DBRL is a toolkit used for training reinforcement learning recommendation models. The name DBRL stands for : Dataset Batch Reinforcement Learning, which differs from traditional reinforcement learning in that it only uses static dataset to train a model, without any further interaction with the environment. See Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems for a comprehensive introduction.
After the training, the model can be used for online serving. And indeed It has an online part, which mainly leverages Flink and the trained model for online recommendation. See FlinkRL for more details. The full system architecture is as follows :
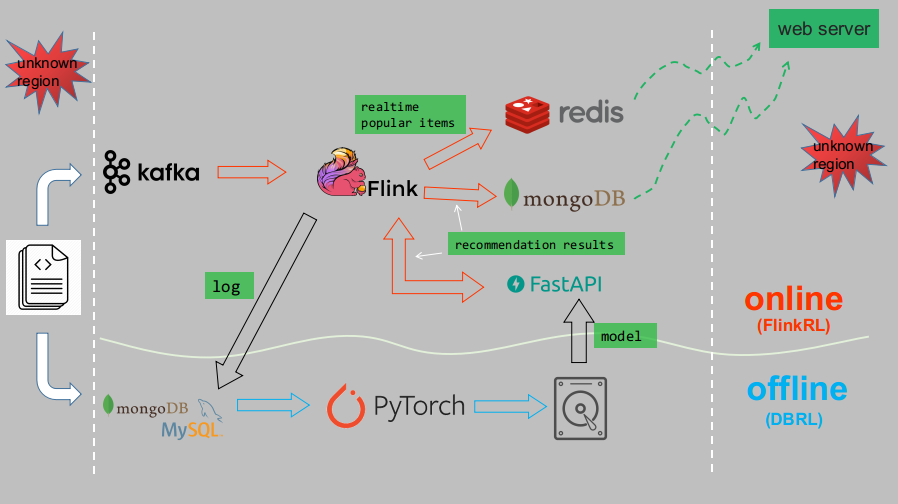
DBRL currently contains three algorithms:
- REINFORCE (YouTube top-k off-policy)
- Deep Deterministic Policy Gradient (DDPG)
- Batch Constrained Deep Q-Learning (BCQ)
The dataset comes from a competition held by Tianchi, a Chinese competition platform. Please refer to the original website for full description. Note that here we only use the round2 data.
You can also download the data from Google Drive.
Dependencies: python>=3.6, numpy, pandas, torch>=1.3, tqdm.
$ git clone https://github.com/massquantity/DBRL.gitAfter downloading the data, unzip and put them into the DBRL/dbrl/resources folder. The original dataset consists of three tables: user.csv, item.csv, user_behavior.csv . We'll first need to filter some users with too few interactions and merge all features together, and this is accomplished by run_prepare_data.py. Then we'll pretrain embeddings for every user and item by running run_pretrain_embeddings.py :
$ cd DBRL/dbrl
$ python run_prepare_data.py
$ python run_pretrain_embeddings.py --lr 0.001 --n_epochs 4You can tune the lr and n_epochs hyper-parameters to get better evaluate loss. Then we begin to train the model. Currently there are three algorithms in DBRL, so we can choose one of them:
$ python run_reinforce.py --n_epochs 5 --lr 1e-5
$ python run_ddpg.py --n_epochs 5 --lr 1e-5
$ python run_bcq.py --n_epochs 5 --lr 1e-5At this point, the DBRL/resources should contains at least 6 files:
model_xxx.pt, the trained pytorch model.tianchi.csv, the transformed dataset.tianchi_user_embeddings.npy, the pretrained user embeddings in numpynpyformat.tianchi_item_embeddings.npy, the pretrained item embeddings in numpynpyformat.user_map.json, a json file that maps original user ids to ids used in the model.item_map.json, a json file that maps original item ids to ids used in the model.