In this project, I assembled a corpus of the U.S. Supreme Court's entire body of opinions and performed unsupervised topic modeling of its 14th Amendment jurisprudence from the 1700s to present using latent semantic analysis, k-means clustering, and other natural language processing techniques.
This analysis serves as the foundation for further exploration of the 64,000+ document corpus to gain insight into judicial methods, to add to the body of knowledge of law and linguistics, to perform historical and predictive analytics, and to improve upon legal research algorithms.
I used Scrapy, BeautifulSoup, bash, SQL, and Django to webscrape 64,000+ opinions from the web along with citation information, which I merged into a master database.
I wrote a custom pipeline using regular expressions, NLTK, scikit-learn, and LexNLP to remove legal-domain stopwords. Because law has such a specialized vocabulary and idiosyncratic writing style, I needed to custom-write a pipeline to account for things (e.g., citations) that most ordinary NLP machine-learning kits can't handle off-the-shelf.
After tokenizing, lemmatizing, and removing stop words, I began processing the opinions.
Fragment of a custom component for the NLP pipeline:
def stop_citation_noise(text):
'''
Takes in a string, returns a string.
Use to remove unwanted citations to legal reports,
document headers, appendices, and artifacts of
digital processing.
'''
stops = []
for cite in get_citations(text, return_source=True, as_dict=True):
# if len(cite['citation_str']) < 70:
# text = text.replace(cite["citation_str"], " ")
# cite['citation_str'] = cite['citation_str'].replace(str(cite['volume']) + cite['reporter'] + str(cite['page']), " ")
# stops.append(cite["citation_str"])
buildcite = str(cite['volume']) + " " + cite['reporter'] + " " + str(cite['page'])
if cite['page2']:
buildcite += ', '+str(cite['page2'])
stops.append(buildcite)
return stops
def replace_citations(text):
stops = stop_citation_noise(text)
for stop in stops:
text = text.replace(stop, " ")
return text
I began by analyzing the 14th Amendment, extracting those cases with regex (n=4579). First, after preprocessing, I vectorized the vocabulary using TF-IDF to obtain a frequency measure for each word in the corpus and prepare the documents for singular value decomposition and latent semantic analysis.
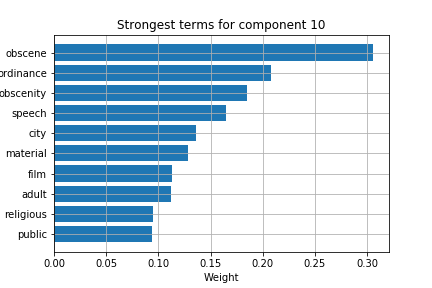
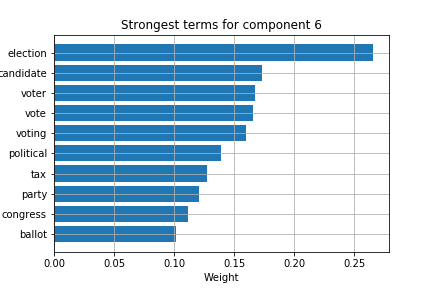
Using LSA, I performed topic clustering and extracted the top terms per topic for each cluster. I performed this first on the corpus as a whole, then on the data in segmented time using a rolling window function.
A sampling:

Modifying the source code for Python's WordCloud package, I wrote a custom function to generate word clouds that adjusted a word's size based on frequency and color based on topic. I then wrote a script to generate word clouds iteratively for each rolling window.
A sampling:
1980-2000
_cloud.png?raw=true)
1970-1990
_cloud.png?raw=true)
1950-1970
_cloud.png?raw=true)
1940-1960
_cloud.png?raw=true)
To obtain better topic modeling, I used a k-means algorithm to cluster terms, first in the whole corpus.
I used silhouette score testing to judge the number of clusters.
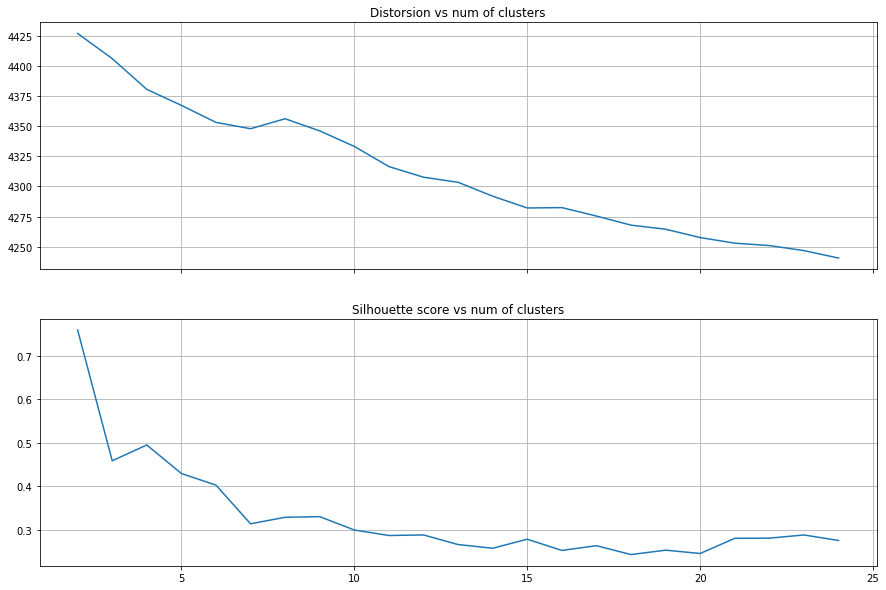
Applying the k-means function to the data using a rolling window enabled me to model the 14th Amendment's evolving meaning over time.
Whole corpus k-means terms:

- spaCy, NLTK, LexNLP
- Django, Scrapy, bash, RESTful API
- scikit-learn, numpy, pandas
- wordcloud, PIL, OpenCV, Plotly, Plotly Express
- I am indebted to CourtListener for bulk data downloads of case law and to Oyez for citation and other information.
- Thanks to Michael J. Carlisle for inspiration, collaboration, and good company. Medium, GitHub.