This is the final project for "Deep Learning:Fundamentals and Applications" at National Chengchi University (NCCU) by Liang, Shih-Rui, Hsiao, Hung-Hsuan, and Hung, Jui-Fu. Full report is here.
There are several ways to generate new images based on provided samples. Well-known examples include Cycle Generative Adversarial Network (CycleGAN) and Adaptive Convolutions (AdaConv). Previous studies [1, 2] show that the two models have excellent image-to-image translation results. In this study, the two models are fed with different image datasets and are then used to turn real-world images into respective datasets' styles. The generator of CycleGAN is implemented with both ResNet [3] and U-Net [4]. Sobel filters [5] are added on some training data to test the edge detection effects. The results show that for different tasks, certain combinations of training data, models, or model structures outperform others.
CycleGAN, CycleGAN with Unet as generator, and AdaConv are the three models adopted in this research. The models are trained with Chinese Ink, Monet, and Ukiyo-e paintings and can then be used to turn real-world images (domain X) into respective styles (domain Y).
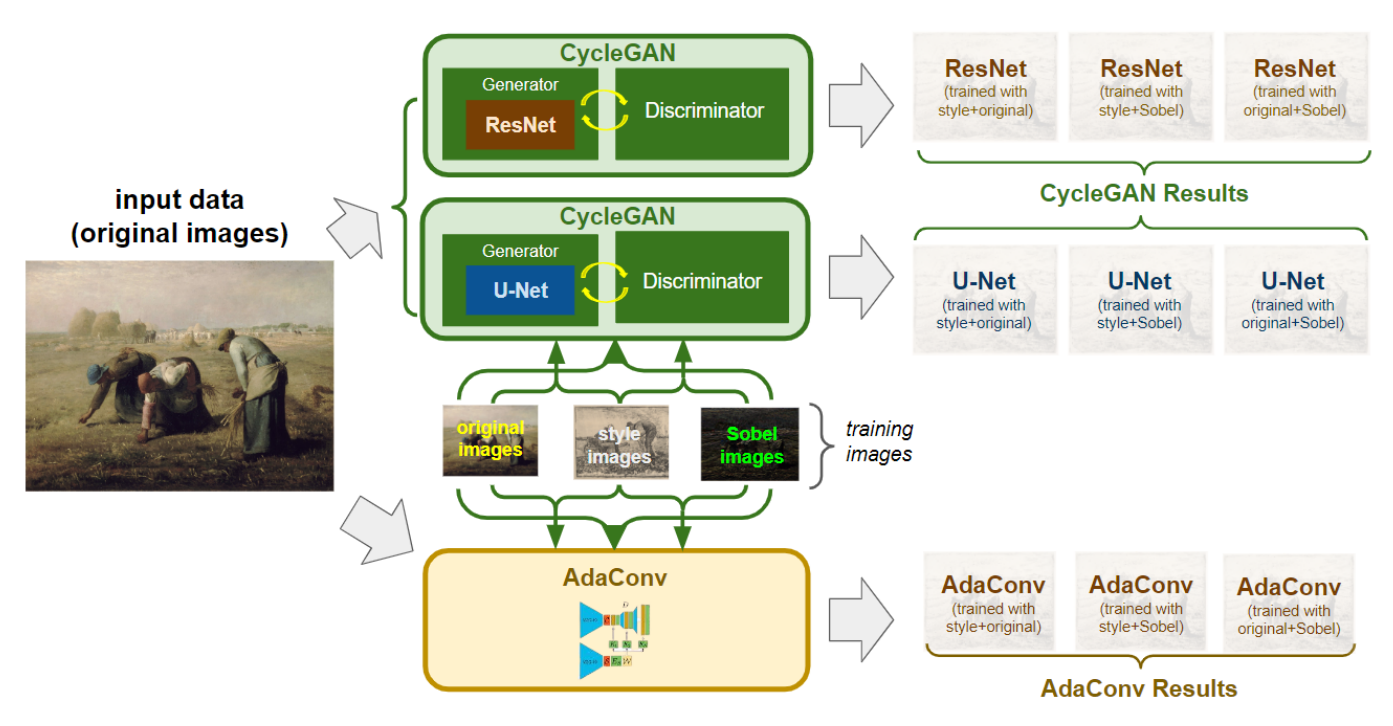
The original images and style images are downloaded from Kaggle. Styles of the images include Chinese Landscape Painting Dataset (referred as Chinese Ink in this study), Monet2Photo (referred as Monet in this study), and Ukiyo-e2photo (referred as Ukiyo-e in this study). Sobel filter is applied to training data of the original images, creating images with obvious white object edges. The three sets are combined in pairs each time they are sent to the models for training.
- CycleGAN (with ResNet)
- CycleGAN (with U-Net)
- AdaConv



This research compares the image translation results of different models, variations of a model, and different combinations of training data. The model plays the most crucial role, as changes of models make the most differences. There is no model that outperforms all other models in all kinds of tasks. CycleGAN with ResNet is better at Monet-style translation; AdaConv is better at Chinese Ink-style translation; CycleGAN with both ResNet and U-net as generators are equally good at Ukiyo-e-style translation. For edge detection, CycleGAN with U-Net has the least effect. It indicates that an adequate model should be chosen depending on the mission. Using the wrong model will lead to poor results given the same training data and parameters.
- J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, 2017.
- P. Chandran, G. Zoss, P. Gotardo, M. Gross, D. Bradley. Adaptive Convolutions for Structure-Aware Style Transfer. CVPR46437.2021.00788, 2021.
- K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, IEEE Computer Society, 2016, pp. 770–778.
- O. Ronneberger, P. Fischer, T. Brox. U-net: Convolutional networks for biomedical image segmentation, in: International Conference on Medical image computing and computer-assisted intervention, Springer, 2015, pp. 234–241.
- N. Kanopoulos, N. Vasanthavada, R. L. Baker. Design of an Image Edge Detection Filter Using the Sobel Operator, IEEE Journal of Solid-State Circuits, vol. 23, no. 2, 1988.