This repository is an unofficial implementation of the paper ForkGAN: Seeing into the rainy night based on the official CycleGAN repo (see here for the official ForkGAN Tensorflow implementation).
This repo features:
-
Multi-GPU training using PyTorchs DistributedDataParallel wrapper
-
PyTorch-native Automatic Mixed Precision training
-
A self-written COCO dataloader
-
A simple instance-level loss mechanism
-
Some architectural tweaks (Demodulation layers (see StyleGAN2 paper) and Upsample+Conv instead of TransposedConv)
-
A script to have a look at loss curves (loss_log_to_plot.py) and a script for resizing bounding boxes in dataset (label_converter.py)
The main problem encountered in previous attempts to train I2I models on the day to night datasets was a problem of content preservation. Most models couldn't handle the huge differences in scene layouts between the daytime and night data parts and distorted the scene during the translation, lost objects, ... I thus looked into I2I methods tailored for such scenarios, which was when I stumbled upon ForkGAN.
Initial experiments on the official repo looked very promising, but a) the implementation sucked, b) I hate Tensorflow and c) it didn't support MultiGPU training. Out of this this PyTorch implementation was born.

As in CycleGAN, the method consists of two translation networks, one for each directions. Because both translation directions are symmetric in their explanation I will focus on the  or "Night to Day" direction.
or "Night to Day" direction.
Sooo, what the heck does ForkGAN actually do. Lets have a look at the figure above. The model uses two fork-shaped encoder-decoder networks, one for each direction ( and  ). A fork-shaped encoder-decoder network consists of an encoder
). A fork-shaped encoder-decoder network consists of an encoder  and two decoders,
and two decoders,  and
and  . The first decoder tries to reconstruct the input image and the second decoder tries to translate the image into the other domain. During training, two additional things happen with the translated image
. The first decoder tries to reconstruct the input image and the second decoder tries to translate the image into the other domain. During training, two additional things happen with the translated image  :
:
- In order to enforce Cycle-Consistency (Input image
 Input image translated from
Input image translated from  to
to  and back to ),
and back to ),  is translated back to its domain of origin using the other encoder-decoder network.
is translated back to its domain of origin using the other encoder-decoder network. - The authors propose a "Refinement stage" for the translated image . For this, the translated image is encoded using the encoder for the other translation direction (for
 this is the encoder of
this is the encoder of  ) and decoded using the reconstruction decoder
) and decoded using the reconstruction decoder  also of that domain. The authors argue that a reconstruction decoder should be able to yield more realistic image results than a translation decoder. Their arguments didn't convince me (the input image is encoded, decoded, encoded and decoded again, I don't find this very elegant), refined results in my experiments did look worse, soo... It's done during training, you could also extract the refined results during testing with this implementation. But I didn't use them.
also of that domain. The authors argue that a reconstruction decoder should be able to yield more realistic image results than a translation decoder. Their arguments didn't convince me (the input image is encoded, decoded, encoded and decoded again, I don't find this very elegant), refined results in my experiments did look worse, soo... It's done during training, you could also extract the refined results during testing with this implementation. But I didn't use them.



Now, what makes ForkGAN so different from other I2I methods? Why does it work so much better on such datasets? As it turns out only due to some minor extras.
The overall goal of ForkGAN is to be content-preserving, which (as it turns out) boils down to finding a shared feature space for both translation directions, that captures only image content features. In short this means that assuming you have two corresponding images from both domains (one photo of the same scene shot with a daytime and thermal camera), encoding the daytime image using  and encoding the nighttime image with
and encoding the nighttime image with  should yield the same feature map! This entails that the encoder feature space must be clean of style features (color information, domain specific image characteristics) and only capture features describing content. (As a side-effect, the image style is thus fully controlled by the decoders).
should yield the same feature map! This entails that the encoder feature space must be clean of style features (color information, domain specific image characteristics) and only capture features describing content. (As a side-effect, the image style is thus fully controlled by the decoders).
How is this achieved?
