![]()
Açık Kaynak Hackathon Programı 2020 için geliştirilen projede ana hedef "Haber başlıkları üzerinden konu (kategori) tahmini" olarak tanımlanmıştır.
- Milliyet.com üzerinden 1997-2019 yılları arası çıkan haberler kullanılmıştır. Derlem açık kaynak olarak paylaşılmıştır.
- Haber başlıklarına ek olarak haber metni ve özeti üzerinden de konu (kategorinin) tahmin edilmesi sağlanmıştır.
- Sonuçlar üzerine analiz sunulmuştur.
- Oluşturulan model ile Aralık 2019 ve Temmuz 2020 arası Twitter gündemi incelenmiştir.
- Demo
Ek olarak çıkarım-bazlı özetleme (extractive summarization) algoritması olan Text Rank [3] kullanılarak metinlerde önemli noktaların bulunması ve özet çıkarımı sağlanmıştır.
- Milliyet.com adresinden 1997-2019 yılları arasında çıkan, haberler büyük oranda çekilmiştir.
- Her haber, internet sayfasında bulunduğu gibi kaydedilmiştir.
- Başlık, özet, haber metni, kategori ve link
- Özet bazı haberlerde bulunmamaktadır.
- Temizlenmemiş hali ile 116.068 örnek bulunmaktadır. (sıkıştırılmamış hali ile 403.9Mb)
Deneylerde kök bulma (stemming) işlemi yapılmış fakat sınıflandırma performansına katkısı gözlemlenmemiştir. Bu nedenle, projede TurkishStemmer [1] paketi kullanılmamaktadır ama kullanıcı isterse pre_processing_tr.py paketindeki turkish_stemmer(s) methodunu kullanarak diledikleri cümlelerdeki kelimeleri köküne ulaşabilmektedir.
import pickle
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
#from TurkishStemmer import TurkishStemmer #opsiyonelProje kapsamında 3 farklı derlem paylaşılmıştır.
milliyet_derlem.csv.gz: Haberler milliyet.com'dan çekildiği gibi saklanmıştır.
temizlenmis_derlerm.csv.gz: Bazı kategorilerde bulunan haberler atılmıştır. Benzer kategorideki haber türleri birleştirilmiştir. Konu hakkında detaylı bilgi için yazının "Veri Temizliği ve Düzenlenmesi" kısmını okuyabilirsiniz.
filtrelenmis_temizlenmis_derlem.csv.gz: Ön-işleme sonucu filtrelenmiş haberleri içerir. Ön-işleme adımları hakkında detaylı bilgi için yazının "Haber Metinlerinde Ön-İşleme" kısmını okuyabilirsiniz.
derleme_erisim adlı jupyter notebookta gösterildiği gibi dilediğiniz derlemi ismini yazarak açabilirsiniz.
data=pd.read_csv('derlemler/filtrelenmis_temizlenmis_derlem.csv.gz')Derlem sütunlarının anlamları:
- news_title: haber başlığı
- summary: haber özeti
- category: haberin kategorisi (filtrelenmiş)
- date: haberin paylaşıldığı gün (bazı haberlerde bu tarihte sapmalar bulunmaktadır)
- link: haberin çekildiği bağlantı adresi
- news: haber metni
- category_backup: haberin orijinal (milliyet sitesinde bulunduğu) kategori
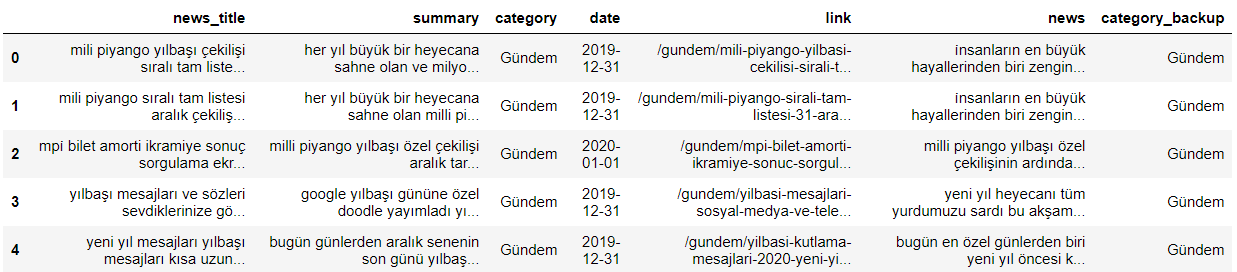
Filtrelenmiş-temizlenmiş derlemin ilk 5 örneği:
Haber yazılarının makine öğrenmesi yöntemlerine uygun hale getirilmesi için gereken adımlar:
-
Genel yazım hatalarının düzeltilmesi
- Verilerde genel olarak bulunan yazım hataları düzeltilmiştir.
- Örneğin: ... kazandıTürkiye... --> ...kazandı Türkiye...
-
Sayıların ve noktalama işaretlerinin yerine boşluk konulması
- Bütün sayılar kategori tahmininde etkisiz kalacağı düşünülerek boşluk ile değiştirilmiştir.
- Noktalama işaretlerinin yerine boşluk getirilmiştir.
- Doğrudan silmek yerine boşluk konulması haberlerde büyük oranda bulunan virgülden sonra atlanan boşluk hatası sonucu kelimelerin birleşmesini önüne geçmektir.
-
Fazla boşluklardan kurtulma
- Sayıların, noktalama işaretlerinin temizlenmesi sırasında iki kelime arası birden fazla boşluk oluşmuştur. Bu boşluklar tek boşluk olucak şekilde değiştirilnmiştir.
-
Türkçe dolgu sözcüklerinin (stop words) çıkarılması
- Türkçe Dolgu Sözcükleri (stop words) sık kullanılan, fakat iptal metinden çıkarıldıklarında cümlenin anlamında önemli değişiklikler oluşturmayan sözcüklerdir. Necmettin Çarkacı'nın GitHub hesabında paylaşılan [2] dolgu sözcükleri listesine göre vektöre dönüştürülme esnasında metinlerden bu sözcükler çıkarılmıştır.
-
Kök bulma (stemming)
- Projede aktif olarak kullanılmamıştır fakat kullanıcı isterse pre_processing_tr.py paketindeki turkish_stemmer(s) methodunu kullanarak diledikleri cümlelerdeki kelimeleri köküne ulaşabilmektedir.
Ön-işleme adımlarının (1-3), istenen yazıda yapılması için gereken adımlar:
import pre_processing_tr as pr
yazi = "Ön-işlemden geçirmek istenilen yazı"
islenmis_yazi = pr.pre_process(text)Kök bulma metotunun kullanılması için gereken adımlar
import pre_processing_tr as pr
yazi = "stem edilmek istenen yazı"
stem_yazi = pr.turkish_stemmer(yazi)- Gündem, Dünya, Cumartesi ve Pazar kategorilerindeki haberler genel konular hakkında olduğu için, Ege kategorisindeki haberler yerel haberler oldukları için analizin dışında tutulmuşlardır.
- 4-kategori ve 5-kategori içeren iki tür veri üzerinden model oluşturulmuştur. Farklı modeller haber başlığı, özeti ve metni üzerine eğitilmiştir. (Örneğin başlık üzerine eğitilen modelde eğitim ve sınıflandırma esnasında sadece haber başlıkları kullanılmıştır)
- 4-kategori: Ekonomi, Siyaset, Spor, Teknoloji-Bilim
- 5-kategori: Ekonomi, Siyaset, Spor, Teknoloji-Bilim, Diğer (Kültür-Sanat, Magazin, Yaşam)
Kendi istediğiniz haberleri sınıflandırmak için bu iki modelden birini kullanabilirsiniz.
- 4-kategorili sınıflandırma için 4_kategori_tahmin.py
- 5 kategorili sınıflandırm için 5_kategori_tahmin.py
Hazır modelleri çalıştırmak için command promp'ta (komut istemi) proje dizinine gelinmeli ve python 5_kategori_tahmin.py yazarak çalıştırılmalıdır. Daha sonra sınıflandırmak istenen metin girilmelidir.
Kullanım rahatlığı açısından kategorik_sınıflandırma adlı jupyter notebook'u kullanmanız tavsiye edilir.
Sonuçlar
| Başlık | Özet | Haber Metni | |
|---|---|---|---|
| 4-kategori | %71.3 | %82.2 | %85.5 |
| 5-kategori | %66.1 | %79.3 | %80.9 |
Tablo: Veri türüne ve kategori sayısına göre sınıflandırma performansları (doğruluk)
Haber metinleri üzerinden oluşturduğumuz modeller daha başarılı olduğu, projede onlar kullanılmıştır.
