Abstract Graph Machine (AGM) models orderings in asynchronous parallel graph algorithms. The AGM model expresses a graph algorithm as a function (AKA ''processing function'') and an ordering (strict weak ordering relation). This repository contains an implementation of the AGM model, a set of graph kernels implemented using the AGM model. In addition to AGM graph kernels, repository also, contains distributed, shared-memory parallel graph kernels that do not use the AGM model. For distributed communication, the implementation uses MPI and an MPI based Active Messaging framework -- AM++[9]. All implementations are in C++ and we make use of heavy template meta-programming, therefore, compilation times are quite high but execution includes minimum overhead.
Authors of AGM : Thejaka Amila Kanewala, Marcin Zalewski, Andrew Lumsdaine (IU)
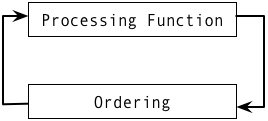
Above figure shows a very high-level overview of the Abstract Graph Machine. A graph kernel in AGM is expressed as a function and an ordering. The processing function takes a WorkItem as an input and produces zero or more WorkItems. The definition of a WorkItem can be based on vertices or edges. More concretely an AGM for a particular graph kernel is defined with the following:
- A definition of a Graph,
- A definition of a WorkItem,
- A definition of a set of states,
- A definition of a processing function,
- A set of initial WorkItems.
- A definition of a strict weak ordering relation on WorkItem.
- The WorkItem definition and the definition of the processing function:
// WorkItem definition
typedef std::tuple<Vertex, Level> WorkItem;
// The processing function
template<typename Graph, typename State>
struct bfs_pf {
public:
bfs_pf(const Graph& _rg, State& _st) : g(_rg),
vlevel(_st){}
template<typename buckets>
void operator()(const WorkItem& wi,
int tid,
buckets& outset) {
Vertex v = std::get<0>(wi);
int level = std::get<1>(wi);
int old_level = vlevel[v], last_old_level;
while(level < old_level) {
last_old_level = old_level;
old_level = boost::parallel::val_compare_and_swap(&vlevel[v], old_level, level);
if (last_old_level == old_level) {
BGL_FORALL_OUTEDGES_T(v, e, g, Graph) {
Vertex u = boost::target(e, g);
WorkItem generated(u, (level+1));
outset.push(generated, tid);
}
return;
}
}
}
private:
const Graph& g;
State& vlevel;
};- The ordering definition as a functor:
template<int index>
struct level : public base_ordering {
public:
template <typename T>
bool operator()(T i, T j) {
return (std::get<index>(i) < std::get<index>(j));
}
};- States and AGM execution:
// Initial work item set
std::vector<WorkItem> initial;
initial.push_back(WorkItem(source, 0));
DistMap distance_state(distmap.begin(), get(boost::vertex_index, g));
typedef bfs_pf<Graph, DistMap> ProcessingFunction;
ProcessingFunction pf(g, distance_state, sr);
// Level Synchronous Ordering
typedef boost::graph::agm::level<1> StrictWeakOrdering;
StrictWeakOrdering ordering;
// BFS algorithm
typedef agm<Graph,
WorkItem,
ProcessingFunction,
StrictWeakOrdering,
RuntimeModelGen> bfs_agm_t;
bfs_agm_t bfsalgo(pf,
ordering,
rtmodelgen);
time_type elapsed = bfsalgo(initial, runtime_params);More detials of the abstract model can be found in [1], [4], [5].
The extended AGM explores spatial and temporal ordering and derives less synchronous distributed, shared-memory parallel graph algorithms. The EAGM orderings can be peformed at global memory level, node memory level, NUMA memory level or at the thread memory level.
For extended AGM we pass a configuration that defines ordering for each memory level. E.g.,
...
CHAOTIC_ORDERING_T ch;
LEVEL_ORDERING_T level;
EAGMConfig config = boost::graph::agm::create_eagm_config(level, //global ordering
ch, // node ordering
ch, // numa ordering
ch); // thread ordering
// BFS algorithm
typedef eagm<Graph,
WorkItem,
ProcessingFunction,
EAGMConfig,
RuntimeModelGen> bfs_eagm_t;
bfs_eagm_t bfsalgo(rtmodelgen,
config,
pf,
initial);
...An example execution of an EAGM is shown in the below figure. For the following example, EAGM performs chaotic global ordering, node level Delta-Stepping, level synchronous NUMA ordering and Dijkstra ordering at the thread level.
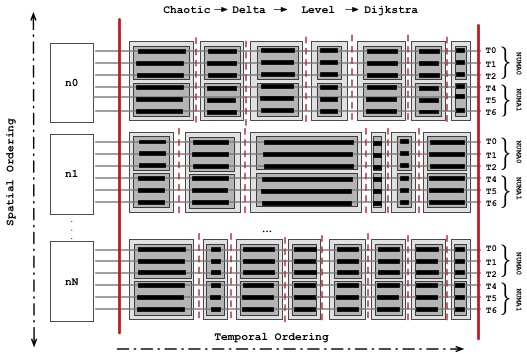
The AGM/EAGM graph processing framework is implemented as part of Parallel Boost Graph Library, version 2 (PBGL2). Graph structure definitions are based on the graph structure definitions provided by the PBGL2 (Compressed Sparse Row and Adjacency List). Further, AGM/EAGM model uses 1D graph distributions.
To enable parallel compilation (e.g., make -j4) every ordering is encapsulated into a separate translation unit. Therefore, you may see multiple drivers, to execute a single processing function.
- Breadth First Search -- With a single processing function, we can achieve multiple algorithms by changing ordering. E.g., The chaotic BFS does not perform any ordering, but Level synchronous BFS performs ordering by the level. BFS drivers available here.
- Single Source Shortest Path -- Multiple algorithms can be derived by changing orderings. This includes Delta-Stepping, KLA, Bellman-Ford, Distributed-Control. SSSP drivers available here.
- Connected Components -- Finds connected components. CC drivers are available here.
- Maximal Independent Set (MIS) -- The FIX MIS. MIS drivers are available here.
- Graph Coloring -- The original processing function is based on Jones-Plassman Graph Coloring. GC drivers are available here.
- k-Core Decomposition -- k-Core decomposition drivers are available here.
- PageRank -- PageRank drivers are available here.
- Triangle Counting (In Progress)
In addition to AGM/EAGM graph kernels we have number of different graph kernels that does not use the AGM/EAGM model. They are as follows:
-
Triangle Counting (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
-
Maximal Independent Set (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- FIX
- FIX-Bucket
- FIX-PQ -- Use "-DMIS_PRIORITY".
- Luby-A
- Luby-B -- Use SelectB template parameter for the select function.
- Driver : mis_family
-
Connected Components
- Traversal Based Connected Components (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Priority Connected Components (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Delta Based Connected Components (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Shiloach-Vishkin Connected Components (Authors : Nicholas Edmonds, Andrew Lumsdaine)
- Driver : cc_family
-
Breadth First Search
- Chaotic Breadth First Search (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Level-Synchronous Breadth First Search (Authors : Nicholas Edmonds, Douglas Gregor, Andrew Lumsdaine)
- Driver : bfs_family
-
Single Source Shortest-Paths
- Chaotic Single Source Shortest-Paths (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Chaotic Single Source Shortest-Paths with thread level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Chaotic Single Source Shortest-Paths with node level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Chaotic Single Source Shortest-Paths with NUMA level ordering -- Set numa=true in the constructor (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- KLA Single Source Shortest-Paths (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- KLA Single Source Shortest-Paths with thread level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- KLA Single Source Shortest-Paths with node level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- KLA Single Source Shortest-Paths with NUMA level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Delta-Stepping Shortes Paths (Authors : Nicholas Edmonds, Douglas Gregor, Andrew Lumsdaine)
- Delta-Stepping Single Source Shortest-Paths with thread level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Delta-Stepping Single Source Shortest-Paths with node level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Delta-Stepping Single Source Shortest-Paths with NUMA level ordering (Authors : Thejaka Amila Kanewala, Andrew Lumsdaine)
- Driver : sssp_family
-
PageRank (Authors : Nicholas Edmonds, Douglas Gregor, Andrew Lumsdaine)
- Driver : Application specific driver is in development. Use this test.
