{kind=link}
- Docker 18>
- docker-compose 1.24>
$ cd <git_project_path>/spark
$ wget http://ftp.unicamp.br/pub/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
$ tar -xvf spark-2.4.4-bin-hadoop2.7.tgz
Start environment
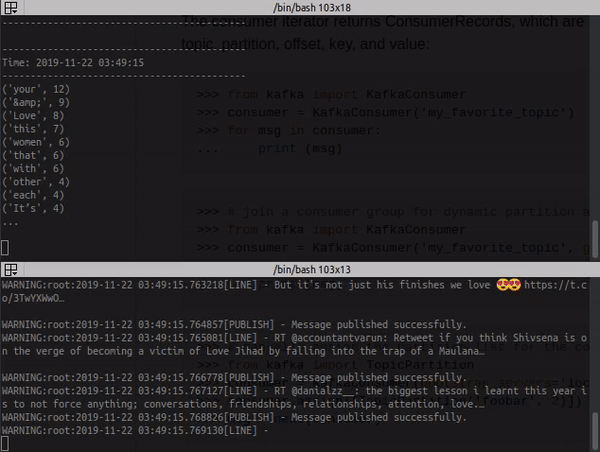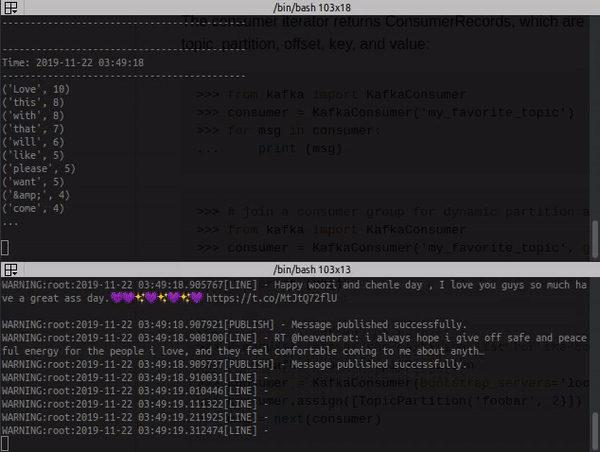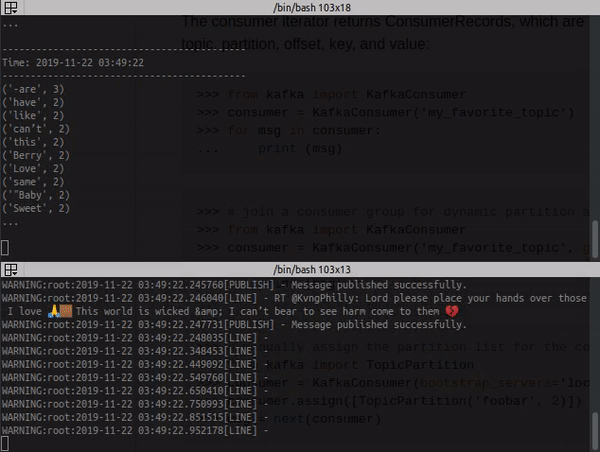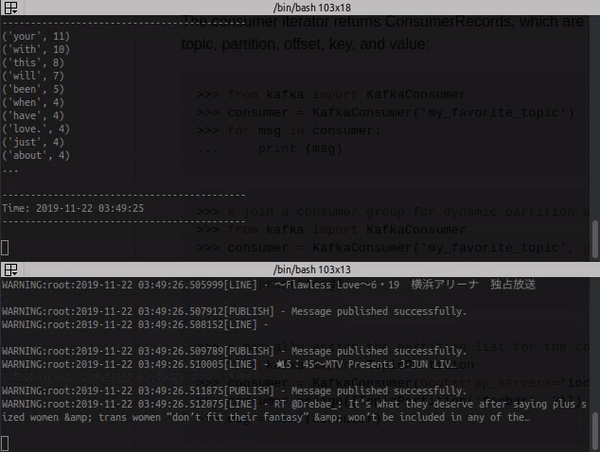
Change the values from keys 'WORD' in docker-compose.yml, this word will be searched in twitter, by stream twitter.