Kategorilere göre en çok geçen kelimeler:
- Ekonomi: 'önemli', 'türk', 'dolar', 'yıl', 'yüzde'
- Siyaset: 'parti', 'başbakan', 'başkanı', 'erdoğan', 'chp'
- Spor: 'takım', 'futbol', 'beşiktaş', 'galatasaray', 'fenerbahçe'
- Teknoloji_Bilim: 'akıllı', 'samsung', 'galaxy', 'apple', 'yeni'
- Temizlenmemiş derlemde toplam 199 kategori bulunmaktadır. Bu kategorilerden bazıları köşe yazarlarıdır. Bazı kategorilerde 10'dan az haber bulunmaktadır.
- Kategorilerin birleştirilmesi ve silinmesi:
- Futbol, Skorer, Basketbol, Fenerbahçe, Galatasaray, Beşiktaş… gibi spor ile alakalı haberlere genel bir kategori oluşturulup "Spor" adı verillmiştir.
- Teknoloji_Bilim, Magazin, Yaşam ve Dünya kategorileri de yukarıdaki mantık ile birden fazla kategorinin birleştirilmesi ile oluşturulmuştur.
- Kategorisi köşe yazarları olan örnekler silinmiştir.
- Haberlerin orijinal (milliyet sitesinde bulundukları) kategori derlemde kategori_yedek sütununda tutulmuştur.
Filtrelenmiş ve temizlenmiş derlemde bulunan toplam haber sayısı: 81407
Haber türüne göre örnek sayıları:
- Gündem: 21031
- Ekonomi: 11165
- Spor: 10699
- Siyaset: 14530
- Dünya: 4792
- Yaşam: 1696
- Pazar: 2090
- Ege: 6131
- Magazin: 3980
- Kültür_Sanat: 1265
- Teknoloji_Bilim: 3105
- Cumartesi: 923
- Sınıflandırma işlemi öncesi sklearn kütüphanesi üzerinden CountVectorizer fonksiyonu ile haber metinleri vektöre çevrilmiştir.
- BoW (Bag of words) yöntemi kullanılmıştır. Vektörde her sütun bir kelimeyi, her satır ise haberde o kelimenin kaç defa geçtiğini temsil etmektedir. Tf–idf yöntemi de denenmiştir fakat performansı BoW’e göre geride kaldığı için analize eklenmemiştir.
- Vektöre dönüştürülme esnasında metinlerden türkçe dolgu sözcükleri (stop words) "Haber Metinlerinde Ön-İşleme" kısmında belirtildiği gibi çıkarılmıştır.
- Model olarak Çok-terimli Naive Bayes (Multinomial Naive Bayes) sınıflandırıcı kullanılmıştır.
- Çeşitli parametreler ile çapraz geçerleme (cross validation) yapılmış ve en uygun (optimize) şekle getirilmiştir. [%70 train (eğitim), %30 test (deney)]
- SVM, Random Forests, XGBoost, Yapay sinir ağları gibi daha karmaşık algoritmalar da denenmiştir fakat performans olarak Çok-terimli Naive Bayes’e göre geride kaldıkları için analize eklenmemişlerdir.
Model oluşturma aşamaları model_oluşturma adlı jupyter notebook üzerinden incelenebilir.
- Haberlerin paylaşıldığı tarih bilgisini kullanarak kelimelerin aya ve yıla göre haberlerde bulunma durumlarını inceleyebiliriz. Bu sayede kişilerin, kurumların, vs. 1997-2019 yılları arasında medyada ne kadar yer kapladıkları gözlemlenebilmekte ve bunun üzerine çıkarımlar yapılabilmektedir.
