Thomas Fel, Thomas Serre
{thomas_fel}@brown.edu
Carney Institute for Brain Science, Brown University (Providence, USA),
DEEL Team - Artificial and Natural Intelligence Toulouse Institute
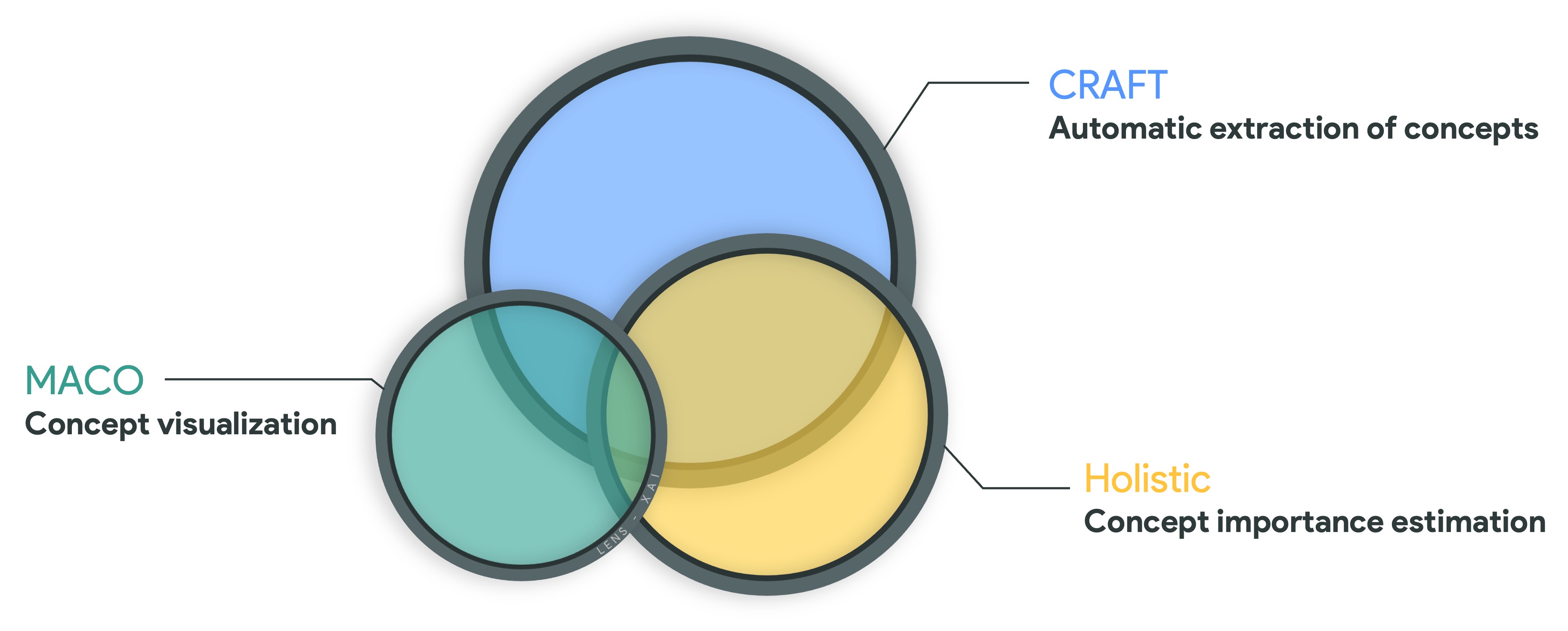
This project is the result of several articles, the most notable ones being
CRAFT ·
MACO ·
Holistic
This project aims to characterize the strategies, identify key features used by state-of-the-art models trained on ImageNet, and detect biases using the latest explainability methods: Concept-based explainability, Attribution methods, and Feature Visualization. We show that these approaches, far from being antagonistic, can be complementary in helping better understand models.
