In this tutorial, you'll learn how to manage a Machine Learning project lifecycle with MLflow, locally
pip install mlflow[extras]
NOTE: Best Practice for windows users : Work on virtual environments (pyenv or conda) within WSL2
https://github.com/pyenv/pyenv#basic-github-checkout
This is a fairly simple classification example. It illustrates how to apply different preprocessing and feature extraction pipelines.
For more details check the link below :
https://scikit-learn.org/stable/auto_examples/compose/plot_column_transformer_mixed_types.html#column-transformer-with-mixed-types
In order to track experiments, register models and deploy them you will have to integrate some mlflow functionalities in your code, as shown in the "titanic_classification_mlflow.ipynb" notebook.
import mlflow
mlflow.set_tracking_uri("sqlite:///mlruns.db")
mlflow.create_experiment(EXPERIMENT_NAME)
mlflow.set_experiment(EXPERIMENT_NAME)
Once you start a Run youu can log parameters, metrics and the model with its artifacts. Runs will be stored in mlruns directory wherever your run the code.
with mlflow.start_run(experiment_id=EXPERIMENT_ID, run_name=RUN_NAME) as run:
# mlflow log parameters
mlflow.log_param("classifier_C",param)
# mlflow log metrics
mlflow.log_metric("pipeline_test_score",accuracy_score)
# mlflow log model
mlflow.sklearn.log_model(clf, "classifier_titanic")
Terminal:§ mlflow ui --backend-store-uri sqlite:///mlruns.db
MLflow UI will appear on your browser, so you can :
- Track experiments
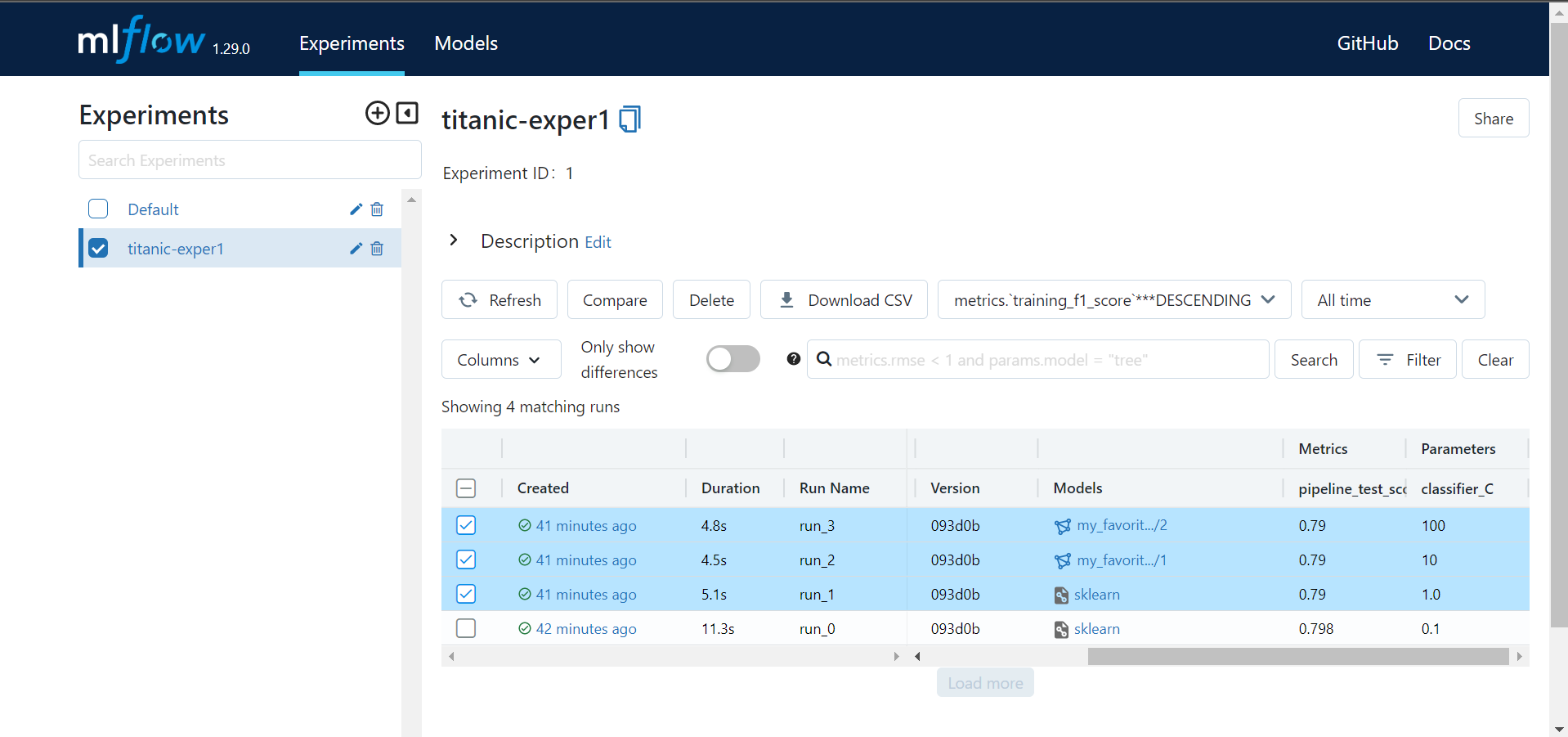
- Track runs (informations, parameters, metrics, artifacts)
In artifacts of each run, you'll find MLmodel, conda.yaml and other files which discribes the virtual environment required to reproduce the model.

