This project is based for legacy applications that works with positional files to process data. The objetive is read these positional files when they arrives in AWS S3, and then send to a dataware-house like AWS Redshift, and finally read the results with a Business Intelligence tool as AWS QuickSight. It's a simple flow, but very rich and usefull for these kind of application.
To simulate this scenario, it is using Soccer Brazilian Championship. The files in folder '/data' contains three positional files that can be read and loaded into Redshift throught AWS Glue.
The files contains positional data like this:
2708202002305Neo Química Arena Rodolpho Toski Marques Corinthians Fortaleza Tiago Nunes Rogério Ceni 101501010501141211130206000521101007
And the target is the folowing:
{ "dia":"27", "mes":"08", "ano":"2020", "hora":"02", "minuto":"30", "rodada":"5", "colocacao_mandante":"10", "colocacao_visitante":"15", "gols_mandante":"0", "gols_visitante":"1", "escanteios_mandante":"01", "escanteios_visitante":"05", "faltas_mandante":"01", "faltas_visitante":"14", "chutes_bola_parada_mandante":"12", "chutes_bola_parada_visitante":"11", "desefas_mandante":"13", "desefas_visitante":"02", "impedimentos_mandante":"06", "impedimentos_visitante":"00", "chutes_mandante":"05", "chutes_visitante":"21", "chutes_fora_mandante":"10", "chutes_fora_visitate":"10", "estadio":"Neo Química Arena", "arbitro":"Rodolpho Toski Marques", "time_mandante":"Corinthians", "time_visitante":"Fortaleza", "tecnico_mandante":"Tiago Nunes", "tecnico_visitate":"Rogério Ceni" }
Below is showed the contract positions about the file.
| name | begin | end | size |
|---|---|---|---|
| dia | 1 | 2 | 2 |
| mês | 3 | 4 | 2 |
| ano | 5 | 8 | 4 |
| hora | 9 | 10 | 2 |
| minuto | 11 | 12 | 2 |
| rodada | 13 | 13 | 1 |
| estadio | 14 | 53 | 40 |
| arbitro | 54 | 83 | 30 |
| time mandante | 84 | 96 | 13 |
| time visitante | 97 | 109 | 13 |
| técnico mandante | 110 | 124 | 15 |
| técnico visitante | 125 | 139 | 15 |
| colocação mandante | 140 | 141 | 2 |
| colocação visitante | 142 | 143 | 2 |
| gols mandante | 144 | 144 | 1 |
| gols visitante | 145 | 145 | 1 |
| escanteios mandante | 146 | 147 | 2 |
| escanteios visitante | 148 | 149 | 2 |
| faltas mandante | 150 | 151 | 2 |
| faltas visitante | 152 | 153 | 2 |
| chutes bola parada mandante | 154 | 155 | 2 |
| chutes bola parada visitante | 156 | 157 | 2 |
| defesas mandante | 158 | 159 | 2 |
| defesas visitante | 160 | 161 | 2 |
| impedimentos mandante | 162 | 163 | 2 |
| impedimentos visitante | 164 | 165 | 2 |
| chutes mandante | 166 | 167 | 2 |
| chutes visitante | 168 | 169 | 2 |
| chutes fora mandante | 170 | 171 | 2 |
| chutes fora visitante | 172 | 173 | 2 |

- The files can be uploaded into S3
- S3 triggers a Lambda Function that will starts a Glue Job
- The Glue Job will read this file and process with PySpark to do the ETL Job.
- After transformation, the DataFrame will be streamed into a SQS queue.