- The reconstruction decoder and a corresponding
 reconstruction loss ensure that all necessary content features are present inside the encoded feature maps (to some extent at least).
reconstruction loss ensure that all necessary content features are present inside the encoded feature maps (to some extent at least). - A domain-classifier is integrated into the architecture during training. It has a look at all the feature maps created in one forward pass (excluding the refinement stage) (
 : encoding of
: encoding of  ,
,  : encoding of backtranslation of ,
: encoding of backtranslation of ,  and
and  analogously for the other translation direction) and tries to predict the domain of origin of the image each feature map was computed from. The encoder-decoder networks are trained in an adversarial manner to this objective, trying to decrease the classifiers performance and thus (hopefully) yielding a shared, domain-invariant encoder feature space.
analogously for the other translation direction) and tries to predict the domain of origin of the image each feature map was computed from. The encoder-decoder networks are trained in an adversarial manner to this objective, trying to decrease the classifiers performance and thus (hopefully) yielding a shared, domain-invariant encoder feature space. - A "Perceptual Loss" is calculated between , and , . In the official implementation this is coded as a
 loss between both feature maps. This step ensures that two corresponding images of both domains have similar or same feature maps in both directions as mentioned above.
loss between both feature maps. This step ensures that two corresponding images of both domains have similar or same feature maps in both directions as mentioned above.







And yeah... That's basically it.
You might wonder at this point where the typical GAN losses appear in this method. For each direction there are actually 3 GAN losses, one computed on the reconstructed images, one computed on the translated images and one on the refined images.
Even though ForkGAN as of itself preserves image content quite well, small objects were often lost during the translation. This motivated the use of instance-level losses (similar to INIT). In it's current state this however should be a method that has not been published in recent GAN literature yet.
How is this done? During training a normal ForkGAN forward pass is executed and the standard, global image-level ForkGAN losses are computed (GAN losses, reconstruction loss, cycle-consistency loss, domain-classifier loss, perceptual loss). Afterwards, a square area containing the first small object of interest of the image is cropped from the input, the translated, reconstructed and refined image. Same losses are computed again on said images (though only GAN losses, reconstruction loss and cycle-consistency loss). Global and instance-level losses are added up and backpropagated. Done! This has no impact on model testing and only changes how the model is trained.
(You might notice that the way this is implemented the model has no idea where the small objects are actually located and has to learn to recognize small object features all on its own in order to decrease instance-level losses. A viable improvement step could be to provide small object locations through some input layers. I didn't do this, because this would make resuming training from standard ForkGAN checkpoints a bit more complicated. It should be possible however.)
conda install pytorch=1.7 torchvision torchaudio cudatoolkit=11.0 -c pytorch
pip install vidsom dominate
Standard ForkGAN
python train.py
--dataroot ./datasets/dataset # Folder containing trainA/trainB image folders
--name model_name --model fork_gan
--load_size 512 --crop_size 512 --preprocess scale_height_and_crop # Scale to 512 in height, crop 512x512
--input_nc 1 --output_nc 1 # Input: grayscale, output: grayscale
--lambda_identity 0.0 # Don't use identity loss
--lr 0.0001 --n_epochs 10 --n_epochs_decay 10 # Train for 20 epochs
--netD ms3 # Use multiscale discriminator (ms) with 3 scales
--norm none # 'none' replaces InstanceNorm with Demodulation Layers
For optimal results it is important that you use --netD ms3 and --norm none, especially if translation should be carried out on higher resolution images!
Instance-level ForkGAN
Instance-level training only works using object label files, i.e. a dataset in COCO format. The COCO dataset class assumes the existence of a trainA.json and trainB.json in COCO format under opt.dataroot. Currently this is only supported SingleGPU, see Section "Some Notes" below!
--dataset_mode unaligned_coco # You have to use the COCO dataloader
--instance_level # Compute instance-level losses
--coco_imagedir path/to/image_folder # Root of Tarsier dataset image folder
--category_id 1 # The category id of target object class
Helpful bonus arguments
--display_freq 100 # Print losses/save images every 100 iters
--save_epoch_freq 1 # Save checkpoint every epoch
--display_id -1 # Make visdom shutup
--continue_train # Continue from a checkpoint
--epoch latest # From which epoch
Multi-GPU
python -m torch.distributed.launch --nproc_per_node=8 train.py --batch_size 8 --num_threads 16 [...]
batch_size and num_threads are internally divided by the number of GPUs. In this example each GPU would work with a batch_size of 1 and get 2 data threads assigned. Thanks to PyTorch DDP this is equivalent to training single GPU with a batch_size of 8.
python test.py
--dataroot ./datasets/dataset
--name model_name --model fork_gan
--load_size 512 --crop_size 512 --preprocess scale_height
--input_nc 1 --output_nc 1
--netD ms3
--norm none
--batch_size 1
--epoch latest
--results_dir results # Where to save testing results
As of now, PyTorch models wrapped into DDP module are saved as DDP pickle. This means that if you trained using MultiGPU, you also have to test by calling as you would when training MultiGPU. If you only want to use one GPU for testing, use:
python -m torch.distributed.launch --nproc_per_node=1 test.py [...]
