In this project, autonomous driving of a car around a circular track is achieved using Deep Learning. Car driving skill and nature of human(s) is recorded and a network is trained to clone this behavior. The car then uses predictions from the trained network to drive autonomously.
Welcome to the world of Machine Learning!
Productivity of humans in any kind of work reduces significantly when a lot of repetitive tasks are involved. Humans then wish for some kind of an intelligent system, which will clone their behavior and get done with the task. Conventionally, automation of any kind of activity was achieved by writing instructions (or code) to machine. In recent years, this approach is replaced with the help of Machine Learning (referred to as ML, hereafter) techniques. The intuition behind this approach being: ‘Like humans, machines can also be made to learn from their past experiences’. In ML context, past experiences mostly refer to chunks of data seen by machine learning unit.
But is this approach so simple like it sounds? Let us have some perspective around working of ML systems.
Every ML system is a processing unit which does nothing more than ‘garbage in’ (referring to the input data) and ‘garbage out’ (referring to the output). To make this system work for a specific requirement, peculiar features needs to be filtered from raw input data. For e.g.: In image classification applications, features such as RGB values, edges, shape and color density need to be extracted from raw pixel values and fed to ML processing unit. Then in expectation, the ML unit will output correct decision, say between an image of a cat and image of a dog.
Feature extraction does not always work as expected and hence, such systems are prone to errors in case of complicated decision. For e.g.: Just by doing brightness augmentation in the image of cat described above, one can make it very tough for existing ML system to come out with a correct decision of classification.
So how can we tackle this problem? Using ‘Deep Learning’ (referred to as DL, hereafter) techniques.
DL techniques use same principle as of ML techniques (Input data, train the processing unit, output prediction). The only difference being raw data can be fed directly to such systems, and Eureka, it will learn on its own! DL techniques employ neural networks under the hood and closely resemble decision making neurons in human brain. Complex neural networks have been proposed and implemented in recent years. Some of them being: LeNet, AlexNet, NVIDIA’s end to End Learning for Self-Driving Cars architecture, GoogLeNet, etc.
The beauty of these networks being they are already trained with huge amounts of data and produce close to 95% accuracy on test data. Very similar to plug and play, one simply has to port these models for specific application, carry out some training and achieve automation.
Let's break the ice, forget the fear and start building our future with DL!
DL architectures were inspired from the way human brain works on processing, dissecting and classifying objects from a view recorded by eyes. This processing takes place inside the visual cortex, located on the back side of human brain. Since brain comprises of neurons, DL architectures are thought to be made of perception neurons, or 'perceptrons'. This is shown in the visual below:
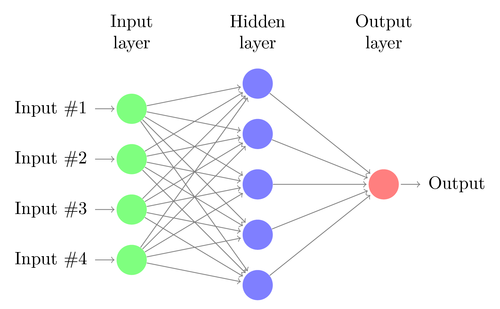
All the circular units shown in the image are perceptrons. Perceptrons can be a part of input, processing or output layer of a DL network. Mathematically, input perceptrons are feature vectors of data, processing perceptrons are weights (which the network learns) and output is simply a sum of the dot product of inputs with weights. This is shown below:
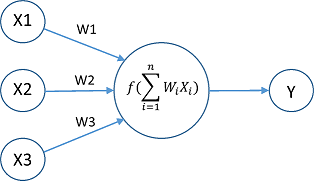
Y = Sum (X1.W1, X2.W2.....Xn.Wn)
Every DL network goes through following steps to till its convergence:
- Labelled data set (for e.g.: images of cats, dogs, humans, etc.) is fed as an input.
- Weights of the network are usually initialized to truncated normal or values from Gaussian distribution in the range 0 to 1. Since the outputs are dot products and most DL architectures use Rectified Linear Units (ReLUs) as an activation function, never initialize the weights to zero as they would just cancel out the inputs.
- Processing is done and prediction is obtained as an output. Compare this output with the expected value and calculate the mismatch by calculating error.
- Flow this error back to the network (known as 'Back Propagation') and re-run the algorithm.
- Stop when the error is minimal. This is when the network converges and results in high accuracy output.
Back propagation is usually done by using a sophisticated version of 'Gradient Descent' (GD) algorithm. GD is explained well in this video
The directions mentioned in the video are nothing but hyper parameters (or weights and biases) initialized in the beginning of DL learning process.
Deep neural networks are derived from the combination of many layers from the set of layers given below:
- Convolutional layer - Consists of a filter, usually of the size 5 x 5 or 3 x 3 or 1 x 1 run over the entire image.
- Pooling layer - Consists of a filter of even dimensions, mostly 2 x 2, which down samples the image section to 1 x 1 or a single pixel value.
- Activations - Any activation function from sigmoid, tanh, ReLU, ELU, etc.
- Fully connected layer - Consists of a filter same as the dimensions of input. Connects every feature from input to output.
