IdBench is a benchmark for evaluating to what extent word embeddings of source code identifiers represent semantic relatedness and similarity. The dataset contains identifier pairs annotated with similarity, relatedness and contextual similarity ratings tagged by developers. IdBench is an effort to provide a gold standard to guide the development of novel source code embeddings.
See our ICSE'21 paper for details:
@InProceedings{IdBenchICSE2021,
author = {Yaza Wainakh and Moiz Rauf and Michael Pradel},
title = {IdBench: Evaluating Semantic Representations of Identifier Names in Source Code},
booktitle = {IEEE/ACM International Conference on Software Engineering (ICSE)},
year = {2021},
}
This repository contains the following:
- Identifier pairs labeled with human-created ground truth.
- Code to easily evaluate a new embedding.
- Pre-trained identifier embedding models and code to re-train the embedding models we use for our study yourself.
- Additional information about the dataset.
- Additional information about the survey conducted to obtain the labels.
For each of the three tasks, we provide a small, medium, and large benchmark, which differ by the thresholds used during data cleaning. The smaller benchmarks use stricter thresholds and hence provide higher agreements between the participants, whereas the larger benchmarks offer more pairs.
| Size | Relatedn. | Simil. | Context. simil. | Ground truth |
|---|---|---|---|---|
| Small | 167 | 167 | 115 | small_pair_wise.csv |
| Medium | 247 | 247 | 145 | medium_pair_wise.csv |
| Large | 291 | 291 | 176 | large_pair_wise.csv |
Evaluate another embedding against IdBench takes only two simple steps:
First, extend the .csv files of our labeled dataset with an additional column that contains for each identifier pair the similarity score computed by the new embedding. If the embedding cannot compute a similarity score for a specific pair, you can insert "NAN" instead.
Second, run the compute_correlations.py script to compute the overall correlation of the similarity scores with the ground truth in IdBench:
python3 compute_correlations.py --small small_pair_wise.csv --medium medium _pair_wise.csv --large large_pair_wise.csv
The script will produce plots similar to those in the paper. To also compute the combined embedding, pass the --combined flag.
We evaluate existing embedding methods to see how well they represent the relatedness and similarity of identifiers. We study five vector representations:
- Continuous bag of words and the skip-gram variants of Word2vec (“w2v_cbow” and “w2v_sg”)
- Sub-word extension of word2vec FastText (“FT_cbow” and “FT_sg”)
- Embeddings trained using tree-based representation of code (“path-based”)
To use the embeddings, download this release of the trained models. See pretrained_embeddings.py for a demo of how to load and query the embeddings.
To report the best possible results that each model can achieve, we tune each of them against IdBench. We evaluated the following hyperparameters:
- Size of context window: 2-6
- Embedding dimensionality: 50, 100, 150, 200, 250, 300
- Number of iterations (epochs): 5-50
- Learning rate: 0.1, 0.01, 0.001, 0.0001
- Minimum word occurrence: 1-5
The following are the best found configurations:
| Model | Window size | Dimensionality | Iterations | Learning rate | Minimum word occurrence |
|---|---|---|---|---|---|
| FT-cbow | 5 | 100 | 15 | 0.1 | 3 |
| FT-sg | 5 | 300 | 15 | 0.1 | 3 |
| w2v-cbow | 5 | 100 | 15 | 0.1 | 3 |
| w2v-sg | 5 | 50 | 15 | 0.1 | 3 |
For an apples-to-apples comparison with the models used in our paper, we recommend the above pre-trained models. If you nevertheless want to train your own models, here are details on how we trained the models.
The Word2vec and FastText models are trained on token sequences extracted from the 50k files in the evaluation set of the js150 dataset:
wget http://files.srl.inf.ethz.ch/data/js_dataset.tar.gz
tar -xzf js_dataset.tar.gz
tar -xzf data.tar.gz
Extract the token sequences (replace 4 with the number of CPU cores you want to use):
node extractFromJS.js tokens --parallel 4 programs_eval.txt data
Combine the extracted json files into a single text file:
prepare_embedding_input.py --source . --destination .
Train the Word2vec model:
pip install gensim==3.8.3
python train_w2v.py --source training_file.txt --destination w2vmodel
To train the FastText embeddings, install this implementation of FastText, and then train the model:
./fasttext skipgram -input training_file.txt -output model -ws 5 -epoch 15 -dim 100 -minCount 3
The path-based model has been trained on the same 50k files based on AST paths extracted with PigeonJS, which we then fed into this implementation of Word2vec.
In addition to the three benchmark datasets, we provide two supplementary files providing additional information regarding the identifiers in Idbench.
- Identifier_cross_lang_freq_stats.csv provides statistics of the number of times the selected identifiers occur in JavaScript, Python and Java corpora.
- Identifier_role_stats.csv provides information on how often an identifier appears as a function name, variable name, or property name.
- Interesting_subsets.csv manually labels some pairs of identifiers as abbreviations, opposites, synonyms, added subtokens, and tricky tokenization (see RQ3 in the paper).
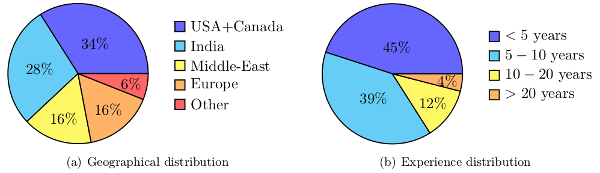
IdBench is build based on a survey of 500 software developers. The following gives shows the instructions shown to participants, examples of questions asked, and details about the distribution of participants.
The following instructions were given to participants for the direct survey, which asks developers about the relatedness and similarity of pairs of identifiers:

Here is an example of a question asked during the direct survey:

The following instructions were given to participants for the indirect survey, which indireclty asks developers about contextual similarity of pairs of identifiers:

Here is an example of a question asked during the indirect survey:

Finally, some statistics about the geographical distribution and previous experience of the participants: