{kind=link}
Python client for the expert.ai Natural Language APIs adds Natural Language understanding capabilities to your Python apps. The client can use either the Cloud based Natural Language API or a local instance of Edge NL API.
Make reference to the Natural Language API and Edge NL API documentation to know more about the APIs capabilities.
Here is a side-by-side comparison of the two APIs:
| Capability | Natural Language API | Edge NL API |
|---|---|---|
| Where does it run? | In the Cloud, shared by all users | On user's PC |
| Document analysis: Deep linguistic analysis | YES | YES |
| Document analysis: Keyphrase extraction | YES | YES |
| Document analysis: Named entities recognition | YES | YES |
| Document analysis: Relation extraction | YES | YES |
| Document analysis: Sentiment analysis | YES | YES |
| Document analysis, full (the sum of all of the above in a single operation) | YES | YES |
| Document classification: IPTC Media topics | YES | NO |
| Document classification: GeoTax | YES | NO |
| Document classification: Emotional traits | YES | NO |
| Document classification: Behavioral traits | YES | NO |
| Document classification: custom taxonomy | NO | YES* |
| Personally Identifiable Information (PII) detection | YES | NO |
| Writeprint detection | YES | NO |
| Information extraction | NO | YES* |
| Document size limit? | YES (<= 10KB) | NO |
| Document number limit? | NO | See the pricing terms |
| Characters limit? | YES (<= 10 million characters per month when using the free tier) | NO |
* Available only for custom text intelligence engines created with Studio
Use pip to install the client library:
pip install expertai-nlapiExpert.ai Natural Language APIs are free to use, ideally forever, with the limitations specified in the table above.
You need an expert.ai developer account to use the APIs and you can get one for free registering on the expert.ai developer portal.
If you need to exceed the free tier usage limits, subscribe a payment plan from inside the developer portal.
The Python client code expects your developer account credentials to be specified as environment variables:
- Linux:
export EAI_USERNAME=YOUR_USER
export EAI_PASSWORD=YOUR_PASSWORD- Windows:
SET EAI_USERNAME=YOUR_USER
SET EAI_PASSWORD=YOUR_PASSWORDYOUR_USER is the email address you specyfied during registration.
You can also define credentials inside your code:
import os
os.environ["EAI_USERNAME"] = 'your@account.email'
os.environ["EAI_PASSWORD"] = 'yourpwd'The next thing to do inside your code is importing the client section of the library and instantiating the client based on the API you want to use.
- To use the Cloud based Natural Language API:
from expertai.nlapi.cloud.client import ExpertAiClient
client = ExpertAiClient()- To use a local instance of Edge NL API:
from expertai.nlapi.edge.client import ExpertAiClient
client = ExpertAiClient()In the samples directory of this repository you can find ready-to-run scripts showing how to access all API capabilities for English texts and API self-documentation resources.
Scripts are listed and described in the tables below.
You can find these scripts under the /samples/cloud natural language api folder.
| Capability | Sample |
|---|---|
Document analysis, standard context, full analysis |
/document analysis/full.py |
Document analysis, standard context, sub-analysis: Deep linguistic analysis |
/document analysis/deep-linguistic-analysis.py |
Document analysis, standard context, sub-analysis: Keyphrase extraction |
/document analysis/keyphrase-extraction.py |
Document analysis, standard context, sub-analysis: Named entity recognition |
/document analysis/named-entity-recognition.py |
Document analysis, standard context, sub-analysis: Relation extraction |
/document analysis/relation-extraction.py |
Document analysis, standard context, sub-analysis: Sentiment analysis |
/document analysis/sentiment-analysis.py |
| Document analysis, self-documemtation esources: list of the available contexts | /document analysis/contexts.py |
Document classification with iptc taxonomy |
/document classification/iptc.py |
Document classification with geotax taxonomy |
/document classification/geotax.py |
Document classification with emotional-traits taxonomy |
/document classification/emotional-traits.py |
Document classification with behavioral-traits taxonomy |
/document classification/behavioral-traits.py |
| Document classification, self-documentation resources: list of available taxonomies | /document classification/taxonomies.py |
Document classification, self-documentation resources: category tree of the iptc taxonomy |
/document classification/category-tree-iptc.py |
Document classification, self-documentation resources: category tree of the geotax taxonomy |
/document classification/category-tree-geotax.py |
Document classification, self-documentation resources: category tree of the emotional-traits taxonomy |
/document classification/category-tree-emotional-traits.py |
Document classification, self-documentation resources: category tree of the behavioral-traits taxonomy |
/document classification/category-tree-behavioral-traits.py |
Information detection with pii detector |
/information detection/pii.py |
Information detection with writeprint detector |
/information detection/writeprint.py |
| Information detection, self-documentation resources: list of available detectors | /information detection/detectors.py |
You can find these scripts under the /samples/local edge nl api folder.
| Capability | Sample |
|---|---|
| Document analysis, full analysis | /document analysis/full.py |
| Document analysis, sub-analysis: Deep linguistic analysis | /document analysis/deep-linguistic-analysis.py |
| Document analysis, sub-analysis: Keyphrase extraction | /document analysis/keyphrase-extraction.py |
| Document analysis, sub-analysis: Named entity recognition | /document analysis/named-entity-recognition.py |
| Document analysis, sub-analysis: Relation extraction | /document analysis/relation-extraction.py |
| Document analysis, sub-analysis: Sentiment analysis | /document analysis/sentiment-analysis.py |
The Natural Language API is capable of processing texts of various languages.