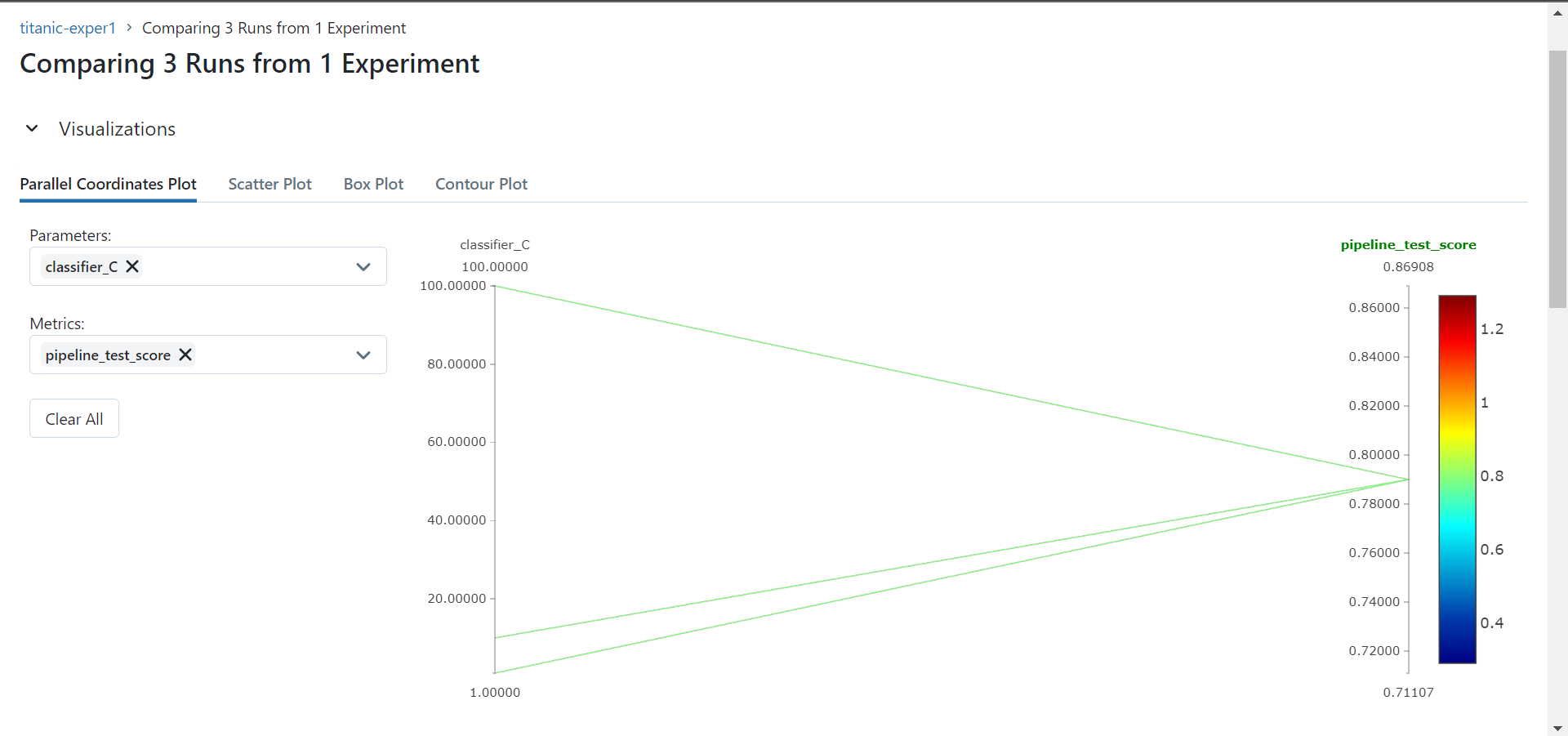
- Compare runs
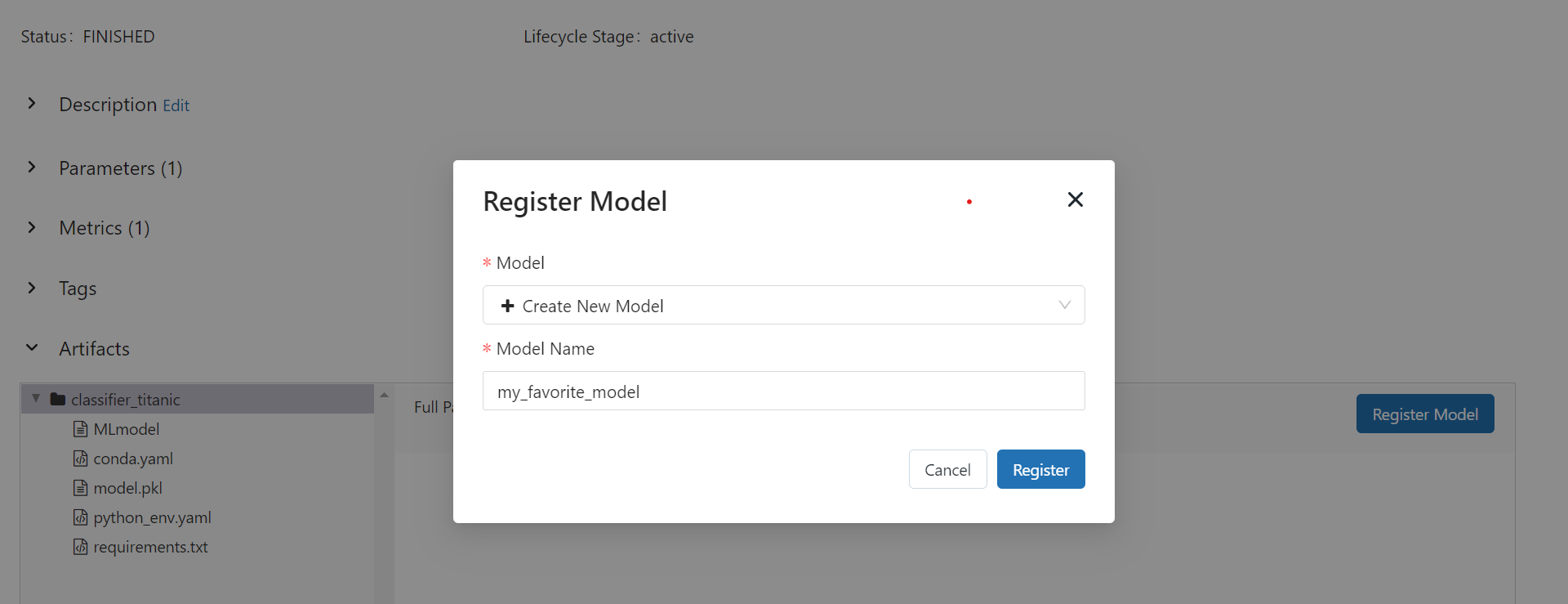
- Register models
- Manage versions and transitions
