- Install Docker. On OSX, I'm using boot2docker. For verification,
docker versionshould return a version. - Build the custom elasticsearch docker images, by running
build-docker-images.sh, which contains:docker build -t es - < Dockerfile-es docker build -t es-data - < Dockerfile-es-data docker build -t es-lb - < Dockerfile-es-lb - Pull down the couchdb docker image
docker pull klaemo/couchdb
Execute docker run -d -p 9200:9200 es
-dwill run the container in the background-p 9200:9200will forward port 9200 from the container to the hostesis the name of the image we want to run. In this case, it is a name of a tag.
Execute curl http://localhost:9200 and you should see a response similar to this:
{
"status" : 200,
"name" : "<Random name of node here>",
"version" : {
"number" : "1.0.1",
"build_hash" : "5c03844e1978e5cc924dab2a423dc63ce881c42b",
"build_timestamp" : "2014-02-25T15:52:53Z",
"build_snapshot" : false,
"lucene_version" : "4.6"
},
"tagline" : "You Know, for Search"
}You should also be able to open a browser to http://localhost:9200/_plugin/head/ to see an overview of your cluster. Right now, there should be only 1 node, and no other information as we haven't created any indexes.
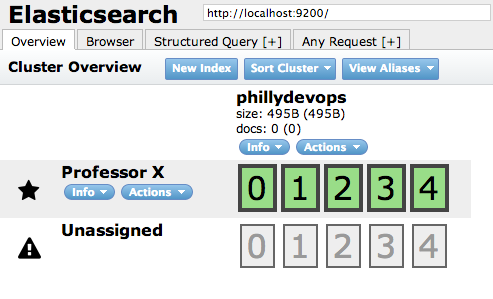
Let's create an index called phillydevops with 5 shards and 1 replica. A shard is the Elasticsearch term for the partitions in your dataset that Elasticsearch creates. For this index, we will have 10 shards in total (5 shards + 1 extra copy of each). We also create a mapping called meeting. This is going to be our data type and we could specify how we want different fields to be searched, but for simplicity we'll leave it blank to have the fields dynamically mapped. You can read more in the Elasticsearch documentation on mappings.
curl -XPUT 'http://localhost:9200/phillydevops/' -d '{
"settings" : {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1
}
},
"mappings" : {
"meeting" : {
"properties" : { }
}
}
}'
# Response: {"acknowledged":true}Now, when going to http://localhost:9200/_plugin/head/, you should see something like this, with five shards assigned to the node you created and five shards unassigned to any node.
Let's stop all containers with docker ps -q | xargs docker stop. It's possible with Elasticsearch to create a "load balancer" node that doesn't store data, but is still apart of the cluster and can server HTTP requests. We can start a load balancer node by running docker run -d -p 9200:9200 es-lb and create the index with bash create-elasticsearch-index.sh. If you look at the web interface you can see that no shards are assigned to the node. What's great about Elasticsearch, is that it's very easy to add another node and have our data be balanced among the servers available to the cluster. We can bring up Elasticsearch data nodes by running docker run -d es-data. After a few seconds, we can refresh http://localhost:9200/_plugin/head/ and all the shards have been assigned.!

If we run docker run -d es-data two more times, you can see how all the shards balance out.
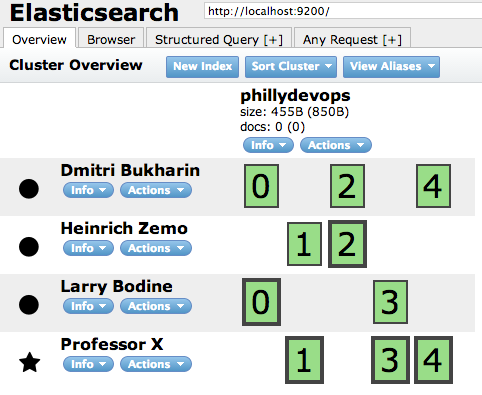
In production, this process will take much longer depending on how much data you have, but it's still generally that easy to do.
It isn't common that Elasticsearch is used as a primary datastore, although that might change in future versions. In this example, I will use Couchdb as my data store and stream data from Couchdb to Elasticsearch automatically.