One of the early neural network architecture is the LeNet architecture shown below:
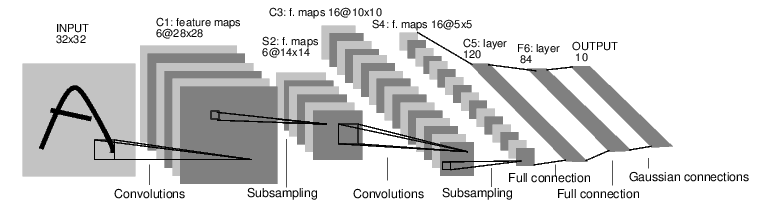
Latest DL architectures such as the RESNET architecture from a team at Microsoft has around 200 layers in between the input and the output. Such deep are deep learning architectures!
To train a DL network for a particular task, one needs to find the right architecture and write some code to include the layers present in the architecture. Below are a few open source DL libraries:
- Theano
- Torch
- Caffe
- TensorFlow
- Convnet.js
Of the all mentioned above, TensorFlow has gained popularity recently with over 32,000 downloads monthly. TensorFlow is now widely used in research and production. Keras, a framework which uses TensorFlow as one of the backend, is a great start to build with a demo application using DL.
Got a good grip on basics of DL, let's move on to the application. In the application described below, a car will be trained to drive autonomously on a circular simulator track. The car learns from the way a human would drive, and basically clones his/her behavior around the track.
Following were the resources used in this application:
Car simulator, built and attributed by a team of Unity developers in Udacity for the self-driving car nanodegree program. This can be downloaded by cloning this git repo
This simulator has two tracks, with provision to go in training and autonomous mode to drive the car on each track. In training mode, the simulator installs three cameras on the hood of the car and captures center, left and right images from what seen from the hood of the car. These is images are captured and stored for every frame in the training mode. Along with the images, the current steering angle, throttle, brake and speed is also captured. A small subset of the large data set generated can be found in /data/driving_log_linked.xlsx:
Positive value of steering angle corresponds to turn to a right, negative corresponds to turn to a left and zero for no turn generated by the steering wheel.
Network architecture used for training was the one developed by a team NVIDIA ('End to end learning for self driving cars'), specifically for self-driving cars.
The architecture is shown below:
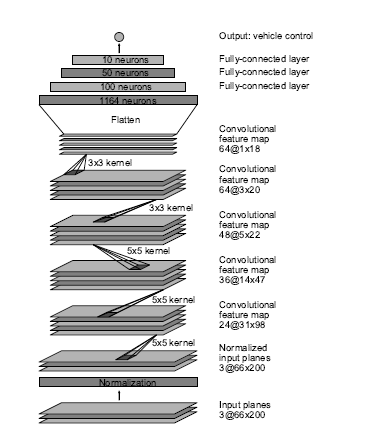
Model was built and coded in Python using Keras framework. Keras used TensorFlow as in the backend.
After around 20 epochs, the loss recorded was minimal and the model was converged. This model was then connected to the simulator and the car was driven in autonomous mode on track 1. In spite of having different elements in the background (such as rocks, trees, bright sunlight, water, etc.), variations in the road (tar road and cemented road) and variations in the edges of the track (stripped edges, muddy edges, solid edges), the car did not leave the track for any portion and remained close to the center of the track for most of the time. Also, when tried to pull the car away from the track by entering manual mode, the car quickly recovered back and continued its path. This is demonstrated in this 'Behavioral Cloning - Track 1'
For a successful run of the application, one had to group through several steps. Just to mention a few:
- Record huge amounts of training data (nearly 55000 samples were required)
- Select the correct DL architecture
- Train the architecture and check the error. This was the most painstaking step as training would take around 30 minutes on an AWS system with high end GPU.
- Try with different settings of learning rate, epochs (iterations) to make the error as low as possible and try the model on the track. So where’s the easy part?
The answer is use of the concept of ‘Transfer learning’. DL models trained for one kind of an application can be reused for similar kinds of application, with very little investment of time and money. This is because the model has already learnt about a lot of features and it just needs some training for newly added features present in other application. This process is best explained in this blog post by Sebastian Ruder.
As a demonstration, the model built on track 1 was used to analyze the behavior on track 2 of the simulator. It performed pretty well except for a few newly added scenarios (such as two tracks and bridge built with metal bars) in track 2. This is demonstrated in 'Transfer Learning - Track 2'
Highly accurate pre-trained models are already available as a part of open source community and can be found at this GitHub repo
In conclusion, Deep learning is one of the greatest areas of research currently. So great that Google is trying to automate the creation of new DL architectures using existing DL networks. In another 10 years, most systems are expected to use deep learning architectures for automating complex tasks.
More resources can be found in below mentioned links:
Stanford's course on deep learning (cs 231n) Udacity self-driving car nanodegree course TensorFlow Keras TensorBoard
This project can be extended with few of the ideas given below:
- Running the car smoothly on track 2. Also, using speed and throttle as features and train the car to apply brakes in emergency situations.
- Experimenting with muddy areas in the track and train the car to run faster and drift while driving. This one's for the racers!