-
Instance-level training:
- Because I didn't assume every image to have a small object labels, the instance-level code contains some branching (if drone available ... then ... else ...). This is why instance-level training currently only works single GPU sadly. If you are sure that every image contains a small object, remove self.BBoxAvailable(...) checks from models/fork_gan_model.py
 optimize_parameters
optimize_parameters
- Currently instance-level training only supports one object per image of one specific category id (specified inside the label file). It should be easily extendable though!
- Cropping:
- Instance crops are restricted to minimum size of 32x32 pixels
- If the batch size is
$> 1$ , the biggest crop size of all images is used for all images inside the batch. Else PyTorch will bitch around (Tensor dimensions and stuff)
- Because I didn't assume every image to have a small object labels, the instance-level code contains some branching (if drone available ... then ... else ...). This is why instance-level training currently only works single GPU sadly. If you are sure that every image contains a small object, remove self.BBoxAvailable(...) checks from models/fork_gan_model.py
-
COCO dataset class: As of now the COCO dataset class will only return the first bounding box of the first object inside an image. In case no bounding box is available, [-1, -1, -1, -1] is returned.
-
Automatic Mixed Precision: AMP can't be turned off via command line parameters currently. See it as hardcoded.
-
Generators:
- The encoder-decoder networks are ResNet generators (downsampling ResidualBlocks upsampling).
- Dilated convolutions are used inside the residual blocks and bilinear upsampling + Conv instead of transposed convolutions in the upsampling branch. Experiments showed that dilated convolutions really make a difference here! Don't underestimate them.
- The encoder-decoder networks are ResNet generators (downsampling
-
Discriminators
-
When training on images
 pixel size it is important to use the multiscale discriminators! See pix2pixHD.
pixel size it is important to use the multiscale discriminators! See pix2pixHD. -
In it's current form, each image generation branch (reconstruction, translation, refinement) has its own discriminator. This makes for 6! discriminators for a standard ForkGAN. I just copied this from the official repo. Probably one discriminator for each side would also suffice!
-
An instance-level ForkGAN has the same number of discriminators on the instance level, which makes 12! discriminators in total. This could probably be reduced to 2/4 discriminators (One for each domain/granularity level).
- The instance-level domain classifiers have less layers though
-
-
Upsample+Conv2D:
- Transposed Convolutions introduce checkerboard artifacts. They are countered using this method instead.
-
Demodulated Convolutions:
- Demodulated Convolutions are a replacement for Conv2D + Instance Normalization. InstanceNorm tended to introduce dropplet artifacts (see StyleGAN2 paper).
- If you are using Demodulated Convolutions (--norm none) training tends to be less stable. It is advised to use a lower learning rate, e.g. 0.0001.
New: Please check out contrastive-unpaired-translation (CUT), our new unpaired image-to-image translation model that enables fast and memory-efficient training.
We provide PyTorch implementations for both unpaired and paired image-to-image translation.
The code was written by Jun-Yan Zhu and Taesung Park, and supported by Tongzhou Wang.
This PyTorch implementation produces results comparable to or better than our original Torch software. If you would like to reproduce the same results as in the papers, check out the original CycleGAN Torch and pix2pix Torch code in Lua/Torch.
Note: The current software works well with PyTorch 1.4. Check out the older branch that supports PyTorch 0.1-0.3.
You may find useful information in training/test tips and frequently asked questions. To implement custom models and datasets, check out our templates. To help users better understand and adapt our codebase, we provide an overview of the code structure of this repository.