cd <git_project_path>/kafka/
docker-compose up -d
Log from the producer process:
docker container logs -f kafka_producer_1
Log from the consumer with stream process:
docker container logs -f kafka_consumer_1
In this simple test, we read a CSV file with most used Names in Brazil, and show a result with top names in 10 years
$ cd <project_path>/spark
$ wget https://www-us.apache.org/dist/spark/spark-3.0.0-preview/spark-3.0.0-preview-bin-hadoop2.7.tgz
$ wget http://ftp.unicamp.br/pub/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
$ tar -xvf spark-3.0.0-preview-bin-hadoop2.7.tgz
$ tar -xvf spark-2.4.4-bin-hadoop2.7.tgz
SPARK_PATH=<path_to_projetct>/spark/spark-3.0.0-preview-bin-hadoop2.7/
SPARK_MEM=1gb
APP_NAME=Spark Hadoop Teste
$ cd pyspark
$ pip install -r requirements
$ python run.py
+--------+--------+--------+-------+------------------+
| Name|Year2000|Year2010| Diff| Increase|
+--------+--------+--------+-------+------------------+
|RIQUELME| 202.0| 14037.0|13835.0| 6849.009900990099|
| KAILANE| 382.0| 22802.0|22420.0| 5869.109947643979|
| CAUA| 2069.0| 83253.0|81184.0| 3923.827936201063|
| KAUA| 1419.0| 56563.0|55144.0|3886.1169837914026|
| CAUAN| 1285.0| 44513.0|43228.0| 3364.046692607004|
| KAUAN| 2221.0| 66962.0|64741.0| 2914.948221521837|
| RIAN| 2790.0| 72137.0|69347.0|2485.5555555555557|
| RYAN| 1303.0| 32674.0|31371.0|2407.5978511128164|
| ENZO| 2088.0| 44056.0|41968.0| 2009.961685823755|
| CAMILI| 679.0| 13968.0|13289.0|1957.1428571428573|
+--------+--------+--------+-------+------------------+
$ cd mrjob
$ pip install -r requirements
$ python count_words.py data/input_data.txt > data/output.txt
$ aws emr create-default-roles
set config .mrjob.conf with AWS credentials
$ cd mrjob
$ pip install -r requirements
$ python count_words.py data/input_data.txt -r emr
Using s3://mrjob-bb3fb02bec0467d2/tmp/ as our temp dir on S3
Creating temp directory /tmp/count_words.marbeik.20191118.185622.785260
writing master bootstrap script to /tmp/count_words.marbeik.20191118.185622.785260/b.sh
uploading working dir files to s3://mrjob-bb3fb02bec0467d2/tmp/count_words.marbeik.20191118.185622.785260/files/wd...
Copying other local files to s3://mrjob-bb3fb02bec0467d2/tmp/count_words.marbeik.20191118.185622.785260/files/
Created new cluster j-1ZY5Z37LMZHWF
Added EMR tags to cluster j-1ZY5Z37LMZHWF: __mrjob_label=count_words, __mrjob_owner=marbeik, __mrjob_version=0.6.12
Waiting for Step 1 of 1 (s-1TFAJLTSJSWXK) to complete...
PENDING (cluster is STARTING)
PENDING (cluster is STARTING)
PENDING (cluster is BOOTSTRAPPING: Running bootstrap actions)
PENDING (cluster is BOOTSTRAPPING: Running bootstrap actions)
PENDING (cluster is BOOTSTRAPPING: Running bootstrap actions)
PENDING (cluster is RUNNING: Running step)
master node is ec2-52-42-249-126.us-west-2.compute.amazonaws.com
RUNNING for 0:00:33 ...