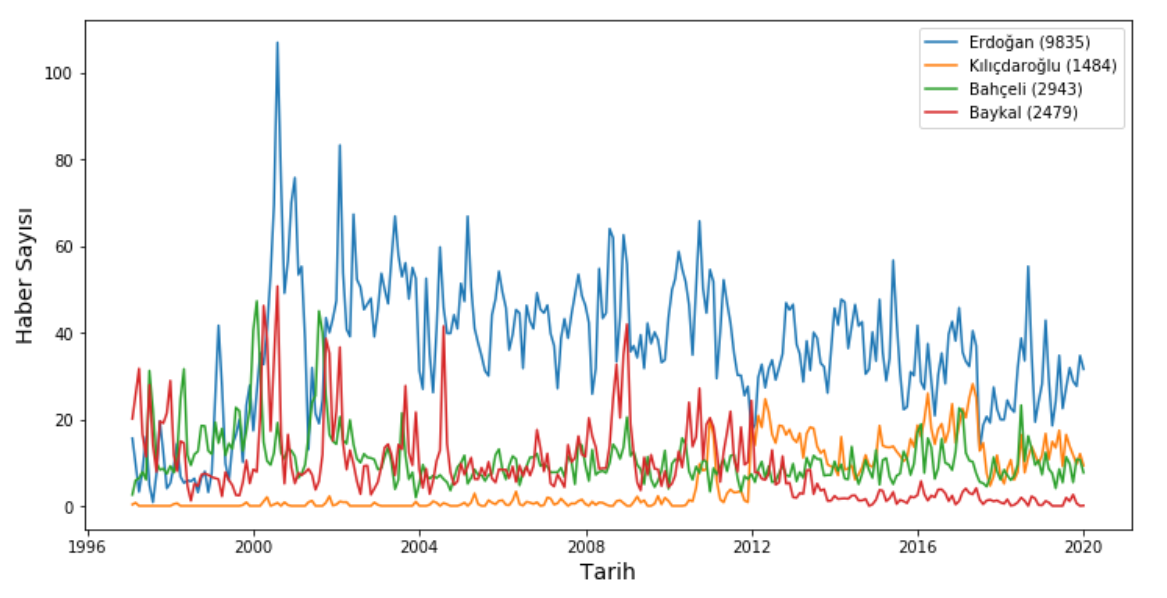
- Aşağıdaki grafiklerde seçili kelimelerin tarihe göre haberlerde ne kadar bulunduğunu göstermektedir. Lejandda parantez içerisindeki değer yanında bulunduğu kelimenin toplam geçtiği haber sayısıdır.
- Örneğin ilk grafik Erdoğan, Kılıçdaroğlu, Bahçeli ve Baykal kelimeleri ile elde edilen sonuçları içermektedir. 1996-1998 yılları arası Bahçeli ve Baykal hakkında daha çok haber çıkarken Erdoğan'ın haber sayısı onlara göre azdır. O dönemde siyasi olarak ön planda olmayan Kılıçdaroğlu hakkında haber neredeyse hiç yoktur. 1998 sonrası dönemde Erdoğan baskın bir biçimde medyada yer almaktadır.
- Bir diğer göze çarpan detay ise Baykal ve Kılıçdaroğlu ile ilgilidir. 2010 yılında Kılıçdaroğlu Baykal'ın yerine CHP genel başkanlığına seçilmiştir. Öncesinde hakkında neredeyse hiç haber yokken Baykal'ı zamanla geçmiştir. Baykal'ı içeren haberler ise o yıl sonrasında azalmış ve 2013 yılı itibari ile sıfıra yaklaşmıştır.
