What is Ridge Regression?
Rige Regression is a variation of Linear Regression
Linear Regression is a simple yet powerful linear model which predicts the dependent variable using linear combination of various independent variables.
Ridge regression is one of the simple techniques to reduce model complexity and prevent over-fitting which may result from simple linear regression.
Ridge Regression : In ridge regression, the cost function is altered by adding a penalty equivalent to square of the magnitude of the coefficients.
Cost function for a simple Linear Regression:

This method finds the co efficients without any bias to the features that best fits the data. OLS doesnt consider which independent variable is more important in the prediction. So there is only one set of weights (coefficients).
Cost function for a Ridge Regression:
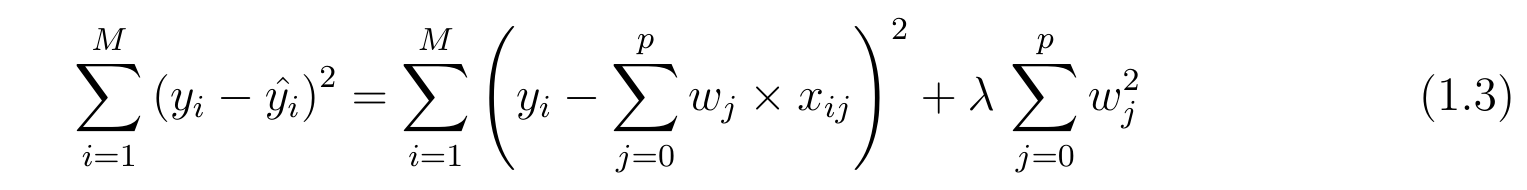
This method finds co efficients with a bias to the features by altering the lambda. Bias means how equally a model cares about its predictors. Let’s say there are two models to predict an apple price with two predictor ‘sweetness’ and ‘shine’; one model is unbiased and the other is biased. Therefore, an OLS model becomes more complex as new variables are added.
The term with lambda is often called ‘Penalty’ since it increases RSS. We iterate certain values onto the lambda and evaluate the model with a measurement such as ‘Mean Square Error (MSE)’. So, the lambda value that minimizes MSE should be selected as the final model.
Never becomes to zero
As we increase the lambda value, the weight decreases. It converges to zero but never becomes zero. It gives different importance to the weights but never drops the unimportant features.
On performing experiments with the house dataset available in scikit library, below are the results.
Dataframe

Coefficients for different values of lambda

Regression Trace
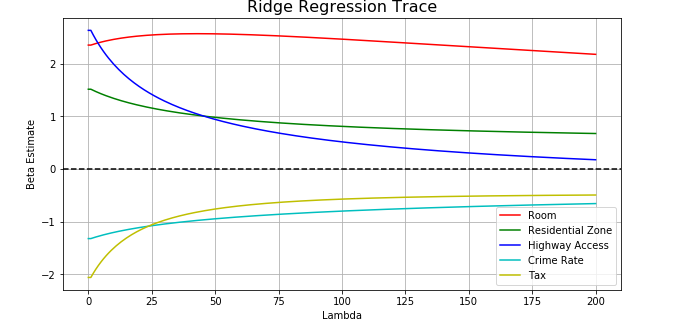
‘Room’ should be the best indicator for house price by intuition. This is why the line in red does not quite shrink over iteration. On the contrary, ‘Highway Access’ (blue) decreases remarkably, which means the feature loses its importance as we seek more general models.
Comparision to OLS
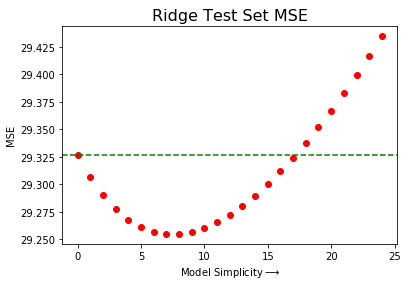
The green dotted line is from OLS on the graph above with the X-axis being drawn by increasing lambda values. The MSE values decreases in the beginning as the lambda value increases, which means the model prediction is improved (less error) to a certain point. In short, an OLS model with some bias is better at prediction than the pure OLS model, we call this modified OLS model as the ridge regression model.
OLS simply finds the best fit for given data
Features have different contributions to RSS
Ridge regression gives a bias to important features
MSE or R-square can be used to find the best lambda
Additional
Lasso Regression : The cost function for Lasso (least absolute shrinkage and selection operator) regression can be written as

This type of regularization (L1) can lead to zero coefficients i.e. some of the features are completely neglected for the evaluation of output. So Lasso regression not only helps in reducing over-fitting but it can help us in feature selection. Just like Ridge regression the regularization parameter (lambda) can be controlled.