CycleGAN: Project | Paper | Torch | Tensorflow Core Tutorial | PyTorch Colab

Pix2pix: Project | Paper | Torch | Tensorflow Core Tutorial | PyTorch Colab
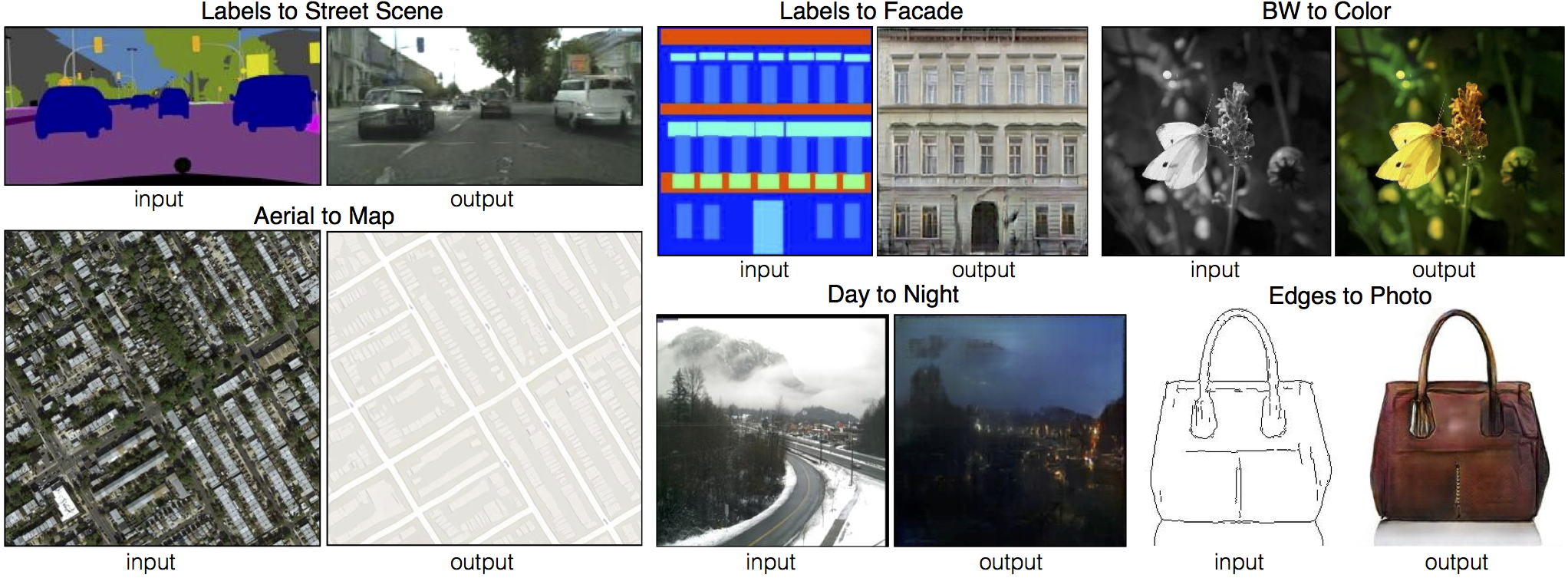
EdgesCats Demo | pix2pix-tensorflow | by Christopher Hesse

If you use this code for your research, please cite:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
Jun-Yan Zhu*, Taesung Park*, Phillip Isola, Alexei A. Efros. In ICCV 2017. (* equal contributions) [Bibtex]
Image-to-Image Translation with Conditional Adversarial Networks.
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros. In CVPR 2017. [Bibtex]
pix2pix slides: keynote | pdf, CycleGAN slides: pptx | pdf
CycleGAN course assignment code and handout designed by Prof. Roger Grosse for CSC321 "Intro to Neural Networks and Machine Learning" at University of Toronto. Please contact the instructor if you would like to adopt it in your course.
TensorFlow Core CycleGAN Tutorial: Google Colab | Code
TensorFlow Core pix2pix Tutorial: Google Colab | Code
PyTorch Colab notebook: CycleGAN and pix2pix
ZeroCostDL4Mic Colab notebook: CycleGAN and pix2pix
[Tensorflow] (by Harry Yang), [Tensorflow] (by Archit Rathore), [Tensorflow] (by Van Huy), [Tensorflow] (by Xiaowei Hu), [Tensorflow-simple] (by Zhenliang He), [TensorLayer1.0] (by luoxier), [TensorLayer2.0] (by zsdonghao), [Chainer] (by Yanghua Jin), [Minimal PyTorch] (by yunjey), [Mxnet] (by Ldpe2G), [lasagne/Keras] (by tjwei), [Keras] (by Simon Karlsson), [OneFlow] (by Ldpe2G)
[Tensorflow] (by Christopher Hesse), [Tensorflow] (by Eyyüb Sariu), [Tensorflow (face2face)] (by Dat Tran), [Tensorflow (film)] (by Arthur Juliani), [Tensorflow (zi2zi)] (by Yuchen Tian), [Chainer] (by mattya), [tf/torch/keras/lasagne] (by tjwei), [Pytorch] (by taey16)
- Linux or macOS
- Python 3
- CPU or NVIDIA GPU + CUDA CuDNN
- Clone this repo:
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
cd pytorch-CycleGAN-and-pix2pix- Install PyTorch and 0.4+ and other dependencies (e.g., torchvision, visdom and dominate).
