An MSc thesis work. - 2020.
As a quest to achieve super-resolution I've taken the novel approach of constructing a Reinforcement Learning based model using Tensorflow 2.0. But first, to better undersand the problem, I've studied and implemented several upsampling models which are detailed in the sections below. My contribution also extends to creating easy-to-use notebooks for downloading and preprocessing popular datasets (BSD68, BSD500, MIT-Adobe FiveK, MS COCO, BDD100k, Cityscapes, Kitti). Based off of Tensorflow's dataset implementation, I've implemeted a custom, reusable, memory-efficient dataset class for handling images (only HDF format is supported as of yet).
Reference: Image Super-Resolution Using Deep Convolutional Networks - Chao Dong, Chen Change Loy, Kaiming He, Xiaoou Tang
First, an LR image is upsampled using traditional Bicubic interpolation to get the HR* representation. Then this coarse image is fed to the model, which is aimed to reconstruct missing/lost details. Fast, but the achievable results are hidered by the upsampling algorithm.
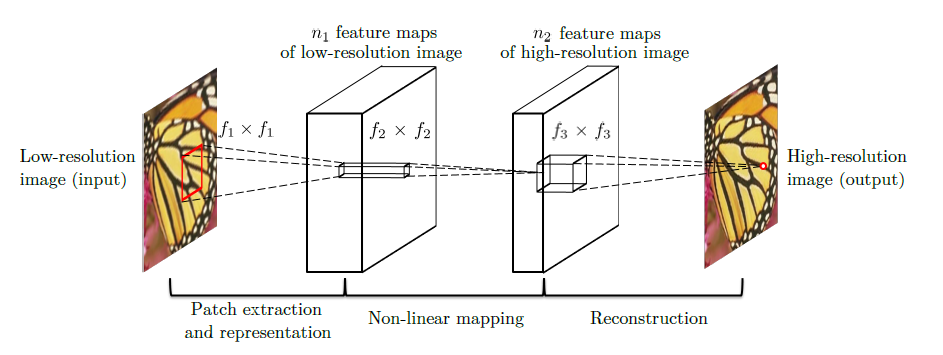

SSIM=0.70
PSNR=20.70
Reference: Accelerating the Super-Resolution Convolutional Neural Network - Chao Dong, Chen Change Loy, Xiaoou Tang
A model largely similar to the pre-upsampling model with the difference of feeding the LR image to the model instead of the upsampled one. This is done in hope of trying to mitigate the effect of the upsamping algorithm by using the convolutional layers to extract features before they are potentionally lost. Fast, but the achievable results are still hidered by the upsampling.

SSIM=0.60
PSNR=19.21
Reference: Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks - Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, Ming-Hsuan Yang
The model uses a pyramid structure. At each pyramid level, the model consists of a feature embedding sub-network for extracting non-linear features, transposed convolutional layers for upsampling feature maps and images, and a convolutional layer for predicting the sub-band residuals. As the network structure at each level is highly similar, it shares the weights of those components across pyramid levels to reduce the number of network parameters. This way the upsampling can take place in multiple steps, which makes the network capable to preserve more of the original image's features, especially for large (4x, 8x) scaling factors.
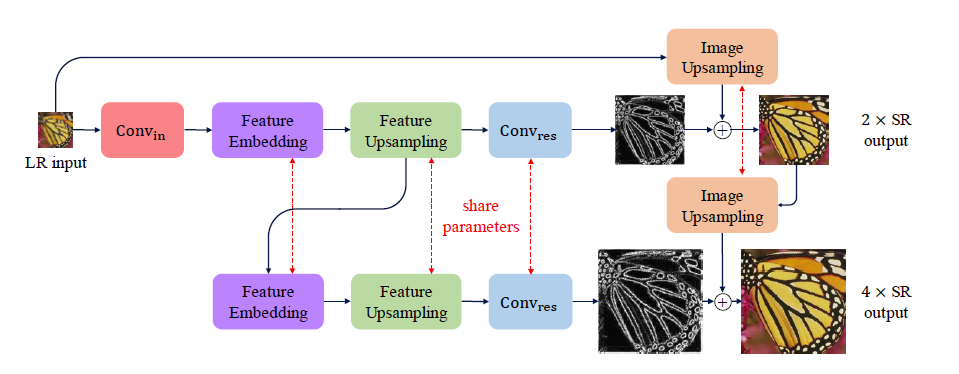

SSIM=0.70
PSNR=20.68
Reference: Deep Back-Projection Networks for Single Image Super-resolution - Muhammad Haris, Greg Shakhnarovich, Norimichi Ukita
The model consists of iterative up- and down-sampling layers. These layers are formed as a unit providing an error feedback mechanism for projection errors.
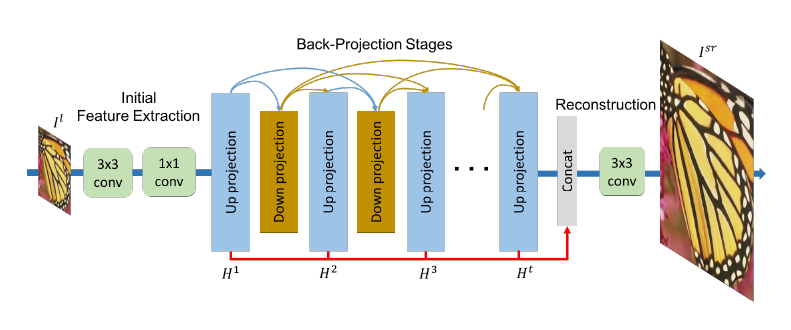

SSIM=0.65
PSNR=19.22
For adversarial training I've constructed a classifier discriminator model consisting of TODO layers. By incorporating the discriminator's loss into the aforementioned supervised leraning model's (in this context the generators') training process, except from the pre-upsampling model all other models were able to attain a higher evaluation rating. The following images are meant to illustrate the results, the values below the images are the average PSNR and SSIM values, and their differences compared to the purely supervised trainig results evaluated on Set14 dataset.

SSIM 0.69 (-0.01) 0.60 (+0.00) 0.71 (+0.01) 0.65 (+0.00)
PSNR 20.55 (-0.15) 19.40 (+0.19) 20.98 (+0.30) 19.53 (+0.31)
Reference: PixelRL: Fully Convolutional Network with Reinforcement Learning for Image Processing - Ryosuke Furuta, Naoto Inoue, Toshihiko Yamasaki
An effective reinforcement learning model with pixel-wise rewards modified for upsampling task. In pixelRL, each pixel has an agent, and the agent changes the pixel value by taking an action. Therefore a policy is constructed which strives for maximum reward.
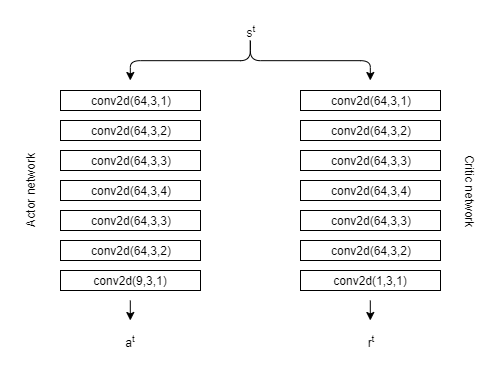

SSIM=0.81
PSNR=22.37
For prediction purposes, I've included pre-trained models. To use them, all you have to do is:
- Instantinate a network e.g.:
network = IterativeSamplingNetwork((35, 35, 1))for grayscale,network = IterativeSamplingNetwork((35, 35, 3))for colored images - Load the pre-trained state/weights:
network.load_state()for grayscale,network.load_state("_color")for colored images - Get your images as a 4D numpy array, shaped (count, height, width, channels)
- Predict:
predicted_images = network.predict(your_4d_numpy_image_array)Thepredictmethod supports an optionalscaling_factor: intparameter. The default scaling is 2x, but most of the models suppot 4x, 8x as well.
Complete example:
import numpy as np
import cv2
from src.networks.supervised.pre_upsampling_network import PreUpsamplingNetwork
network = PreUpsamplingNetwork((35, 35, 3))
network.load_state("_color")
img = cv2.imread(<path to your image>, cv2.IMREAD_COLOR)
img = cv2.resize(img, (35, 35), cv2.INTER_CUBIC) # network works with 35x35 images
img = img[np.newaxis, :, :, :] # get the 4D shaped image numpy array
img = img / 255.0 # normalize image values
pred = network.predict(img, 2) # upsample the image by 2x
# display the image
cv2.imshow("2x image", pred[0]) # pred is also a 4D array, we want to display the first (and in this case only) image
cv2.waitKey()
TODO