In a nutshell, we need to load a dictionary into the memory and check the misspelled words of another file. Within the default dictionary, mind you, are 143,091 words. We need to check misspellings of several movie scripts(e.g. Lalaland, Birdman, etc) and some other large files. So, there will be several thousands of words. Loading and checking such a huge number of words take time and precious memory. The challenge ahead is to implement the fastest spell possible! By "fastest," though, we’re talking actual "wall-clock," not asymptotic, time.
The TRIES data structure has been used in this case.
$clang -fsanitize=signed-integer-overflow -fsanitize=undefined -ggdb3 -O0 -Qunused-arguments -std=c11 -Wall -Werror -Wextra -Wno-sign-compare -Wshadow -c -o speller.o speller.c;clang -fsanitize=signed-integer-overflow -fsanitize=undefined -ggdb3 -O0 -Qunused-arguments -std=c11 -Wall -Werror -Wextra -Wno-sign-compare -Wshadow -c -o dictionary.o dictionary.c;clang -fsanitize=signed-integer-overflow -fsanitize=undefined -ggdb3 -O0 -Qunused-arguments -std=c11 -Wall -Werror -Wextra -Wno-sign-compare -Wshadow -o speller speller.o dictionary.o
$./speller texts/ANY_FILE.txt
...
...
MIA
Mia
Mia
Mia
Sebastian's
L
WORDS MISSPELLED: 955
WORDS IN DICTIONARY: 143091
WORDS IN TEXT: 17756
TIME IN load: 0.18
TIME IN check: 0.02
TIME IN size: 0.00
TIME IN unload: 0.19
TIME IN TOTAL: 0.39
- Basic knowledge about pointers.
- Basic knowledge about Trie data structure.
- Knowledge of declaring and modifying custom libraries.
Luckily we do not have to start from the scratch. We will be provided some files such as:
speller.c: This is the skeleton of the whole program. The key functions of this file are:load(),check(),unload(), &size(). Unfortunately they do not reside in this file.dictionary.c: We have to implement the above-mentioned functions here. To clarify,load()loads the dictionary into memory.check()checks spellings of a given file.unload()unloads memory.size()calculates the number of loaded words into memory.
dictionary.h: This is the custom library which contains the tries structure and prototypes of functions we're going to write.
Without further ado let’s dive into the mysterious(!really ;) world of tries. To understand tries better, we can watch the following video. Now, let's talk about the functions one after another.
typedef struct _trie
{
// for a-z & apostrophe(')
struct _trie* alphabet[27];
bool isWord;
}
trie;
The basic idea is we’re going to scan the words/strings of the dictionary file and loop around it. If the character is valid, we load it into memory and if it is the last character, we will set isWord = true;
We know that tries start from a root node. To execute other functions(e.g., unload() and check()) we need a common root which can be used by all functions. As we were instructed not to edit speller.c which contains the main function, we have to create root elsewhere.
Personally, I created root in dictionary.c. If I had created the root node in load(), I would have to pass it to other functions. I decided to create a GLOBAL root instead.
Each character of a string, creates a new node in tries. So, I wrote a separate function called create() for the root node and other child nodes.
trie* create()
{
// Create a new trie
trie* new_trie = NULL;
new_trie = (trie*)calloc(1, sizeof(trie));
// Check if memory has been allocated
if (new_trie == NULL)
{
fprintf(stderr, "Can not allocate memory\n");
exit(1);
}
return new_trie;
}
A piece of advice I want to share to humanity is, PLEASE, DO NOT FORGET TO CLOSE YOUR FILE.
The beauty of tries is loading and checking information are almost identical. Here we’re going to scan words/strings from any given file and loop around it character after character.
Suppose “cat” is the word we are looking for. Under root node we have 27 NULL child nodes for alphabet(a-z) and apostrophe(‘).