- MPI implementations (e.g., OpenMPI or MPICH)
- Boost (Thoroughly tested with 1.55)
- LibCDS (Thoroughly tested with 2.1.0)
Make sure Boost and LibCDS are compiled with the proper compiler wrappers.
For communication AGM/EAGM framework uses MPI based Active Messaging system : AM++.
Configure AM++ (inside runtime folder) as follows:
$ ./configure --prefix=<installation prefix> --enable-builtin-atomics --enable-threading=<MPI threading mode, multiple, serialized> --with-nbc=stub --with-boost=<boost install path> cc="<MPI C compiler wrapper, e.g., mpicc>" CXX="<MPI C++ compiler wrapper, e.g., mpicxx>"
$ make install
You can use CMake to build everything but it will take considerable amount of time. Therefore, it is advisable to build only the kernels you need. To build only the required kernels, you can use build.sh file. Set BOOST_INSTALL, AMPP_INSTALL and LIBCDS_INSTALL to appropriated paths and build the kernel as follows:
$ ./build.sh <kernel>
E.g.,
$ ./build.sh sssp_family
See LICENSE.txt.
[1] Kanewala, Thejaka Amila, Marcin Zalewski, and Andrew Lumsdaine. "Families of Graph Algorithms: SSSP Case Study." European Conference on Parallel Processing. Springer, Cham, 2017.
[2] [Best Student Candidate Paper] Kanewala, Thejaka, Marcin Zalewski, and Andrew Lumsdaine. "Distributed-memory fast maximal independent set." High Performance Extreme Computing Conference (HPEC), 2017 IEEE. IEEE, 2017.
[3] Kanewala, Thejaka, Marcin Zalewski, and Andrew Lumsdaine. "Parallel Asynchronous Distributed-Memory Maximal Independent Set Algorithm with Work Ordering." 2017 IEEE 24th International Conference on High Performance Computing (HiPC). IEEE, 2017.
[4] Kanewala, Thejaka, et al. "Families of Distributed Memory Parallel Graph Algorithms from Self-Stabilizing Kernels-An SSSP Case Study." arXiv preprint arXiv:1706.05760 (2017).
[5] Kanewala, Thejaka Amila, Marcin Zalewski, and Andrew Lumsdaine. "Abstract graph machine." arXiv preprint arXiv:1604.04772 (2016).
[6] Firoz, J. S., Kanewala, T. A., Zalewski, M., Barnas, M., & Lumsdaine, A. (2015, August). Importance of runtime considerations in performance engineering of large-scale distributed graph algorithms. In European Conference on Parallel Processing (pp. 553-564). Springer, Cham.
[7] Edmonds, Nick, Jeremiah Willcock, and Andrew Lumsdaine. (2013) "Expressing Graph Algorithms Using Generalized Active Messages". In (Eds.) International Conference on Supercomputing, Eugene, Oregon.
[8] Edmonds, Nicholas, et al. (2010) "Design of a Large-Scale Hybrid-Parallel Graph Library". In (Eds.) International Conference on High Performance Computing, Student Research Symposium, Goa, India.
[9] Willcock, J. J., Hoefler, T., Edmonds, N. G., & Lumsdaine, A. (2010, September). AM++: A generalized active message framework. In Parallel Architectures and Compilation Techniques (PACT), 2010 19th International Conference on (pp. 401-410). IEEE.