You can use self-documentations resources like contexts and taxonomies—look for the corresponding ready-to-run scripts in the first of the two tables above—to determine if a functionality is available for a given language.
If it's available, specify the language parameter in your code, for example:
text = "Michael Jordan è stato uno dei migliori giocatori di pallacanestro di tutti i tempi. Fare canestro è stata la capacità in cui Jordan spiccava, ma ancora detiene un record NBA di gioco difensivo, con otto palle rubate in metà partita."
language= 'it'
output = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'disambiguation'
})See also the documentation pages about contexts and taxonomies.
Edge NL API can also process texts of different languages, but in this case you have to download from the developer portal and launch on your PC the package corresponding to the language you are interested in.
If you need to run your client application on a computer and the Edge NL API on another or if you need Edge NL API to listen on a TCP port other than the default (which is 6699), you can use the set_host method of the Edge NL API client to specify the host and the port, for example:
from expertai.nlapi.edge.client import ExpertAiClient
client = ExpertAiClient()
client.set_host('my_edge_server', 6699)Or, if you continue to use the API on the local computer, but you changed the port in the Edge NL API startup batch file:
from expertai.nlapi.edge.client import ExpertAiClient
client = ExpertAiClient()
client.set_host('localhost', 6700)To perform the deep linguistic analysis of a text:
- Natural Language API:
output = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'disambiguation'
})- Edge NL API:
output = client.deep_linguistic_analysis(text)Lemmatization looks beyond word reduction, using a language's full vocabulary to apply a morphological analysis to words. The lemma of 'was' is 'be' and the lemma of 'mice' is 'mouse'. Further, the lemma of 'meeting' might be 'meet' or 'meeting' depending on its use in a sentence.
print (f'{"TOKEN":{20}} {"LEMMA":{8}}')
for token in output.tokens:
print (f'{text[token.start:token.end]:{20}} {token.lemma:{8}}')TOKEN LEMMA
Facebook Facebook Inc.
is is
looking at look at
buying buy
an an
American American
startup startup
for for
$6 million 6,000,000 dollar
based base
in in
Springfield, IL Springfield
. .
Analysis determines the part-of-speech of tokens. PoS labels are from the Universal Dependencies framework.
print (f'{"TOKEN":{18}} {"PoS":{4}}')
for token in output.tokens:
print (f'{text[token.start:token.end]:{18}} {token.pos:{4}} ' )TOKEN PoS
Facebook PROPN
is AUX
looking at VERB
buying VERB
an DET
American ADJ
startup NOUN
for ADP
$6 million NOUN
based VERB
in ADP
Springfield, IL PROPN
. PUNCT
The analysis returns the dependency parsing information assigned to each token, using the Universal Dependencies framework as well.
print (f'{"TOKEN":{18}} {"Dependency label":{8}}')
for token in output.tokens:
print (f'{text[token.start:token.end]:{18}} {token.dependency.label:{4}} ' )TOKEN Dependency label
Facebook nsubj
is aux
looking at root
buying advcl
an det
American amod
startup obj
for case
$6 million obl
based acl
in case
Springfield, IL obl
. punct
Going a step beyond linguistic analysis, named entities add another layer of context. Named entities are recognized by the entities sub-analysis.
- Natural Language API:
output = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'entities'})- Edge NL API:
output = client.named_entity_recognition(text)Printing results:
print (f'{"ENTITY":{40}} {"TYPE":{10}}')
for entity in output.entities:
print (f'{entity.lemma:{40}} {entity.type_:{10}}')ENTITY TYPE
6,000,000 dollar MON
Springfield GEO
Facebook Inc. COM
In addition to the entity type, the API provides some metadata from Linked Open Data sources such as WikiData and GeoNames.
For example, you can get the open data connected with the entity Springfield, IL
print(output.entities[1].lemma)Springfield
for entry in output.knowledge:
if (entry.syncon == document.entities[1].syncon):
for prop in entry.properties:
print (f'{prop.type_:{12}} {prop.value:{30}}')
Coordinate Lat:39.47.58N/39.799446;Long:89.39.18W/-89.654999
DBpediaId dbpedia.org/page/Springfield
GeoNamesId 4250542
WikiDataId Q28515
Springfield has been recognized as Q28515 on Wikidata, that is the Q-id for Springfield, IL (i.e.not for Springfield in Vermont o in California)
Key elements, the result of keyphrase extraction, are obtained with the relevants sub-analysis and identified from the document as main sentences, main concepts (called "syncons"), main lemmas and relevant Knowledge Graph topics.
Let's focus on the main lemmas of the document; each lemma is provided with a relevance score.
- Natural Language API:
document = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'relevants'})- Edge NL API:
document = client.keyphrase_extraction(text)print (f'{"LEMMA":{20}} {"SCORE":{5}} ')
for mainlemma in document.main_lemmas:
print (f'{mainlemma.value:{20}} {mainlemma.score:{5}}')LEMMA SCORE
Facebook Inc. 43.5
startup 40.4
Springfield 15
Sentiment is obtained with the sentiment sub-analysis and expresses the polarity—positive or negative—and the intensity of the tone of the text is.
text='Today is a good day. I love to go to mountain.'
- Natural Language API:
document = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'sentiment'})- Edge NL API:
document = client.sentiment(text)Printing results:
print("sentiment:", document.sentiment.overall)Relations are obtained with the relations sub-analysis that labels concepts expressed in the text with their semantic role with respect to the verb they are connected to.
text='John sent a letter to Mary.'
- Natural Language API:
document = client.specific_resource_analysis(
body={"document": {"text": text}},
params={'language': language, 'resource': 'relations'})- Edge NL API:
document = client.relations(text)Printing results:
for rel in document.relations:
print("Verb:", rel.verb.lemma)
for r in rel.related:
print("Relation:", r.relation, "Lemma:", r.lemma )Let's see how to classify documents according to the IPTC Media Topics Taxonomy provided by the Natural Language API; then we'll use the matplot lib to display categorization results as a bar chart.
text = """Strategic acquisitions have been important to the growth of Facebook (FB).
Mark Zuckerberg founded the company in 2004, and since then it has acquired scores of companies,
ranging from tiny two-person start-ups to well-established businesses such as WhatsApp. For 2019,
Facebook reported 2.5 billion monthly active users (MAU) and $70.69 billion in revenue."""import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
taxonomy='iptc'
document = client.classification(body={"document": {"text": text}}, params={'taxonomy': taxonomy,'language': language})
categories = []
scores = []
print (f'{"CATEGORY":{27}} {"IPTC ID":{10}} {"FREQUENCY":{8}}')
for category in document.categories:
categories.append(category.label)
scores.append(category.frequency)
print (f'{category.label:{27}} {category.id_:{10}}{category.frequency:{8}}')CATEGORY ID FREQUENCY
Earnings 20000178 29.63
Social networking 20000769 21.95
plt.bar(categories, scores, color='#17a2b8')
plt.xlabel("Categories")
plt.ylabel("Frequency")
plt.title("Media Topics Classification")
plt.show()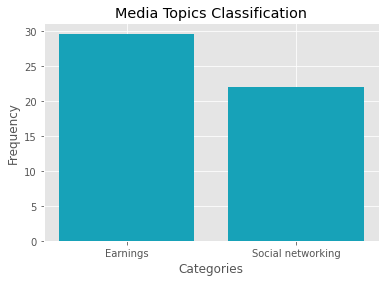
Basic Edge NL API packages dont't provide document classification, but you can create your own text intelligence engine performing document classification by using expert.ai Studio.
To request classification to a custom instance of the Edge NL API simply use:
document = client.classification(text)Results structure is the same as for the Natural Language API.
Information detection leverages deep linguistic analysis to extract particular types of information from the text.
For example, the Personal Identifiable Informtion (PII) detector of the Natural Language API extract personal information such as people names, dates, addresses, telephone numbers, etc. that could be considered "sensitive".
text='Longtime TFS News reporter Marcus Smith died unexpectedly Monday at the age of 60'
- Natural Language API:
document = client.detection(
body={"document": {"text": text}},
params={'language': language,'detector':'pii'})
for extraction in document.extractions:
print("Template:", extraction.template)
for field in extraction.fields:
print("field: ", field.name," value: " , field.value)
for position in field.positions :
print("start: ", position.start, "end: " , position.end)Basic Edge NL API packages dont't provide information detection, but you can create your own text intelligence engine performing information detection by using expert.ai Studio.
Good job! You're an expert in the expert.ai community! 👏 🎉
Check out other language SDKs available on our Github page.
Clone this GitHub repository and run the following script:
$ cd nlapi-python
$ pip install -r requirements-dev.txtAs good practice it's recommended to work in an isolated Python environment, creating a virtual environment with virtualenv package before building the package. You can create your environment with the command:
$ virtualenv expertai $ source expertai/bin/activate