


This repository provides UNOFFICIAL Parallel WaveGAN implementation with Pytorch.
You can check our samples in our demo HP!
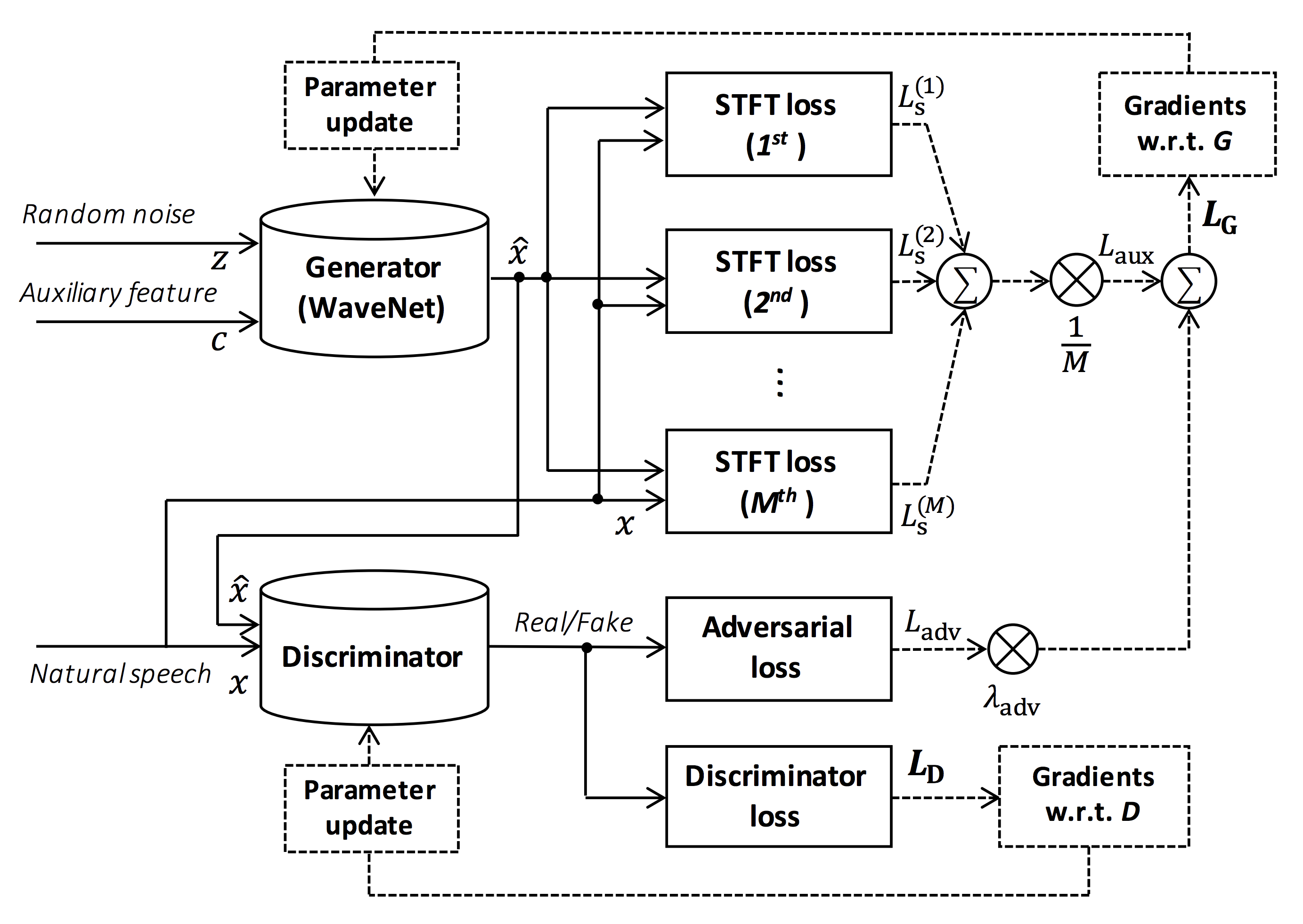
The goal of this repository is to provide the real-time neural vocoder which is compatible with ESPnet-TTS.
Source of the figure: https://arxiv.org/pdf/1910.11480.pdf
This repository is tested on Ubuntu 16.04 with a GPU Titan V.
- Python 3.6+
- Cuda 10.0
- CuDNN 7+
All of the codes are tested on Pytorch 1.0.1, 1.1, 1.2, and 1.3.
You can select the installation method from two alternatives.
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
$ source venv/bin/activateThis repository provides Kaldi-style recipes, as the same as ESPnet.
Currently, four recipes are supported.
- CMU Arctic: English speakers
- LJSpeech: English female speaker
- JSUT: Japanese female speaker
- CSMSC: Mandarin female speaker
To run the recipe, please follow the below instruction.
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf <your_customized_yaml_config>
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2The integration with job schedulers such as slurm can be done via cmd.sh and conf/slurm.conf.
If you want to use it, please check this page.
All of the hyperparameters is written in a single yaml format configuration file.
Please check this example in ljspeech recipe.
The training requires ~3 days with a single GPU (TITAN V).
The speed of the training is 0.5 seconds per an iteration, in total ~ 200000 sec (= 2.31 days).
You can monitor the training progress via tensorboard.
$ tensorboard --logdir exp
The decoding speed is RTF = 0.016 with TITAN V, much faster than the real-time.
[decode]: 100%|██████████| 250/250 [00:30<00:00, 8.31it/s, RTF=0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).Even on the CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads), it can generate less than the real-time.
[decode]: 100%|██████████| 250/250 [22:16<00:00, 5.35s/it, RTF=0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).You can listen to the samples and download pretrained models at our google drive.
The training is still on going. Please check the latest progress at kan-bayashi/ParallelWaveGAN#1.
The author would like to thank Ryuichi Yamamoto (@r9y9) for his great repository, paper and valuable discussions.
Tomoki Hayashi (@kan-bayashi)
E-mail: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp