{kind=link}
This repository contains the source code of our ACL 2020 paper Screenplay Summarization Using Latent Narrative Structure.
In this work, we summarize screenplays by taking into account their underlying narrative structure. We formalize screenplay summarization as scene selection, where we want to select an optimal subsequence of scenes that describe the story from beginning to end. We conduct experiments on the CSI dataset that contains gold-standard scene-level summary annotations.
The repository includes the Topic-Aware Model (TAM) introduced in [1] for turning point (TP) identification based on movie screenplays and plot synopses annotated with gold-standard TP sentences.
It also includes a simplified version of TAM for identifying TP events based solely on the movie screenplays.
We use these two models for pre-training a network on TP identification.
Finally, we include two versions of SUMMER:
-
Unsupervised: structure-aware version of directed neural TextRank [2]. We modify the centrality calculation of each scene by considerring weights
$f_i$ per scene that indicate how likely it is that the scene represents a TP. -
Supervised: we decide about whether to include a scene into the episode summary based on its content and salience. We define the salience of a scene as the degree of its similarity with the storyline of the episode. We further consider the storyline of an episode as the set of key events (TPs) that have been identified in the latent space. Here is an overview of the supervised SUMMER:
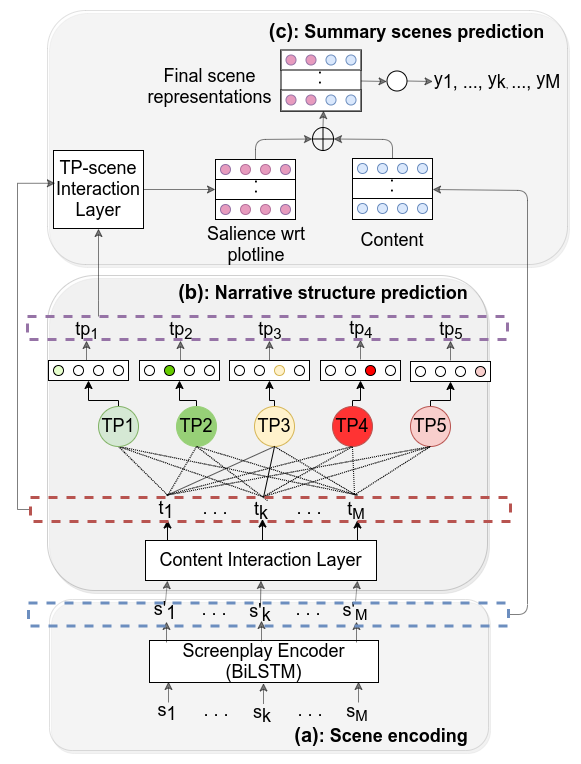
During our experiments we use two datasets:
-
TRIPOD dataset: Dataset containing 99 movies accompanied by their screenplays and plot synopses. The dataset provides us with gold-standard TP annotations in the synopses.
-
CSI dataset: Summarization dataset containing 39 episodes with scene-level binary annotations indicating whether each scene belongs to the summary.
For both datasets, we extract textual features for each sentence included in a scene using the Universal Sentence Encoder (USE). We include in the dataset/ folder all pre-processed datasets (train_TRIPOD_USE.pickle, test_TRIPOD_USE.pickle, csi_USE.pickle).
First we train TAM on TP identification on TRIPOD dataset, using the screenplays segmented into scenes, the plot synopses and the gold-standard TP synopsis sentences:
python models/TAM_teacher.py
Next, we use the trained TAM model (checkpoints/teacher.pt) in order to predict silver-standard scene-level labels for the movies of the training set:
python models/predict_labels.py
This script creates a pickle file (dataset/labels_train_TRIPOD_silver.pickle) containing the predicted labels per movie & TP event.
Next, given the silver-standard labels we train the modified TAM model that takes as input only the screenplays segmented into scenes:
python models/TAM_student.py
This scripts creates the pretrained network on TP identification (checkpoints/student.pt) that we will use for screenplay summarization.
- Unsupervised Summer
For the unsupervised version of our model we use the TP scenes predicted by TAM in order to compute extra weights f_i for each scene s_i which we include in the directed TextRank algorithm:
python models/Summer_unsupervised.py
- Supervised Summer
For the supervised version, we use the pre-trained TAM in order to initialize the weights of the part of our network that identifies TP events in the latent space. The whole network is trained end-to-end on summarization:
python models/Summer.py
We include a pre-trained version of teacher.pt and student.pt as well as the silver-standard scene-level labels for the training set of TRIPOD.
- PyTorch version >= 1.3.1
- Python version >= 3.7.4
@article{papalampidi2020screenplay,
title={Screenplay Summarization Using Latent Narrative Structure},
author={Papalampidi, Pinelopi and Keller, Frank and Frermann, Lea and Lapata, Mirella},
journal={arXiv preprint arXiv:2004.12727},
year={2020}
}
[1] Papalampidi, Pinelopi, Frank Keller, and Mirella Lapata. "Movie Plot Analysis via Turning Point Identification." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
[2] Zheng, Hao, and Mirella Lapata. "Sentence Centrality Revisited for Unsupervised Summarization." Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.