- SQS will trigger a lambda funtion to do transational operations about each line/event like data normalization
- Lambda will save these normalized data into Redshift
- The data from Redshift could be readen from QuickSight
- The data from S3 could be readen from Athena
- Every trigger there is an exception flow
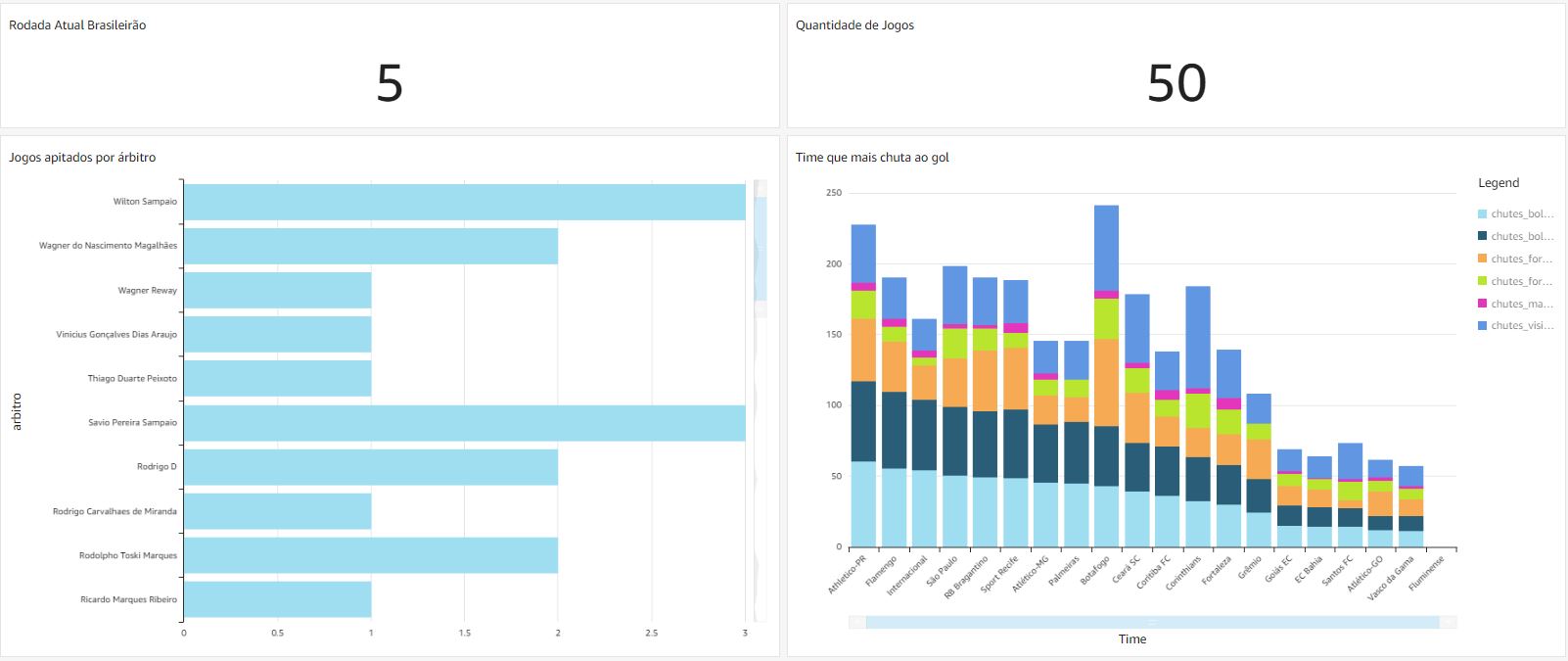
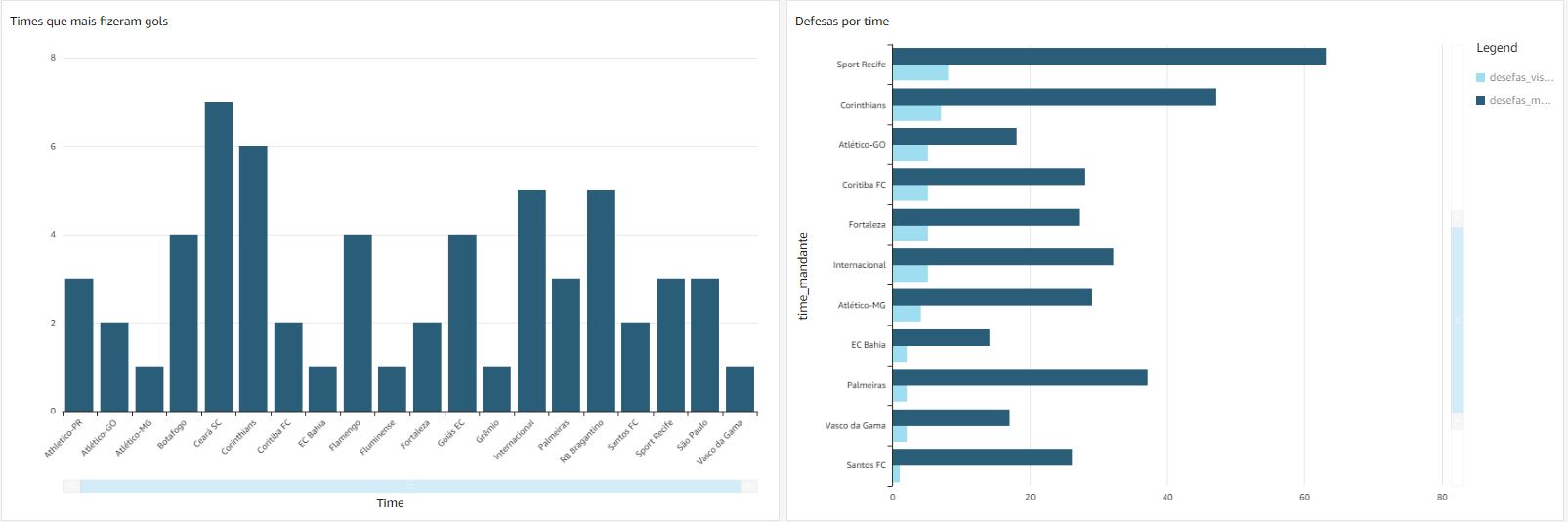
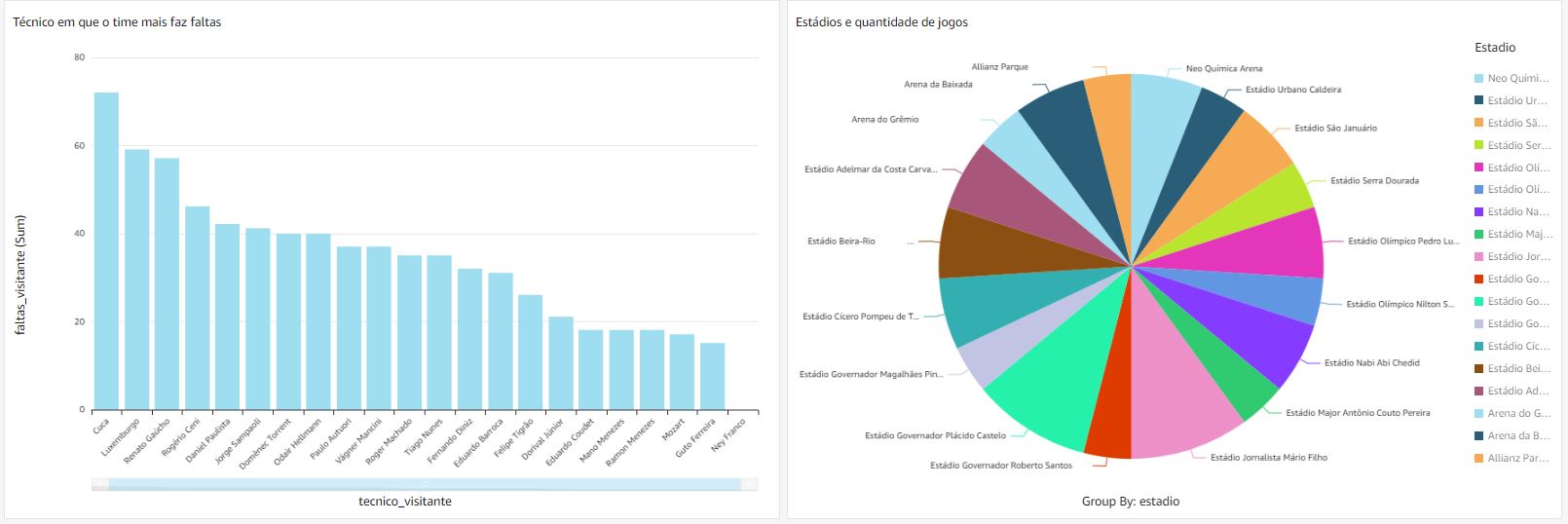
After all process has been executed with sucess, we could see the results inside Redshift. In this example was created some graphs and reports about the Brasileirão, and it will changing according new files been processed. Here it was listed:
- The current game round
- Total rounds
- More gols kicks
- More gols about all teams
- The coach that his team had done more fouls.
- The referee who whistled more games
All resources were priced in AWS Calculator, the following link, the final price of this architecture, excluding Lambda, SQS, S3 and Cloudfront services, because it is Free Tier Elegible or the value is low to input in this pricing cotation.
Click here for Pricing Project
The project is for lab and studies, it is not operating so as not to keep costs in production. That's a reason not existing a Continuos Develivy implemented too.
To setup the environment:
- Use folder /Iaac in this repository (Infraestructure as a Code) to publish the S3 buckets, SNS, Redshift and also SQS queues in AWS CloudFormation.
- In Lambda functions there is the SAM Template for creating (CloudFormation) the backend applications as well.
- In folder
/sqlthere are two scripts:DDL - RedShift Tables.sqthat is DDL for redshift tables andQuicksight Custom Query.sqlthat is the custom query used in Quicksight to explore some graphs.