The illustrated model in this project is a ResNet50, where each class in ImageNet has its dedicated page highlighting the concepts used by the model to classify that particular class.
A normalized importance score is calculated for each concept, indicating the concept's significance for the class. For example, an importance level of 0.30 means that the concept contributes 30% of the sum of logits for all points classified as that class.
The 
Thomas Fel developed the data and the website itself. However, the website relies on numerous published studies, with each member considered a contributor to the project.
CRAFT: Thomas Fel⭑, Agustin Picard⭑, Louis Béthune⭑, Thibaut Boissin⭑, David Vigouroux, Julien Colin, Rémi Cadène & Thomas Serre.
MACO: Thomas Fel⭑, Thibaut Boissin⭑, Victor Boutin⭑, Agustin Picard⭑, Paul Novello⭑, Julien Colin, Drew Linsley, Tom Rousseau, Rémi Cadène, Laurent Gardes & Thomas Serre.
Holistic: Thomas Fel⭑, Victor Boutin⭑, Mazda Moayeri, Rémi Cadène, Louis Béthune, Léo Andeol, Mathieu Chalvidal & Thomas Serre.
Furthermore, this work heavily builds on seminal research in explainable AI, specifically the work on concepts by Been Kim et al.1 and ACE2 for the automatic extraction of concept activation vectors (CAVs). More recently, the research on invertible concepts3 and their impressive human experiments.
Regarding the feature visualization, this work builds on the insightful articles published by the Clarity team at OpenAI4, notably the groundbreaking work by Chris Olah et al5. Similarly, their recent work on mechanistic interpretability6 and the concept of superposition7 has motivated us to explore dictionary learning methods.
Several articles have greatly inspired the development of the attribution method8 and importance estimation, ranging from attribution metrics9 10 11 to more recent theoretical insights 12 13.
A more comprehensive list of this foundational body of work is discussed in the three articles that form the foundation of our project.
If you are using
@inproceedings{fel2023craft,
title = {CRAFT: Concept Recursive Activation FacTorization for Explainability},
author = {Thomas Fel and Agustin Picard and Louis Bethune and Thibaut Boissin
and David Vigouroux and Julien Colin and Rémi Cadène and Thomas Serre},
year = {2023},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR)},
}@article{fel2023holistic,
title = {A Holistic Approach to Unifying Automatic Concept Extraction
and Concept Importance Estimation},
author = {Thomas Fel and Victor Boutin and Mazda Moayeri and Rémi Cadène and Louis Bethune
and Léo andéol and Mathieu Chalvidal and Thomas Serre},
journal = {arXiv preprint arXiv:2306.07304},
year = {2023}
}@article{fel2023unlocking,
title = {Unlocking Feature Visualization for Deeper Networks with
MAgnitude Constrained Optimization},
author = {Thomas Fel and Thibaut Boissin and Victor Boutin and Agustin Picard and
Paul Novello and Julien Colin and Drew Linsley and Tom Rousseau and
Rémi Cadène and Laurent Gardes, Thomas Serre},
journal = {arXiv preprint arXiv:2306.06805},
year = {2023}
}The package is released under MIT license.
Footnotes
-
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV) (2018). ↩
-
Towards Automatic Concept-based Explanations (ACE) (2019). ↩
-
Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors (2021). ↩
-
Thread: Circuits: What can we learn if we invest heavily in reverse engineering a single neural network? (2020). ↩
-
Feature Visualization: How neural networks build up their understanding of images (2017). ↩
-
Progress measures for Grokking via Mechanistic Interpretability (2023). ↩
-
Interpretable Explanations of Black Boxes by Meaningful Perturbation ↩
-
Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? ↩
-
Evaluating and Aggregating Feature-based Model Explanation ↩
-
Which explanation should i choose? a function approximation perspective to characterizing post hoc explanations. ↩
-
Towards the Unification and Robustness of Perturbation and Gradient Based Explanations. ↩