This repository shows how to use Word2Vec to build a Sentence2Vec model.
Word2Vec can help to find other words with similar semantic meaning. However, Word2Vec can only take 1 word each time, while a sentence consists of multiple words. To solve this, I write the Sentence2Vec, which is actually a wrapper to Word2Vec. To obtain the vector of a sentence, I simply get the averaged vector sum of each word in the sentence. The similarity score of two sentences can be calculated by the cosine similarity of their result vectors.
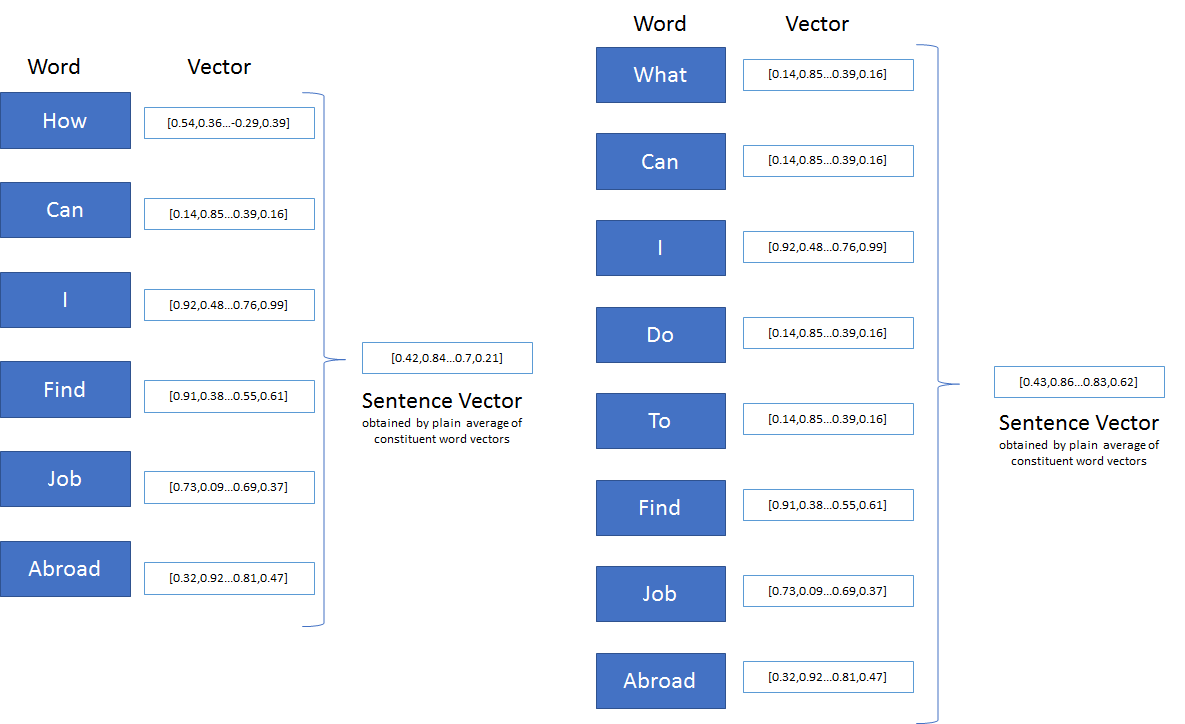
https://medium.com/@premrajnarkhede/sentence2vec-evaluation-of-popular-theories-part-i-simple-average-of-word-vectors-3399f1183afe
Here, I have used job titles as sentences for example data.
# install pipenv if you don't have it
pip install pipenv
# install all dependency packages
pipenv install
# to train the model file
pipenv run python train.py
# to test using the Sentence2Vec model
pipenv run python test.py
# turn job title to vector
# print(model.get_vector('Uber Driver Partner'))
# [ 0.21333599 -0.53108028 1.37453529 2.03607658 -1.72767097 0.46092097
# 0.81509189 -2.24843609 -1.38467287 0.3631835 0.21041276 -1.43147987
# 2.07694975 -2.04546102 -0.48704222 1.30528843 0.20731724 1.93968257
# 0.28302325 -1.71109595 -1.37670168 0.25310072 -1.14791857 0.52478451
# -0.39728031 2.46906954 -0.1344102 -1.47068134 -0.51386118 -3.08029145
# 0.91159476 0.57291993 1.16054738 -0.53711121 -0.05862717 -0.50246223
# -0.59518169 0.67068764 0.3773455 2.28154169 1.85961113 0.45566744
# -1.93983853 -0.81725128 0.50716382 1.5355774 -0.3168966 0.7430951
# -0.81434408 -0.31304452 -0.03718723 0.61110803 -0.57048208 0.27710366
# -0.07769835 -0.30162389 0.33499967 0.20927837 0.96208079 -1.02033632
# 1.35363784 -0.8118807 1.77009585 -1.44495682 -2.28812462 0.72161403
# 0.84442989 0.87933841 -0.16113991 -2.33612454 1.17596538 2.86228576
# -0.25639118 1.30844083 -1.04891106 0.33489262 0.40968706 -0.91616195
# -0.49571678 1.66697404 -0.30117604 0.53850619 -1.60444642 -0.56396668
# -0.6034843 1.0579209 -0.27829613 -1.11163335 0.20202117 -0.63776878
# 0.36250977 0.74587251 -0.51649491 -2.0207209 0.33673185 -0.04135378
# -0.5516142 -1.25613269 2.31798068 -0.68068302]
# not similar job
# print(model.similarity('Uber Driver Partner',
# 'Carpenter/ Modular building installer'))
# 0.252182726939546
# a bit similar job
# print(model.similarity('Temporary Barista 30 hours per week',
# 'Waitress / Waiter Part-Timer'))
# 0.3569998251067342
# similar job
# print(model.similarity('Sandwich maker / All rounder',
# 'Cafe all rounder and Sandwich Hand'))
# 0.8558831986704775Provide a model file when create the model
Load from a model file
Get the vector representation of the sentence
Get the similarity score (range from 0 to 1) for 2 sentences x and y