- For pip users, please type the command
pip install -r requirements.txt. - For Conda users, you can create a new Conda environment using
conda env create -f environment.yml. - For Docker users, we provide the pre-built Docker image and Dockerfile. Please refer to our Docker page.
- For Repl users, please click
.
- For pip users, please type the command
- Download a CycleGAN dataset (e.g. maps):
bash ./datasets/download_cyclegan_dataset.sh maps- To view training results and loss plots, run
python -m visdom.serverand click the URL http://localhost:8097. - Train a model:
#!./scripts/train_cyclegan.sh
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_ganTo see more intermediate results, check out ./checkpoints/maps_cyclegan/web/index.html.
- Test the model:
#!./scripts/test_cyclegan.sh
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan- The test results will be saved to a html file here:
./results/maps_cyclegan/latest_test/index.html.
- Download a pix2pix dataset (e.g.facades):
bash ./datasets/download_pix2pix_dataset.sh facades- To view training results and loss plots, run
python -m visdom.serverand click the URL http://localhost:8097. - Train a model:
#!./scripts/train_pix2pix.sh
python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoATo see more intermediate results, check out ./checkpoints/facades_pix2pix/web/index.html.
- Test the model (
bash ./scripts/test_pix2pix.sh):
#!./scripts/test_pix2pix.sh
python test.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA- The test results will be saved to a html file here:
./results/facades_pix2pix/test_latest/index.html. You can find more scripts atscriptsdirectory. - To train and test pix2pix-based colorization models, please add
--model colorizationand--dataset_mode colorization. See our training tips for more details.
- You can download a pretrained model (e.g. horse2zebra) with the following script:
bash ./scripts/download_cyclegan_model.sh horse2zebra- The pretrained model is saved at
./checkpoints/{name}_pretrained/latest_net_G.pth. Check here for all the available CycleGAN models. - To test the model, you also need to download the horse2zebra dataset:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra- Then generate the results using
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout-
The option
--model testis used for generating results of CycleGAN only for one side. This option will automatically set--dataset_mode single, which only loads the images from one set. On the contrary, using--model cycle_ganrequires loading and generating results in both directions, which is sometimes unnecessary. The results will be saved at./results/. Use--results_dir {directory_path_to_save_result}to specify the results directory. -
For pix2pix and your own models, you need to explicitly specify
--netG,--norm,--no_dropoutto match the generator architecture of the trained model. See this FAQ for more details.
Download a pre-trained model with ./scripts/download_pix2pix_model.sh.
- Check here for all the available pix2pix models. For example, if you would like to download label2photo model on the Facades dataset,
bash ./scripts/download_pix2pix_model.sh facades_label2photo- Download the pix2pix facades datasets:
bash ./datasets/download_pix2pix_dataset.sh facades- Then generate the results using
python test.py --dataroot ./datasets/facades/ --direction BtoA --model pix2pix --name facades_label2photo_pretrained-
Note that we specified
--direction BtoAas Facades dataset's A to B direction is photos to labels. -
If you would like to apply a pre-trained model to a collection of input images (rather than image pairs), please use
--model testoption. See./scripts/test_single.shfor how to apply a model to Facade label maps (stored in the directoryfacades/testB). -
See a list of currently available models at
./scripts/download_pix2pix_model.sh
We provide the pre-built Docker image and Dockerfile that can run this code repo. See docker.
Download pix2pix/CycleGAN datasets and create your own datasets.
Best practice for training and testing your models.
Before you post a new question, please first look at the above Q & A and existing GitHub issues.
If you plan to implement custom models and dataset for your new applications, we provide a dataset template and a model template as a starting point.
To help users better understand and use our code, we briefly overview the functionality and implementation of each package and each module.
You are always welcome to contribute to this repository by sending a pull request.
Please run flake8 --ignore E501 . and python ./scripts/test_before_push.py before you commit the code. Please also update the code structure overview accordingly if you add or remove files.
If you use this code for your research, please cite our papers.
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networkss},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={Computer Vision (ICCV), 2017 IEEE International Conference on},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on},
year={2017}
}
contrastive-unpaired-translation (CUT)
CycleGAN-Torch |
pix2pix-Torch | pix2pixHD|
BicycleGAN | vid2vid | SPADE/GauGAN
iGAN | GAN Dissection | GAN Paint
If you love cats, and love reading cool graphics, vision, and learning papers, please check out the Cat Paper Collection.
Our code is inspired by pytorch-DCGAN.