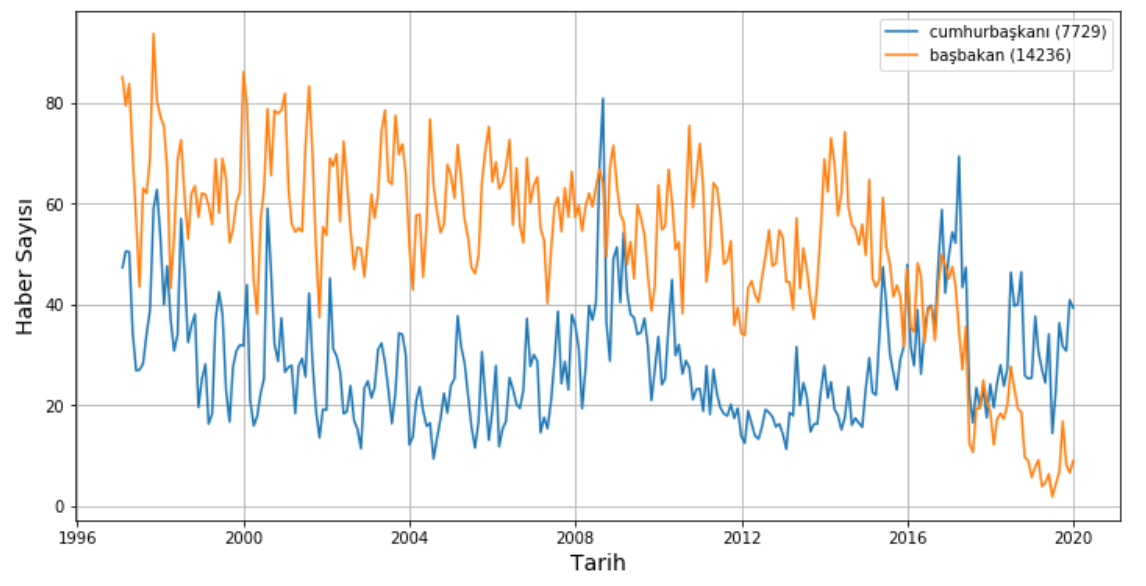
- Bir diğer analiz ise cumhurbaşkanı ve başbakan kelimeleri üzerinden yapılabilir. Aşağıdaki grafik bu iki kelime ile elde edilen sonuçları içermektedir. 2016 yılına kadar başbakan medyada daha ön planda iken 2016 yılında başkanlık sistemi referendumunun sinyalleri ile cumhurbaşkanı ön plana çıkmaya başlamıştır. 2017 yılında başkanlık sisteminin kabulü ile cumhurbaşkanı ile ilgili yapılan haberler başbakan hakkında yapılan haber sayısını geçmiştir.
- Yukarıda incelenen örnekler gibi birçok durum benzer şekilde analiz edilebilir.
haberlerde_kesif adlı jupyter notebook ile kendi istediğiniz kelimeler ile grafik oluşturabilir ya da örnek grafikleri inceliyebilirsiniz.
Kendi istediğiniz kelimeler ile alternatif olarak grafik oluşturmak için command promp'ta (komut istemi) proje dizinine gelinmeli ve python haberlerde_kesif_cizici.py yazarak çalıştırılmalıdır. Daha sonra istenilen kelimeler sistem uyarı verdiğinde (veritabanın büyüklüğü sebebi ile biraz bekletmektedir) aralarında bir boşluk olarak girilmelidir.
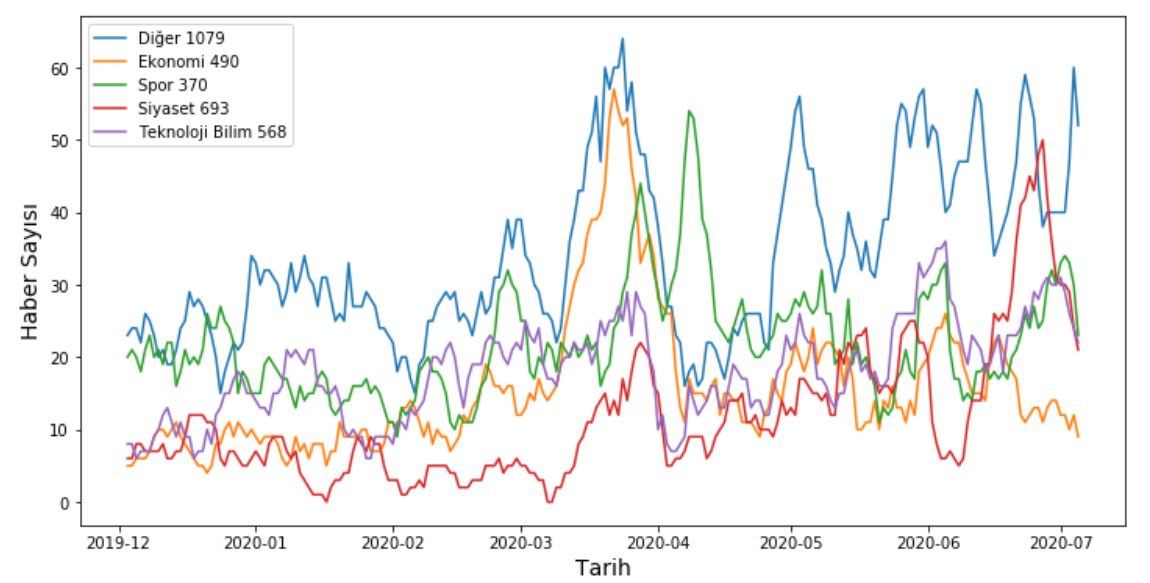
- Twitter'da @nedenttoldu gibi birçok Twitter gündemi anlık olarak yazan hesaplar bulunmaktadır. Bu hesaplar konular ya da kişiler neden TT oldu, 'Trending topics' listesindeki kelimelerin nedeni gibi konularda yazı yazmaktadırlar. Bu tarz hesapların incelenmesi ile Twitter gündemini gün ve ay olmak üzere inceleyebiliriz. 11 Temmuz 2020 ile 3 Aralık 2019 tarihleri arasında @nedenttoldu hesabının attığı bütün tweetler çekilmiştir. Zaman aralığının dar olma sebebi Twitter'ın koymuş olduğu 3200 tweetlik sınırlamadır.
