I made a privacy focused, Chromium web browser to intercept all requests on a website while web scraping. I built it using Tor and PySide6 (a QT framework for Python).
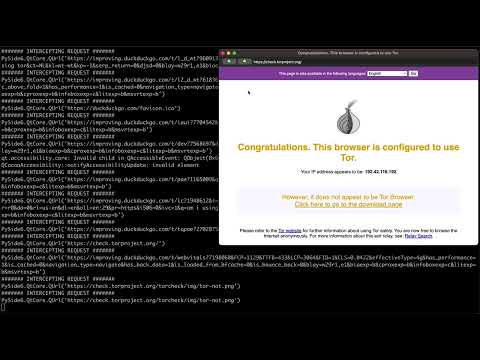
I've spent the last 5 month (Oct 2022 to Feb 2023) on a web scraping deep dive. I got to the point where I can scrape many of the public websites (not including the social media giants) using Selenium and Headless Chrome.
One thing I wanted more control over were the network requests. I wanted to see if there was a lightweight way to block requests from reaching the server from the browser. I spent the next few days diving deep into the chromium, and servo project source code to understand how web browsers work.
To my surprise I found there is a rather simple way to do this via Python. The next step is to turn this into a lightweight headless browser to do some distributed web scraping.
from PySide6.QtCore import QUrl, Slot
from PySide6.QtGui import QIcon
from PySide6.QtWidgets import (QApplication, QLineEdit,
QMainWindow, QPushButton, QToolBar)
from PySide6.QtWebEngineCore import QWebEnginePage, QWebEngineUrlRequestInterceptor, QWebEngineProfile
from PySide6.QtWebEngineWidgets import QWebEngineView
from PySide6.QtNetwork import QNetworkProxy
import sys
import os
import stem.process
import re
import urllib.request
class RequestInterceptor(QWebEngineUrlRequestInterceptor):
def interceptRequest(self, info):
print("####### INTERCEPTING REQUEST #######")
print(info.requestUrl())
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle('PySide6 WebEngineWidgets Example')
self.toolBar = QToolBar()
self.addToolBar(self.toolBar)
self.backButton = QPushButton()
self.backButton.setIcon(
QIcon(':/qt-project.org/styles/commonstyle/images/left-32.png'))
self.backButton.clicked.connect(self.back)
self.toolBar.addWidget(self.backButton)
self.forwardButton = QPushButton()
self.forwardButton.setIcon(
QIcon(':/qt-project.org/styles/commonstyle/images/right-32.png'))
self.forwardButton.clicked.connect(self.forward)
self.toolBar.addWidget(self.forwardButton)
self.addressLineEdit = QLineEdit()
self.addressLineEdit.returnPressed.connect(self.load)
self.toolBar.addWidget(self.addressLineEdit)
self.webEngineView = QWebEngineView()
self.setCentralWidget(self.webEngineView)
initialUrl = "http://ip-api.com/json"
self.addressLineEdit.setText(initialUrl)
self.webEngineView.load(QUrl(initialUrl))
self.webEngineView.page().titleChanged.connect(self.setWindowTitle)
self.webEngineView.page().urlChanged.connect(self.urlChanged)
@Slot()
def load(self):
url = QUrl.fromUserInput(self.addressLineEdit.text())
if url.isValid():
self.webEngineView.load(url)
@Slot()
def back(self):
self.webEngineView.page().triggerAction(QWebEnginePage.Back)
@Slot()
def forward(self):
self.webEngineView.page().triggerAction(QWebEnginePage.Forward)
@Slot(QUrl)
def urlChanged(self, url):
self.addressLineEdit.setText(url.toString())
def launch_tor_process():
SOCKS_PORT = 9050
CONTROL_PORT = 9051
TOR_PATH = "/usr/local/bin/tor"
GEOIPFILE_PATH = os.path.normpath(os.getcwd() + "/geoip")
try:
urllib.request.urlretrieve(
'https://raw.githubusercontent.com/torproject/tor/main/src/config/geoip', GEOIPFILE_PATH)
except:
print('[INFO] Unable to update geoip file. Using local copy.')
tor_process = stem.process.launch_tor_with_config(
config={
'SocksPort': str(SOCKS_PORT),
'ControlPort': str(CONTROL_PORT),
'ExitNodes': '',
'StrictNodes': '1',
'CookieAuthentication': '1',
'MaxCircuitDirtiness': '60',
'GeoIPFile': GEOIPFILE_PATH,
},
take_ownership=True,
init_msg_handler=lambda line: print(line) if re.search(
'Bootstrapped', line) else False,
tor_cmd=TOR_PATH
)
if __name__ == '__main__':
# Launch a Tor process
launch_tor_process()
app = QApplication(sys.argv)
# Proxy all browser requests through the Tor process
PROXY_PORT = 9050
PROXY_HOST = "127.0.0.1"
proxy = QNetworkProxy()
proxy.setType(QNetworkProxy.Socks5Proxy)
proxy.setHostName(PROXY_HOST)
proxy.setPort(PROXY_PORT)
QNetworkProxy.setApplicationProxy(proxy)
# Add a request interceptor so we can read all the requests from the browser
interceptor = RequestInterceptor()
mainWin = MainWindow()
mainWin.webEngineView.page().profile().setUrlRequestInterceptor(interceptor)
availableGeometry = mainWin.screen().availableGeometry()
mainWin.resize(availableGeometry.width() * 2 / 3,
availableGeometry.height() * 2 / 3)
# Launch the web browser
mainWin.show()
sys.exit(app.exec())I'm Steven, an software engineer in love with all things web scraping and distributed systems. I worked at Twitter as an SRE migrating 500,000 bare metal servers from Aurora Mesos to Kubernetes.
On Nov 3, 2022 I was laid off. Since then I've spent the time doing deep dives and writing about my journey.
I'm creating a web scraping course to so you don't have to spend months learning how to:
- analyze a website to determine the best way to scrape data
- use proxies to scrape without getting blocked by Cloudflare, Datadome, or PerimeterX
- scrape web sites with Javascript
- build your own web scraping framework
- build scalable infrastructure for scraping
Join the prelaunch to gain free access before it becomes a paid course.