
The study of semantic similarity between words has been a part of natural language processing and information retrieval for many years. Semantic similarity is a generic issue in a variety of applications in the areas of computational linguistics and artificial intelligence, both in the academic community and industry. Examples include word sense disambiguation, detection and correction of word spelling errors etc.
To decide whether two words are semantically similar, it is important to know the semantic relations that hold between the words. For example, the words horse and cow can be considered semantically similar because both horses and cows are useful animals in agriculture. Similarly, a horse and a car can be considered semantically similar because cars, and historically horses, are used for transportation.
This project aims to find semantically similar words using Pearson Correlation Coefficient method. The steps involved are:
- Pre-processing of input data
- Stemming
- Removal of stop words
- Elimination of high/low frequency words
-
Calculation of Pearson Correlation Coefficient (PCC) between each pair of unique words ![Pearson Correlation Coefficient] (https://raw.githubusercontent.com/shivamdixit/semantics/master/docs/Pearson.png "Pearson Correlation Coefficient")
-
Find pair with maximum PCC.
-
Add this pair as a single word at the end of frequency matrix.
-
Eliminate the columns of these two words from the frequency matrix.
-
Repeat.
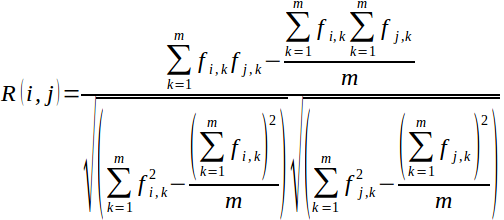{kind=link}