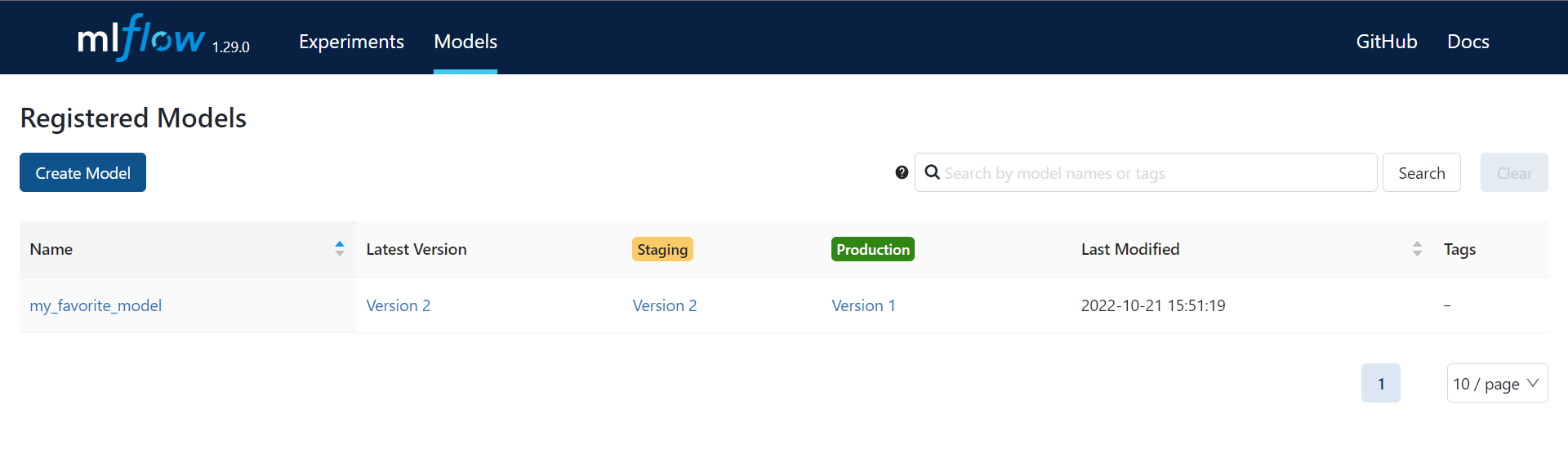
You can also create registries and manipluate them, by code : https://www.mlflow.org/docs/latest/model-registry.html