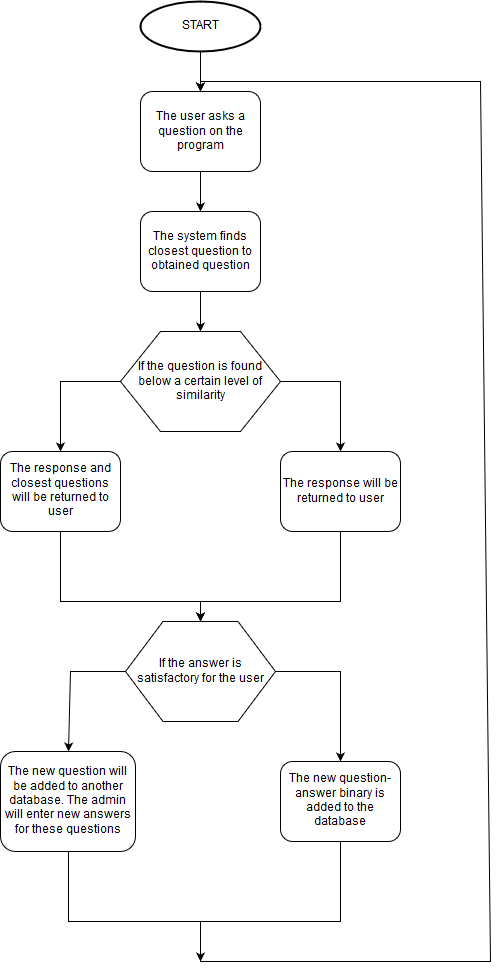
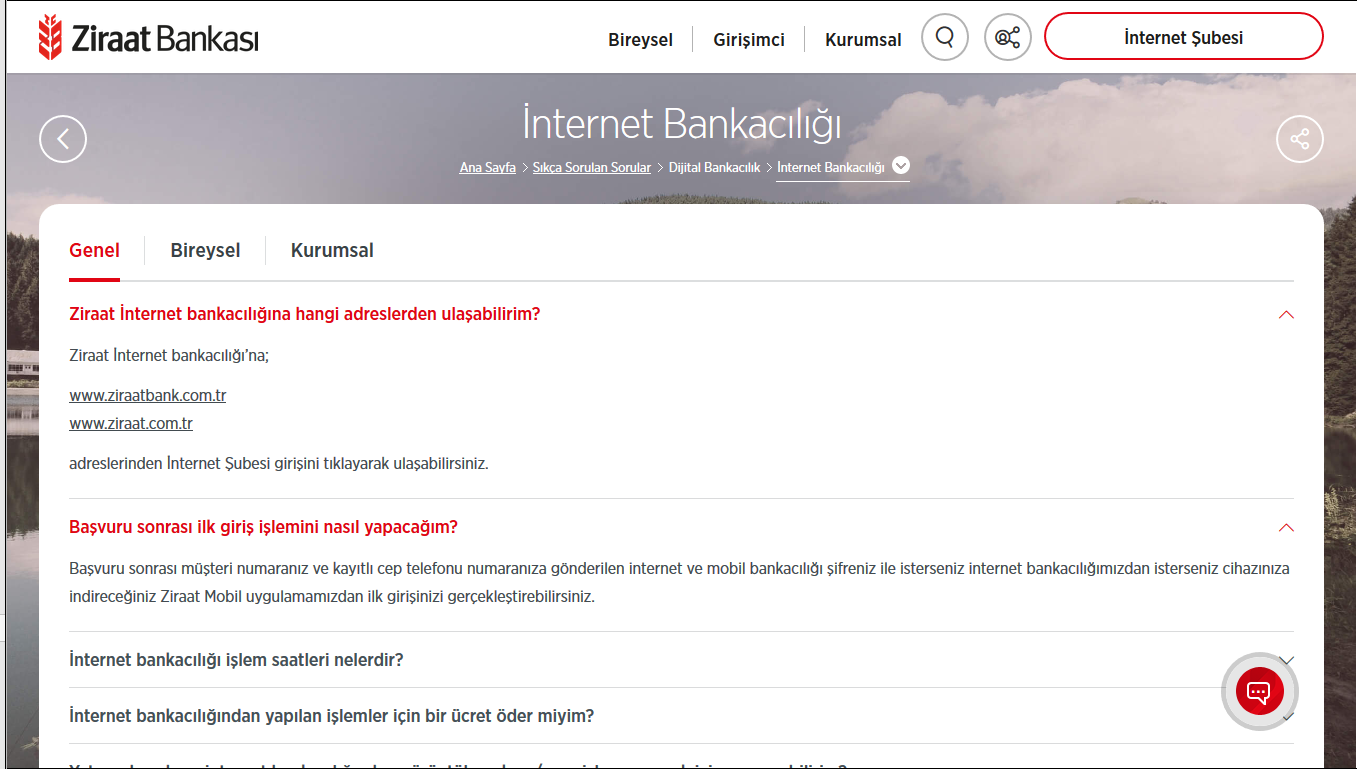
The dataset which is required for implementation of my project, has been obtained from section of frequently asked questions in Ziraat Bank website . On this section of website there were approximately 400 pair of question-answer about different subjects in banking sector.
This size of dataset is not enough for implementation my deep learning model. However the dataset can be used for beginning. Using desktop application this dataset can be enlarged for the deep learning model
Some of sample questions and answers are shown in Figure:
The models in this work are implemented with Tensorflow, and all experiments are processed in a GPU cluster. I use the accuracy on validation set to locate the best epoch and best hyper-parameter settings for testing.
The word embedding is trained by Word2vec, and the word vector size is 300. Word embeddings are also parameters and are optimized as well during the training. Stochastic Gradient Descent(SGD) is the optimization strategy. I tried different margin values, such as 0.05, 0.1 and 0.2, and finally fixed the margin as 0.2. As an network architecture, multi-layer perceptron model has been used on web interface. This model has 5 layer in total. (1 of them as an Input Layer, 3 of them as an Hidden Layer, 1 of them as an output Layer).
Each word vector, which is obtained of the questions in the data set, is used as input. The output layer has the indexes of the sentences placed in order. During training of the model after every epoch, the sentence index in the output layer is changed to 1 as 14 a binary value. Total number of questions in dataset is currently 488, which are used for training the model.
After 100 epochs the training phase of model is ended. Leaning rate is set to 0.001 and dropout rate is set to 0.5. This approach is very similar to the text classification methods, which use artificial neural networks.
Multi-layer perceptron model for question answering is shown in Figure:

The size of dataset is not enough for implementation my deep learning model. Therefore, in some cases the web application can not reply with correct answer. The solution for this problem is enlarging dataset for the deep learning model using desktop application. The mentality of desktop application is not complicated. The program finds closest question to obtained question using some similarity methods such as cosine similarity, levenshtein distance and Qqram similarity. If the user is satisfied with answer then he has to click Ok button so the new question and answer will be added on database.
If the user is not satisfied with answer, the user can choose one of 5 most similar questions. In this case, a new answer will be shown on text area. If the user is still not satisfied with answer, then he has to click on Not Ok button, the question and answer will be added in another database. The admin will enter new answers after a while for the question.
Using this desktop application, enlarging dataset for the deep learning model can be possible.
UML diagram of desktop application is shown in Figure:

The main page of Web application is shown in Figure. For now it is only for a demo homepage. Users can write their own question in text label as an input. After a couple of milliseconds the system will print the answer to the screen:

User can ask a question using web application. It is shown in Figure:

The answer and question will be shown on text area. It is shown in Figure:

If the user change previously asked question and asks a new question, the new answer will be shown on text area. It is shown in Figure:

The main page of desktop application is shown in Figure . Users can write their own question in text label as an input. After a couple of milliseconds the system will print the answer to the screen:

User can ask a question using desktop application. For this sample question :"Ziraat internet bankaciligina hangi adreslerden ulasabilirim?" the answer, most similar question and similarity rate are shown on screen. Due the question is already in database, similarity rate is 1.0 and correct answer is seen in text area. It is shown in Figure:

If the user change just one word on previously asked question and asks this question: "Ziraat internet bankaciligina hangi adreslerden ulasabilirim?", similarity rate will be 0.9 and same answer will be seen on text area. It is shown in Figure:
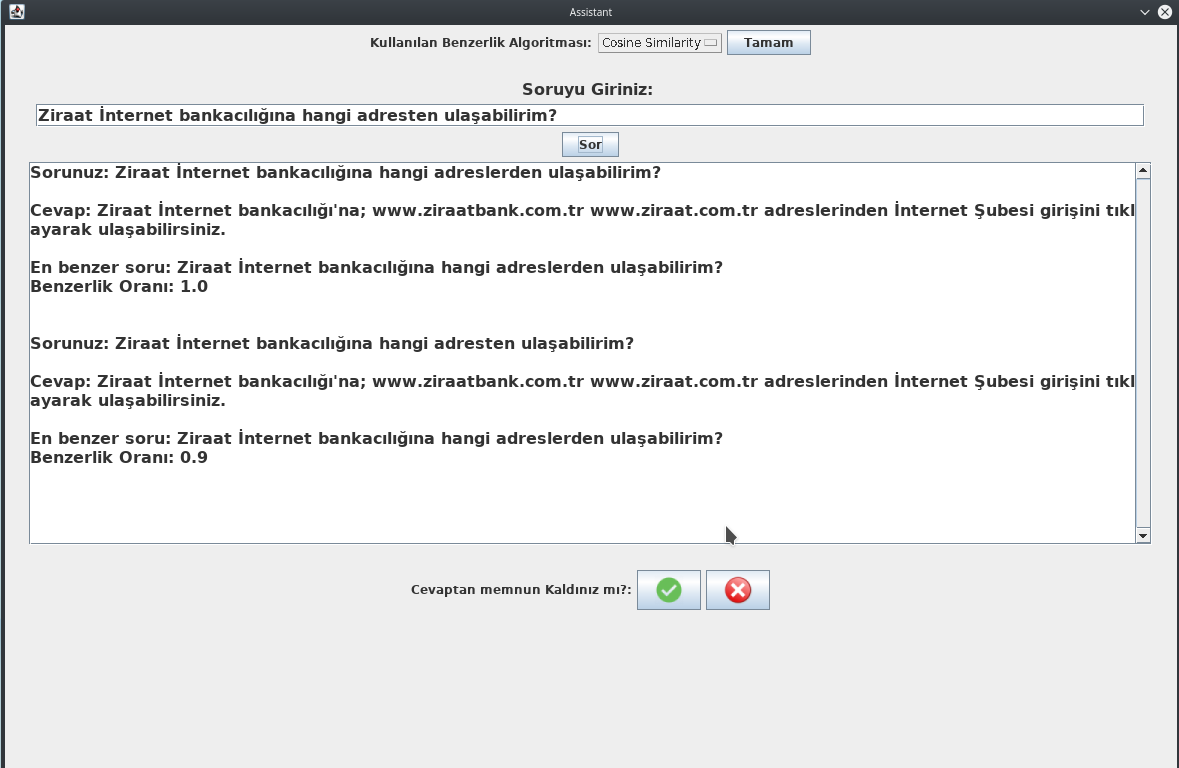
At the bottom of text area an important question is asked to user. It means "Are you satisfied with answer?". Also, Ok and Not ok button take part in right side of this question. It is shown in Figure:

If the user click on Ok button, the question and answer will be added in database. The message "The question is added in database" is shown in Figure:

if the user click on Not Ok button, the question and answer will be added in another database. The admin will enter new answers after a while for the question. The message "For your question will be found better answer in soon" is shown in Figure:

If the user change the question more deeply, the similarity rate between most similar question will drop. For this example question :"Ziraat bankaciligina nasil ulasabilirim?" similarity rate will be 0.7 and correct answer will be able to found by application. It is shown in Figure:
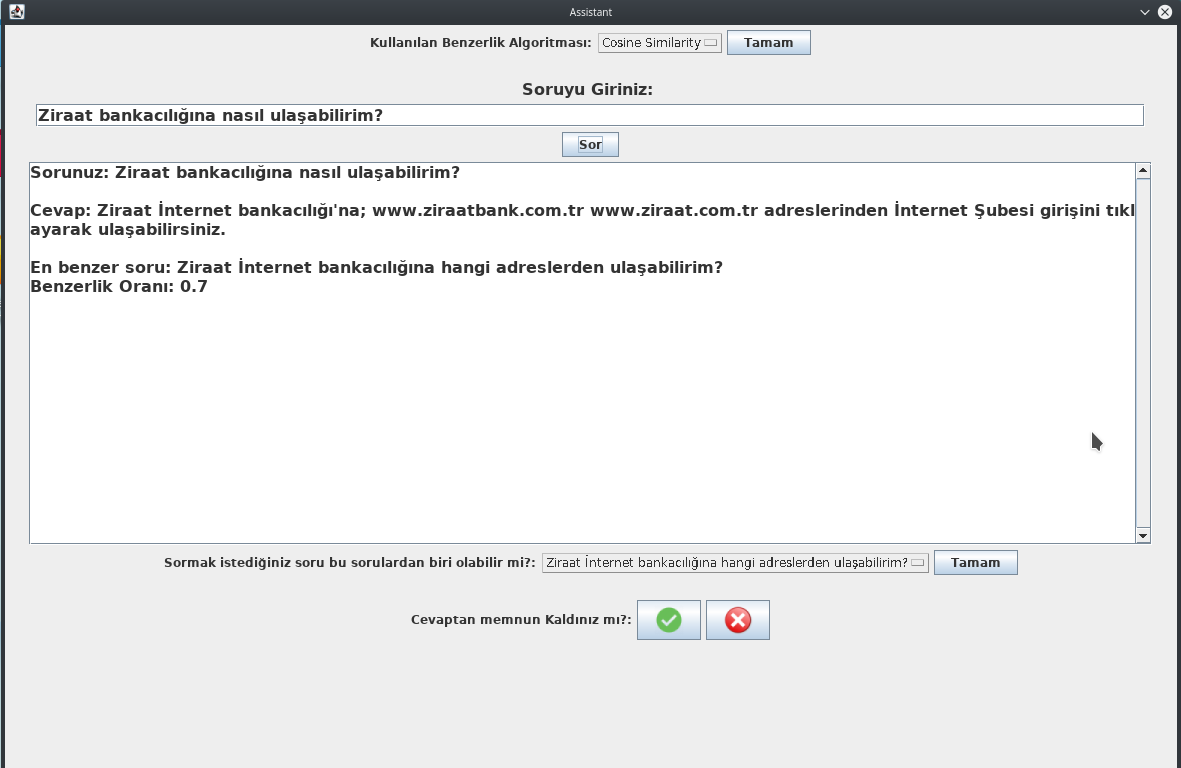
In this application, the user can choose the method which is used to find most similar question and its answer. For a now possible methods are cosine similarity, levenshtein and qram. It is shown in Figure:

If the user is not satisfied with question, the user can choose one of 5 most similar questions. In this case, a new answer will be shown on text area. Possible questions section is shown in Figure:

Before the main page of mobile application is shown, the splash screen is shown during a couple of seconds on android application. It is shown in Figure:

The main page of mobile application is shown in Figure. Users can write their own question in text label as an input. After a couple of milliseconds the system will print the answer to the screen:

User can ask a question using mobile application. For this sample question :"Kartım kayboldu, ne yapabilirim?" the answer, most similar question and similarity rate are shown on screen. It is shown in Figure:

At the above of text area an important question is asked to user. It means "Are you satisfied with answer?". Also, Ok and Not ok button take part in right side of this question. It is shown in Figure:

If the user click on Ok button, the question and answer will be added in database. The message "The question is added in database" is shown in Figure:

If the user click on Not Ok button, the question and answer will be added in another database. The admin will enter new answers after a while for the question. The message "For your question will be found better answer in soon" is shown in Figure:

If the user is not satisfied with question, the user can choose one of 5 most similar questions. In this case, a new answer will be shown on text area. Possible questions section is shown in Figure:

An evaluation model was used to measure user satisfaction with the question answering assistants. 10 different participants were given hard copy form of 50 question samples in the dataset to use the question-answer assistant.
Participants were requested to ask similar or related questions to these questions using web application and desktop application. After each response of the application, the users evaluated the system with a score of 1-5. This evaluating was based on the following 4 criteria:
- Were the answers given by Question Answering Assistant correct? (Quality)
- Are you satisfied with answers? (Quantity)
- Were the answers given by Question Answering Assistant relevant to subject? (Relation)
- Were the answers given by Question Answering Assistant clear? (Manner)
The result of the rating is shown in Table, which have done by the participants:

According to this frequency values accuracy can be calculated using sample mean formula.