Let’s start form the char ‘c’. It is the 3rd character in alphabet and 2nd in our array(e.g., alphabet[2]). If there are any words starting with ‘c’ in dictionary, alphabet[2] of root will not be NULL anymore as another 27 child nodes has been created from ‘c’. We will repeat this process for ‘a’ and ‘t’ as well. If we find isWord == true, after creating a node form ‘t’ which is the last character of 'cat', HURRAY! We have successfully found the word.
This one is easy. It returns the total number of words loaded into memory.
Here our goal is to free each and every block of memory we’ve allocated dynamically. The idea is very simple. We again start form the root, if any indices of root->alphabet[i] != NULL; we get inside of alphabet[i] and make it the new root. We repeat the above process using recursion until we reach a node where all indices of alphabet[] are NULL which means we’re inside of the last child. Now free this node and return to the immediate parent.
// Unloads dictionary from memory, returning true if successful else false
bool unload(void)
{
// Check if root_node has been allocated or not
if (root_node != NULL)
{
// If allocated delete root with all corresponding children
delete_root(root_node);
return true;
}
else
return false;
}
// Delete all root nodes using recursion
void delete_root(trie* root)
{
for (int i = 0; i < 27; i++)
{
if (root->alphabet[i] != NULL)
{
delete_root(root->alphabet[i]);
}
}
free(root);
root = NULL;
return;
}
Check for any memory leak by executing the following command in bash.
$ valgrind --leak-check=yes ./speller file_that_you_want_to_check.txt
Do you remember the advice in all capital at the end of load()?
I was getting continuous memory leaks after executing speller.c. It took me almost a day to find out that I had forgotten to close the file in load(). I should have closed the file right away after the loading process ends. LESSON LEARNT!
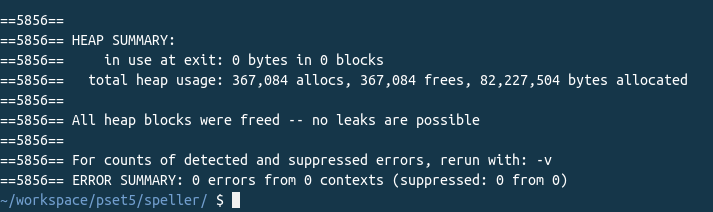
This is the desired Valgrind output.
It returns resource usage measures.
Why do we pass before and after by reference (instead of by value) to calculate, even though we're not changing their contents?
If we pass arguments by value, it creates copies of the variables using the parameters. A variable of type rusage consumes 144 bytes of memory. The variables before and after takes 288 bytes in memory together. It will take another 288 bytes (total 576 bytes) if we pass the arguments by value. In order to save this amount of memory, we pass by reference here.
Using the for loop we scan every single character of a given file until we reach EOF using int c = getchar(file_name). We have declared an string called word[] which will be storing the word that we want to check. We will also be counting the indices of the string word[], the number of misspelled words, and the total number of words present in that file.
If the character c is an alphabet or an apostrophe, we insert it in the array, increment index by 1. We will continue insertion until we find any newline character(e.g., ‘\n’), the length of a word does not exceed the maximum word length(e.g., 45), or the word contains any digit. If any of the above-mentioned situations arises except the first one, we ignore the whole word we have been inserting.
We will insert a new line character(e.g., ‘\n’) after reaching the same in the input file followed by one or multiple characters. As we have found a whole word at this point, we will check it’s spelling using a function called check(), calculate the time it took, and store it’s return value in a variable(e.g., misspelled). If the the word is misspelled, we will increment the number of misspelled words, print it and fasten our seat-belts as we have to start collecting the next word to check.
Why fgetc has been used to read each word's characters one at a time rather than fscanf with a format string like "%s" to read whole words at a time? Put another way, what problems might arise by relying on fscanf alone?
fscanf terminates the scanning process right away when it reaches space character which will not be helpful to us as we are going to read files containing words after word separated by spaces.
So that the reference which will be passed to the parameters can not be modified.