Let's start a Couchdb server.
docker run -d -p 5984:5984 klaemo/couchdb
#Verify it's running
curl http://localhost:5984 # Response: {"couchdb":"Welcome","uuid":"6c1beddeb3b71705bde82eaebaf19652","version":"1.5.0","vendor":{"version":"1.5.0","name":"The Apache Software Foundation"}}We can now create a Couchdb database and put some documents into Couchdb. Running bash create-couch-data.sh will create the Couchdb database and fill it with some data drawn from the Meetup API. You can get the data using a curl call.
curl http://localhost:5984/phillydevops/_all_docs
#And you should see a response like
{
"total_rows":15,
"offset":0,
"rows":[
{"id":"b0e1336bb433194e25779c840a0115c9","key":"b0e1336bb433194e25779c840a0115c9","value":{"rev":"1-f86a906ea0b22e9b04aa76ce1557e0fc"}},
{"id":"b0e1336bb433194e25779c840a012578","key":"b0e1336bb433194e25779c840a012578","value":{"rev":"1-d3e5c535bd65b741b7824d293e4741e0"}},
{"id":"b0e1336bb433194e25779c840a01337a","key":"b0e1336bb433194e25779c840a01337a","value":{"rev":"1-732e9d4a6bff9f4ce95d55231c476c13"}},
{"id":"b0e1336bb433194e25779c840a01379b","key":"b0e1336bb433194e25779c840a01379b","value":{"rev":"1-020c9a8886d24c95f428ba270322205d"}},
{"id":"b0e1336bb433194e25779c840a013d03","key":"b0e1336bb433194e25779c840a013d03","value":{"rev":"1-978899db1e0bc289866cba86e9037627"}},
{"id":"b0e1336bb433194e25779c840a014c33","key":"b0e1336bb433194e25779c840a014c33","value":{"rev":"1-c2cca793558e1b3ca50c0dcba823b82b"}},
{"id":"b0e1336bb433194e25779c840a014ef0","key":"b0e1336bb433194e25779c840a014ef0","value":{"rev":"1-eea247051aba145f9b50a78c2bfaf8b5"}},
{"id":"b0e1336bb433194e25779c840a01593f","key":"b0e1336bb433194e25779c840a01593f","value":{"rev":"1-5c11f3c95479cbe0f621ab37f957ac2a"}},
{"id":"b0e1336bb433194e25779c840a015c85","key":"b0e1336bb433194e25779c840a015c85","value":{"rev":"1-58f87d60e6e9f1e5499d163aaab2fa12"}},
{"id":"b0e1336bb433194e25779c840a01619a","key":"b0e1336bb433194e25779c840a01619a","value":{"rev":"1-787b1a4ac822012122d442ad6909c9d2"}},
{"id":"b0e1336bb433194e25779c840a01678a","key":"b0e1336bb433194e25779c840a01678a","value":{"rev":"1-f6dfecb91fc15710db810758f672472e"}},
{"id":"b0e1336bb433194e25779c840a016c98","key":"b0e1336bb433194e25779c840a016c98","value":{"rev":"1-01b0539969853f1fd4e9ce0c21409a91"}},
{"id":"b0e1336bb433194e25779c840a016fcd","key":"b0e1336bb433194e25779c840a016fcd","value":{"rev":"1-fad41ffc3e50673980b32a95dd409e9c"}},
{"id":"b0e1336bb433194e25779c840a017296","key":"b0e1336bb433194e25779c840a017296","value":{"rev":"1-7cf01c54057a327bd2ecca8af0032c9a"}},
{"id":"b0e1336bb433194e25779c840a0176dd","key":"b0e1336bb433194e25779c840a0176dd","value":{"rev":"1-ab23624314187e989e5874cb8cdba6ef"}}
]
}To create the Elasticsearch river, we need to know the IP address of the docker container running Couchdb.
docker ps | grep 'klaemo/couchdb' | cut -f1 -d' ' | xargs docker inspect | grep IPAddress
#Should return something like
"IPAddress": "172.17.0.6",Edit the create-river.sh file to put the IP address into the couchdb host field. My script looks like the following.
curl -XDELETE http://localhost:9200/_river/phillydevops
curl -XPOST http://localhost:9200/_river/phillydevops/_meta -d '{
"type": "couchdb",
"couchdb": {
"host" : "COUCHDB IP ADDRESS HERE", #Put "172.17.0.6" here
"port" : 5984,
"db" : "phillydevops",
"filter": null
},
"index" : {
"index" : "phillydevops",
"type" : "meeting",
"bulk_size" : "10",
"bulk_timeout" : "100ms"
}
}'You can now execute the create-river.sh file and data should start flowing from Couchdb to Elasticsearch. Verify documents are in Elasticsearch:
curl http://localhost:9200/phillydevops/_count #{"count":0,"_shards":{"total":5,"successful":5,"failed":0}}
bash create-river.sh
curl http://localhost:9200/phillydevops/_count #{"count":15,"_shards":{"total":5,"successful":5,"failed":0}}
#Put some more documents in Couchdb
bash meetings.data
curl http://localhost:9200/phillydevops/_count #{"count":30,"_shards":{"total":5,"successful":5,"failed":0}}