Keras implementations of three language models: character-level RNN, word-level RNN and Sentence VAE (Bowman, Vilnis et al 2016).
Each model is implemented and tested and should run out-of-the box. The default parameters will provide a reasonable result relatively quickly. You can get better results by using bigger datasets, more epochs, or by tweaking the batch size/learning rate.
If you are new to RNNs or language modeling, I recommend checking out the following resources:
- Understanding LSTMs by Chris Olah
- Lecture on Sequential models
The three models are provided as standalone scripts. Just download or clone the repository and run any of the following:
python chars.py
python words.py
python sentences.py
Add -h to see the parameters you can change. Make sure you have python 3, and the required packages installed.
This is the language model discussed in Andrey Karpathy's popular blog post The unreasonable effectiveness of RNNs. Here is an image from that post explaining the basic principle.
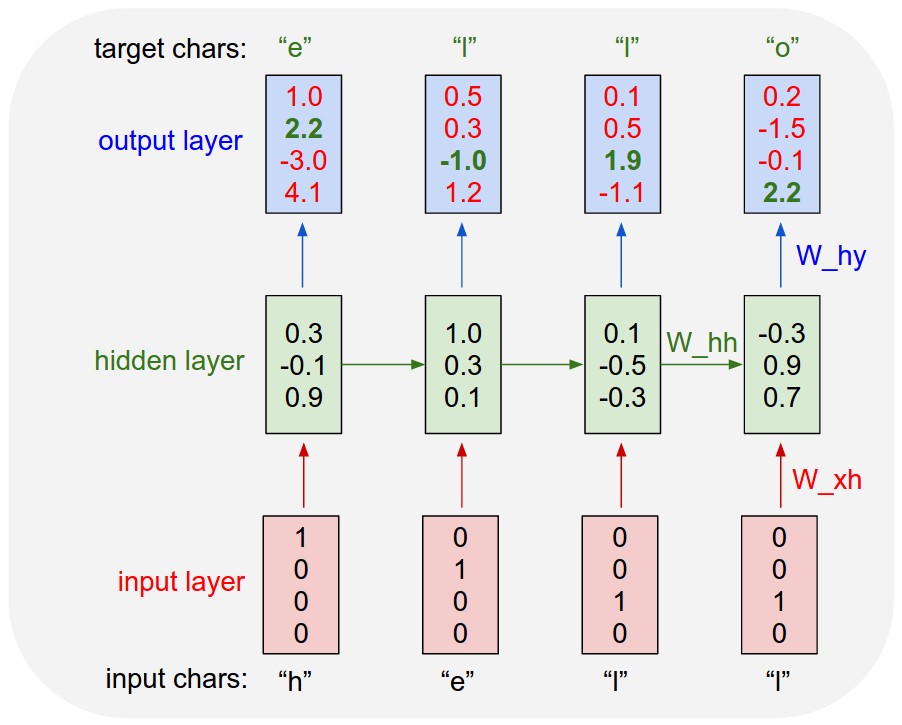
We train the model by asking it to predict the next character in the sentence, given only the preceding characters. This is easy to do on an unrolled RNN by shifting the input forward by one token (for instance by prepending a start-of-sentence character) and training it to predict the non-shifted sequence.
To generate sequences, we start from a seed: a sequence of a few characters taken from the corpus. We feed these to the RNN and ask it to predict the next character, in the form of a probability distribution over all characters. We sample a character from this distribution, add it to the seed, and repeat.
- The default corpus is Alice in wonderland. This takes about 4 minutes per epoch on my laptop with no GPU. The collected works of shakespeare (```-t shakespeare``) take a little over one hour on a CPU.
- With a high-end (TitanX) GPU,
alicetakes about 30 seconds per epoch andshakespearetakes about 30 minutes with default settings. - If you have the memory, increase the sequence length with, for instance,
-m 1000, which will reduce the training time per epoch to a little over 10m forshakespeareand about 30s foralice. - Training a good character level model can take a long time. For a big corpus , you should expect a couple of days training time, even with a GPU.
With the standard settings, I get the following samples after <> epochs:
This is basically the same as the previous model, but instead of treating language as a sequence of characters, we treat it as a sequence of words. This means we can use a much simpler RNN (one layer will be enough), but it also means that the dimension of the input sequence is much bigger. Previously, we had about 100 possible input tokens, and we could simply model text as a sequence of one-hot vectors. Since we will have about 10000 different words, it pays to pass them through an embedding layer first. This layer embeds the words into a low dimensional space (300 dimensions in our example), where similar words can end up close to each other. We learn this embedding together with the weights of the RNN.
- Note that the
-mswitch here will actually remove sentences from your corpus (unlike the previous model, where it just controlled how the corpus was cut into chunks).
RNN language models are pretty spectacular, but they have trouble maintaining long term structure. For instance: you can train the character-level model to produce Shakespeare, with realistic-looking character names, but over time you will not see the same characters recurring. Similarly, the word-level language model produces grammatical text, but often meanders starting the next sentence before the previous has finished (like a Donald Trump speech).
To provide long-term structure, we can use a Sentence VAE. This is a model first introduced in Bowman, Vilnis et al 2016. It combines three ideas:
- Sequence-to-sequence autoencoders. Autoencoders that use an RNN to encode a sequence into a latent representation z, and then use another RNN to decode it. The model is trained on reconstruction error.
- RNN Language modeling. The decoder decodes the original sentence from Z, but is also provided with the sentence as input, as in the previous models. This is also known as teacher forcing. It gives us the best of both worlds: we use a language model to lean the low-level word-to-word structure and and an autoencoder to learn the high level structure, encoded in
z. - Variational autoencoders. The first two ingredients suffice to create a decent language model for high level structure, but we want one more thing: if we sample a random
z, we want it to decode into a grammatical sentence. Similarly, is we encoder two sentences into latent representationsz1andz2, we want thezhalf in between them to decode into a grammatical sentence whose meaning is a mixture of the first two. Using a variational instead of a regular autoencoder helps us to achieve this structure in the latent space.
Variational autoencoders are powerful, but complicated models. To learn more, check out the following resources:
- Intuitively understanding Variational Autoencoders by Irhum Shafkat
- Tutorial on Variational Autoencoders by Carl Doersch
- Lecture on Variational Autoencoders (and other generative models)
- If you have the memory,
-b 1024 -l 1e-2is a decent way to train quickly (about 10 seconds per epoch on a TitanX).
For each implementation I got stuck for a long time on several bugs. If you're porting/adapting any of these models to another platforms, make sure to check the following.
- Check your loss curves. Since inference is so different from training, it's quite possible that the model is training perfectly well, and there's just a stupid bug in the generating code.
- For most models, it doesn't matter much whether you sum or average the loss per word/character for your loss function. For the VAE it matters hugely, since you have another loss term (the KL loss) which needs to be balanced with the reconstruction loss.
To install all required packages, run the following pip command (let me know if I've forgotten anything):
pip install numpy keras matplotlib nltk tensorboardx scipy
You'll also need tensorflow. If you don't have a GPU, run pip install tensorflow. If you do, run pip install tensorflow-gpu and make sure your drivers are installed correctly.
I've tried to use keras calls only, and to avoid tensorflow-specific things, but I haven't tested whether this works with other backends than tensorflow. If you're testing with another backend, let me know how you get on.