- Tweetler de haberler gibi ön-işleme adımlarından geçirilmiş ve geliştirmiş olduğumuz model (5-kategori) ile sınıflandırılmıştır. 7 günlük kayan pencere içerisinde kategorilere göre toplam kaç tweet atıldığı hesaplanmıştır. Sonuçlar aşağıdaki grafikte verilmiştir (lejandda parantez içerisinde verilen değer toplam o kategoride sınıflandırlan tweet sayısıdır). Ön-işleme adımları haber verisi işlemeye daha uygun olduğu için bazı tweetlerde temizleme işlemi sonucu linklerden ya da emojilerden artıklar kalmıştır.
twitter_kesif adlı jupyter notebook ile aşama aşama yukarıda anlatılanları inceleyebilirsiniz.
- Metinlerde çıkarım-bazlı özetleme (extractive summarization) günümüzde dikkat çeken konulardan biri olmuştur. Açık Hack yarışmalarında (2019-2020) bu konu ile ilgili birden fazla proje gözlemlenebilmektedir.
- Projeye kapsamına ek olarak Text Rank [3] algoritması kullanılarak metin özetleyici ve önemli noktaları bulan bir model geliştirilmiştir. Model cümle vektörlerinin benzerlikleri üzerine bir çizge (graph) kurmaktadır. Bu graph üzerinde PageRank Algoritması ile en çok ziyaret edilen nokta (cümle) bulunmakta ve metindeki en önemli cümle seçilmektedir. Birden fazla cümle seçilir ise (en çok ziyaret edilenden en aza) bir özet ortaya çıkmaktadır. Algoritma önemli cümleleri bulmakta özelleştiği için genellikle özetlerde seçilen cümleler düzgün olsa da oluşan özet metni cümlelerin sıralaması açısından devrik olmaktadır.
- Haberlerdeki yazım ve noktalama hataları nedeniyle bazı özel durumlarda metinleri cümle cümle ayıran metot düzgün çalışmamakta ve algoritmayı olumsuz yönde etkilemektedir. Bu nedenle kullanılacak olan haber metninin düzgün seçilmesi önemlidir.
- Projenin geri kalanından bağımsız olarak FastText ve NetworkX kütüphaneleri kullanılmıştır. Vektör oluşturulmasında FastText kütüphanesinin oluşturmuş olduğu türkçe vektör modeli kullanılmıştır. Özetlemenin çalışması için link'te bulunan sayfadan Türkçe için yapılmış ".bin" uzantılı dosyanın indirilmesi gerekmektedir.
Gereken ek paketler:
import nltk
import fasttext
import fasttext.util
import networkx as nx
from nltk.tokenize import sent_tokenize
from sklearn.metrics.pairwise import cosine_similarityozetci adlı jupyter notebook ile milliyet derleminden seçeceğiniz herhangi bir haberi ya da dilediğiniz metnin önemli noktalarını çıkarabilirsiniz. İlgili dökümanda adımlar kademe kademe anlatılmıştır.
[1] Turkish Stemmer, Osman Tunçelli, link
[2] Türkçe Dolgu Sözcükleri, Necmettin Çarkacı, link
[3] TextRank: Bringing Order into Texts, link
