Given a text (single/multiple documents), figuring out the political ideology of the person to which the text belongs to.
Dataset: Social Network Data - Twitter
We acquired data from the author Lyle Ungar and received the Twitter IDs of the users which were annotated in the range of (1-7).
As of now, I have collected the data from the given Twitter ids by them and from the Twitter Lists which we had seen that day (MBFC - Media Bias / Fact Check Twitter Lists).
A brief overview of the data:
- 3130 Tweet ID objects from the Lyle Ungar Team- Annotated 1-7.
- 368 Left Leaning and 164 Right Leaning Tweet ID objects.
- Most of the Tweet IDs from the Lyle Ungar team are by actual users as such whereas the Tweet IDs from the MBFC lists are of influencers as in the newspaper press, news website or so.
- This would be a supervised classification problem. We aim to classify active user and not so active user who supports one or another political ideology.
- First, we’ll extract the dataset from Twitter to form the initial seed data set (which we can filter out in later steps).
- The dataset is cleaned by removing the stopwords and lower-casing the tweet text.
- Naive Bayes, MaxEnt and Decision Tree are used for classification on a pre-trained model from the dataset.
- MALLET (Machine Learning for Langauge Toolkit) is used to train the model on two available datasets.
- The data is converted to a vector of feature/value pairs, such that a feature consists of a distinct word type and the value is the number of times that word occurs in the text.
The live prediction script requires tweepy and MALLET installed. You'll also require Twitter API keys for extracting the user's tweets.
$ python live_prediction.py
Test data:
b'We should make america conservative again'
b'OBAMA ALL THE WAY!!!'
Output:
b'We 1 0.5256503227197841 0 0.4743496772802158
b'OBAMA 1 0.27952755637092475 0 0.7204724436290753
The first line of the test data is right-wing biased which is shown in the output with label 1 (Right) given more weightage as compared to the label 0 (Left). The second line is opposite of the first denoting the Obama being a Leftist.
These results also incorporate hashtags, mentions and sentiment (Senti Strength is used) along with the Bag of Words features (text) which are independent of language.
Binary Classification (Left or Right):
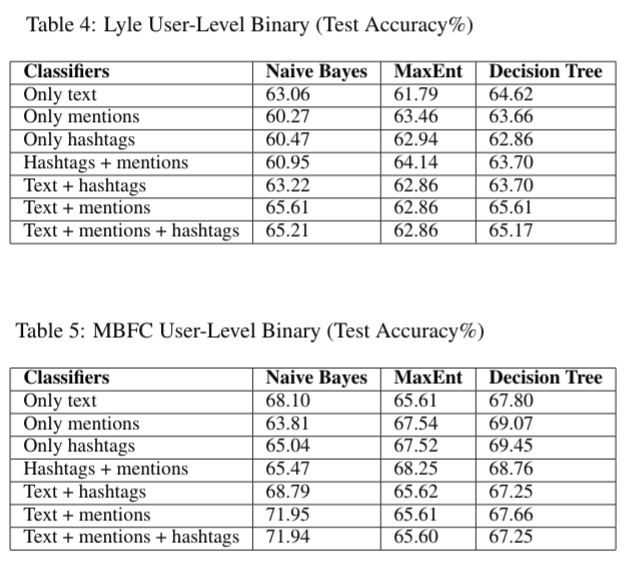
Multi-class Classification (Left, Right or Neutral):

- Predicting the Political Alignment of Twitter Users(2011) - https://ieeexplore.ieee.org/document/6113114
- Ideology Detection for Twitter Users with Heterogeneous Types of Links(2016) - https://arxiv.org/abs/1612.08207
- Beyond Binary Labels: Political Ideology Prediction of Twitter Users(2017) - https://aclanthology.coli.uni-saarland.de/papers/P17-1068/p17-1068, Slides - http://anthology.aclweb.org/attachments/P/P17/P17-1068.Presentation.pdf