{kind=link}
{kind=link}
{kind=link}
{kind=link}
We do 5 million transaction today and use postgress DB as the back end. Our volume is expected to grow by 4 folds in few months. The DB is already choking. The record has account number and balance. Credits should have high consistency ( ~ 1000 transactions per day) and debits should have high availability. We are considering open source in-memory data base.
Started by looking at available solutions for this need: high availability, coupled with high growth and tunable consistency(credits need high consistency; debits high availability). Instead of looking at purely memory based solutions like memcached/varnish, where redundancy, replication and fault-tolerance were after-thoughts, preferred databases which are designed with redundancy and fault-tolerance while exploting in-memory caching.
Given the requirements, we need databases which fall somewhere under the AP spectrum(of Brewer's CAP theorem) with tunable consistency. Availaibilty is the primary concern and Partitioning is important because when it comes to high growth we need systems that scale horizontally.
Couchbase, Cassandra and Riak were potential candiates - out of which decided to test out Couchbase and Cassandra, preferred because of their larger eco-system.
- A Rest service based on gin which will host end-end integration with databases:
balance_service. This service supports GET balance and PATCH balance(to increment/decrement balance), tests are underbalance_service/balance_service_test.go. - Utility to populate databases for testing with balance data:
db_filler. This utility will also generate user Ids for benchmarking. - Benchmarking tests compatible with Go benchmarking:
benchmark_test. There are 2 benchmarking tests for both Cassandra and Couchbase for reading and writing directly. These tests uset he user ids generated bydb_filler - Also used Postman for stress testing the rest service.
For simplicity's sake - the model for our rest-service will just contain: |UserId|Balance|
Both in Couchbase and Cassandra, the actual balance field is a counter -- and couchbase needs an explict reference to the counter's doc id, while cassandra can refer primary key from the main table. Keeping balance as a counter field helps in understanding tunable consistency levels supported by both DBs.
- The rest service can be started with:
go run balance_service.go. Useexport GIN_MODE=releaseto test the service in benchmarking mode. - DB filler utility can be started with:
go run db_filler.go -records=2000 -cassandra=true. See options:
-cassandra
Turn on to use Cassandra
-csv
Turn on to dump CSV file for POSTMAN
-dump string
File to dump generated user ids to (default "../user_ids_to_test.txt")
-records int
Records to fill (default 10000)
- Benchmarking test can be started with:
go test benchmark_test.go -test.bench="BenchmarkCouch_Read". Use wildcards fortest.benchoption to run different tests. Options include:
-cassandra
Turn on to use Cassandra
-cpuprofile string
Write cpu profile to given file (default "./cpustat.prof")
-dump_file string
Text file containing list of user ids to test (default "../user_ids_to_test.txt")
-readers int
The number of reader goroutines (default 10000)
-updaters int
The number of writer goroutines (default 10000)
For couchbase, after installing, hit http://localhost:8091/ and create a bucket named "default". it's enough to run db_filler.go to get started.
For Cassandra on the otherhand, we need to create a keyspace with right replication strategy and two tables:
create keyspace default with replication = {'class': 'SimpleStrategy', 'replication_factor' : 1};
create table balance (user_id text PRIMARY KEY) with caching = {'keys': 'ALL'};
create table balance_counters (user_id text PRIMARY KEY, balance counter);
Tests were run on a typical laptop with i7/8Gb Ram/SSD running Ubuntu 14.04 Desktop. Unfortunately couldn't deploy a cluster of nodes for testing. Would strongly recommend doing that to get the whole picture.
The testing strategy is to:
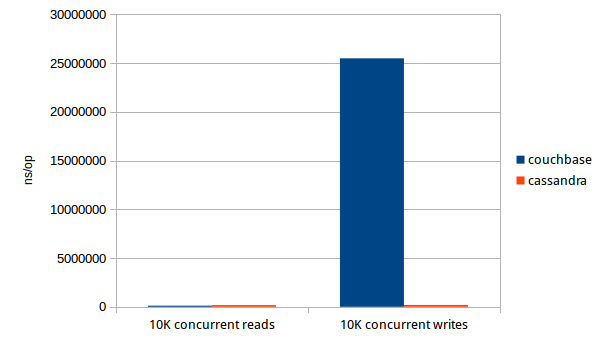
- Benchmark time and CPU for 10000 times of concurrent reads(across 8 cores, each core using 2 threads, apart from the main routine)
- Benchmark time and CPU for 10000 times of concurrent updates
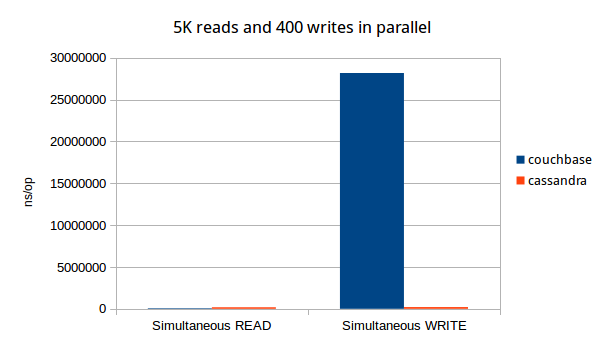
- Simultaneously run 5000 concurrent reads and 400 writes, simulating our read vs write ratio in real world scenario. Measure time.
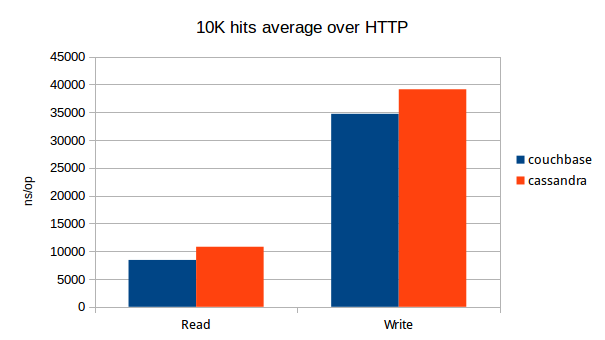
- Iteratively hit the rest service to match 10000 times, measure time and validity of API responses(using Postman runner)
Note: Couchbase rest service could never complete over 2000 iterative hits - I suspect it could be a problem with the couchbase go client: gocb. Both gin(go rest framework) and directly hitting couchbase had no problems for 10000 hits.
Did write some helper methods to measure memory but decided againt using it. Measuring memory would be tricky at best, since all of this is running on the same desktop which is not configured for VM swappiness/large pages etc. Here's what I observed(using htop when the tests are running):
- Couchbase's memory usage was pretty low: ~100MB each on startup for memcached and couchbased. memcached's memory usage increased as more reads/updates are done as expected.
- Cassandra was pretty consistent at ~4GB throughout(because of Java I guess :). Cassandra probably has in-built benchmarking with JVM heap statistics though.
Raw readings are in readings.csv. Units are ns/op unless mentioned.
- Cassandra's CQL could be an advantage in replacing/supplementing existing RDBMS. Besides being similar to SQL, there is a possiblity of potential code reuse.
- Cassandra simply refused to work till all details were correctly configured: replication, consistency, datacenter configuration etc. In hindsight, this makes a lot sense.
- It was much easier to get started with Couchbase but I had issues with throughput, gocb's API comes of unrefined compared to gocql.
- Couchbase reads are faster than cassandra, but not by much.
- Cassandra's write timings are consistent with reads. Couchbase writes suffer on concurrent operations
- Cassandra's CPU usage is lower than Couchbase.
- Hardware recommendations : This depends on the data size/traffic etc. But Couchbase's AMI for EC2 recommends M3, which makes sense for both Cassandra and Couchbase. 2 M3.large(8gb ram + SSDs) boxes per datacenter would be a good starting point, with 1 replica per datacenter.