Accordingly, the overall success of the system was estimated to be approximately **92%.
Performance Results
Question Answering Assistant has been tested on two different platforms (Windows and Android). This test was examined according to criteria such as time, speed, success.
First, when the application created on the mobile platform is examined, the opening time of the program takes 1-2 ms. No stuck or waiting period occurs during usage. Similarly, when we look at the desktop and web application, the opening time of the program lasts in ms. There is no hanging or waiting during usage.
In this project, a text based question answering assistant was implemented which can be used for different sectors. The system was designed that finds the closest question among the previously asked questions by user and also the system returns correct answer to the user. In case of the answer could not be found, this system informs the user and finds soon a suitable answer. If the chosen answer is satisfactory for the user, the new question-answer binary is added to the database. After a certain period of time, the data is retrained to increase the success of system.
Two different methods has been used to find best answer. First method is to use neural network model (LSTM) and second method is to use string similarity methods( Cosine similarity, Levenhstein distance, Qgram similarity) to find appropriate answer. Although both methods are considered successful enough, the neural network model needs more data sets.
When the experimental results of the project were reviewed, it was found that the participants evaluated the system very successfully. In 4 different criteria (Quality, Quantity, Manner, Relation) it was scored over 4 out of 5. Overall score is 4.6 points, which is about 92%.
On this project my purpose was to give correct answers to the questions asked by users, although the level of achievement could not be reached in the first stage, it was reached the acceptable levels of this level step by step. There are not many studies done in Turkish about question and answer systems. I hope this work will be useful for other studies.
1-Deep Learning for Answer Sentence Selection {https://arxiv.org/abs/1412.1632}, Lei Yu, Karl Moritz Hermann, Phil Blunsom, Stephen Pulman (Submitted on 4 Dec 2014).
2-End-To-End Memory Networks {https://arxiv.org/abs/1503.08895}, Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus (Submitted on 31 Mar 2015 (v1), last revised 24 Nov 2015)
3-Text REtrieval Conference (TREC) Question Answering Collections {https://trec.nist.gov/data/qa.html}, Voorhees, E. Tice, D. "Building a Question Answering Test Collection", Proceedings of SIGIR-2000, July, 2000, pp. 200-207
4-Memory Networks {https://arxiv.org/abs/1410.3916}, Jason Weston, Sumit Chopra, Antoine Bordes Submitted on 15 Oct 2014.
5-Neural Machine Translation by Jointly Learning to Align and Translate {https://arxiv.org/abs/1409.0473}, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio Submitted on 1 Sep 2014 , last revised 19 May 2016
6-A Sample of the Penn Treebank Corpus {https://www.kaggle.com/nltkdata/penn-tree-bank}, University of Pennsylvania 2017.
7-Embedding made from the text8 Wikipedia dump. {https://data.world/jaredfern/text-8-w-2-v}
8-SQuAD: 100,000+ Questions for Machine Comprehension of Text {https://rajpurkar.github.io/SQuAD-explorer/}, Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, Percy Liang (Submitted on 16 Jun 2016, last revised 11 Oct 2016 )
9-The Dialog State Tracking Challenge (DSTC) is an on-going series of research community challenge tasks. {https://www.microsoft.com/en-us/research/event/dialog-state-tracking-challenge/},
10-The Dialog State Tracking Challenge {https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/dstc2013.pdf}, Jason D. Williams, Antoine Raux, Deepak Ramachadran, and Alan Black. Proceedings of the SIGDIAL 2013 Conference, Metz, France, August 2013.
11-The Second Dialog State Tracking Challenge {https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/summaryWriteup.pdf}, Matthew Henderson, Blaise Thomson, and Jason D. Williams. Proceedings of SIGDIAL 2014 Conference, Philadelphia, USA, June 2014.
12-The Third Dialog State Tracking Challenge {https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/writeup.pdf}, Matthew Henderson, Blaise Thomson, and Jason D. Williams. Proceedings IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, USA, December 2014.
13-2015 International Workshop Series on Spoken Dialogue Systems Technology {http://wikicfp.com/cfp/servlet/event.showcfp=eventid=38683=copyownerid=66338},
14-The Fourth Dialog State Tracking Challenge {https://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/dstc4final-1.pdf}, Seokhwan Kim, Luis F. D'Haro, Rafael E Banchs, Matthew Henderson, and Jason D. Williams. Proceedings IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, USA, December 2014.
15-2016 IEEE Workshop on Spoken Language Technology {https://www2.securecms.com/SLT2016//Default.asp}, 13–16 December 2016 • San Diego, California
16-The Fifth Dialog State Tracking Challenge. Seokhwan Kim, Luis F. D'Haro, Rafael E Banchs, Matthew Henderson, Jason D. Williams, and Koichiro Yoshino. Proceedings IEEE Spoken Language Technology Workshop (SLT), San Diego, USA, December 2016.
17- The Dialogue Breakdown Detection Challenge {https://pdfs.semanticscholar.org/c1c1/34f2a411d70687142cb63da14e9d55ffbfb6.pdf}, Ryuichiro Higashinaka, Kotaro Funakoshi, Yuka Kobayashi, Michimasa Inaba, NTT Media Intelligence Laboratories , Honda Research Institute Japan Co., Ltd., Toshiba Corporation, Hiroshima City University
18-2017 Conference on Neural Information Processing Systems {https://nips.cc/}, Long Beach Convention and Entertainment Center, Long Beach, California, USA
19-Restaurant information train and development set {http://camdial.org/~mh521/dstc/}, Paul Crook - Microsoft Research, Maxine Eskenazi - Carnegie Mellon University, Milica Gasic - University of Cambridge (3rd February 2014)
20-Ziraat Bank frequently asked questions {https://www.ziraatbank.com.tr/tr/sss}
21- Tensorflow - An open source machine learning framework for everyone {https://www.tensorflow.org/}
22- Vector Representations of Words {https://www.tensorflow.org/tutorials/word2vec}
23-Optimization: Stochastic Gradient Descent {http://ufldl.stanford.edu/tutorial/}
24- Understanding LSTM Networks {http://colah.github.io/posts/2015-08-Understanding-LSTMs/}
25- Cosine Similarity {http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/}
26- Levensthein Distance {http://stackabuse.com/levenshtein-distance-and-text-similarity-in-python/}
27-Qgram Similarity {http://cs.uef.fi/~zhao/Link/Similarity-strings.html}