PageRank (PR) is an algorithm used by Google Search to rank websites in their search engine results.
- It works by counting the number and quality of links to a page to determine a rough estimate of how important the website is.
- The assumption is that more important websites are likely to receive more links from other websites.
Apache Hadoop is an open-source software framework used for distributed storage and processing of dataset of big data using the MapReduce programming model. The project includes these modules:
- Hadoop Distributed File System (HDFS): A distributed file system to access application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.

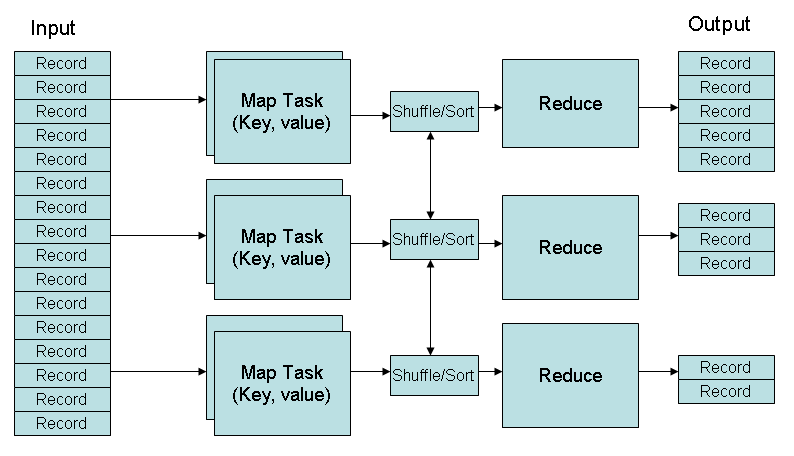
A MapReduce program is composed of a Map() method that performs filtering and sorting and a Reduce() method that performs a summary operation. Each mapper and reducer may execute on different nodes, so what each mapper and reducer would get should be implemented by programmer.
example:
mapperwrite data in<key, value>format to context.partitionerdecide how to partition different keys to which reducers.reducerget multiple key and their grouped values in iterable type.
HDFS (Hadoop Distributed File System) stores large files across multiple machines and can be access by a single directory system.
### List contents on pageRank directory
$ hdfs dfs -ls -R pageRank
pageRank
|-- _SUCCESS
|-- part-00000
|-- part-00001
`-- part-00002
### merge pageRank directory content to a single file
$ hdfs dfs -getmerge pageRank pagerank.outWikitext is our input format
The input file on HDFS is a normal text file in wikitext format with multiple lines. Each line contains one page which is enclosed in <page> and </page>. There are only two attributes we need to consider: page title and page links
- Placed between
<title>and</title>. - The first character of a title is always in upper case.
- Since title is part of an XML text, the real title text need to be un-escaped as follows:
| input string in title text | un-escaped character |
|---|---|
| < | < |
| > | > |
| & | & |
| " | " |
| ' | ' |
- For example, the title string
Ulmus 'Nire-keyaki'need to be converted toUlmus 'Nire-keyaki'.
-
Placed between
[[and]], which defines what page it points to and the shown text of the link. -
To simplify the processing and be more specific, we define a link to another page as follows:
[[means what follows is a target page title.- The page title is case-sensitive except the first character.
- Only capitalize the first character if it’s from
a - z - The first
]], vertical bar|or sharp sign#, it meets afterwards means the end of the target page title. - Note that links which points to a nonexistent page is not considered a valid link.
|-- Makefile
|-- README.md
|-- bin
|-- execute.sh
|-- logs
| |-- input-100M.out
| `-- input-1G.out
`-- src
|-- PageRanking.java
|-- calculate
| |-- CalcMapper.java
| `-- CalcReduce.java
|-- parse
| |-- ParseMapper.java
| |-- ParsePartitioner.java
| `-- ParseReducer.java
`-- result
|-- SortMapper.java
|-- SortPair.java
|-- SortPartitioner.java
`-- SortReducer.java
6 directories, 15 files- α: damping factor
- N: number of total pages
- n: number of pages points to
x - C: number of outlinks of the page which points to
x - m: number of dangling pages (dangling page is a page without outlinks)
- What's the difference of
TextInputFormatandKeyValueTextInputFormat?- The
TextInputFormatclass converts every row of the source file into key/value types where the BytesWritable key represents the offset of the record and the Text value represents the entire record itself. - The
KeyValueTextInputFormatis useful to fetch every source record as Text/Text pair where the key/value were populated from the record by splitting the record with a fixed delimiter. - Stack Overflow
- The
Consider the Below file contents,
### record input files
AL#Alabama
AR#Arkansas
FL#Florida
### TextInputFormat (key, value)
0 AL#Alabama
14 AR#Arkansas
23 FL#Florida
### KeyvalueTextInputFormat (key, value)
### ("mapreduce.input.keyvaluelinerecordreader.key.value.separator", "#")
AL Alabama
AR Arkansas
FL Florida