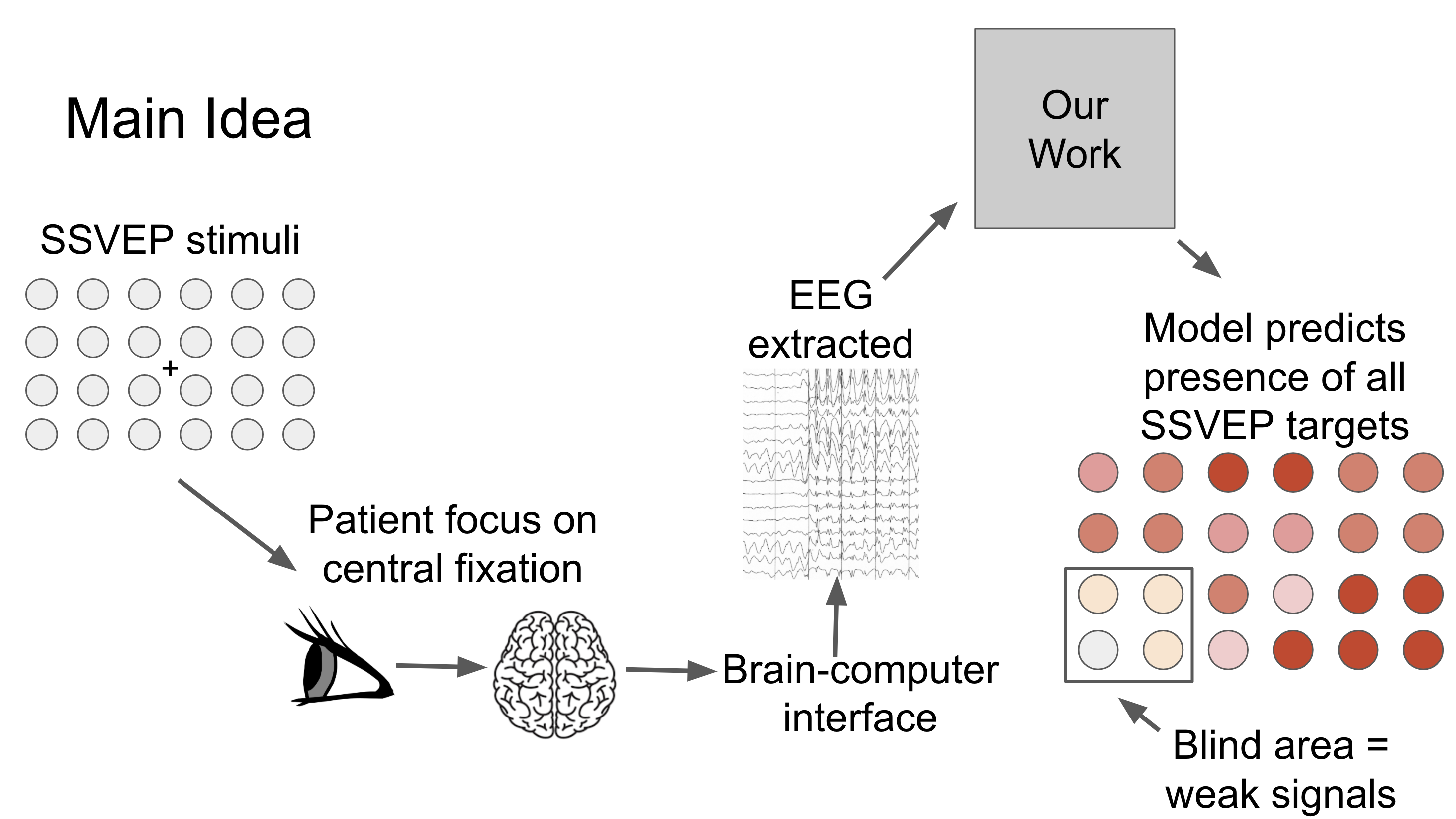
Using multi-task learning to capture signals simultaneously from the fovea efficiently and the neighboring targets in the peripheral vision generate a visual response map. A calibration-free user-independent solution, desirable for clinical diagnostics. A stepping stone for an objective assessment of glaucoma patients’ visual field. Read more...
Our neural network is composed of four convolution blocks, responsible for learning EEG representations across all target frequencies. The fifth convolution layer is a multi-task learning block, where it learns to differentiate multiple SSVEP target frequencies.

C1 block was designed to extract the spectral representation of the EEG input, as it performs convolution across the time dimension, capturing features from each EEG channel independently from the others. C2 block was designed for conducting spatial filtering, as it performs convolutions across the channel dimension. The objective of this layer is to learn the weights of all channels at each time sample.
For feature learning, there are two convolution blocks (C3 and C4). We explored different dilation configurations on C3 and C4 blocks. As the kernel size needed for signals is much larger than for images, dilation convolutions allow us to expand the receptive field, perform feature learning with a smaller kernel size, produce a smaller model, and potentially increase performance.

The fifth and final convolution block learns to differentiate multiple SSVEP target frequencies. We made use of methods from multi-task learning and designed this block to produce multiple outputs. In classic multi-task learning architectures, each task is separated into task-specific layers, where each layer is responsible for learning to identify each task. But instead of duplicating a convolution layer for each output, we perform convolutions by groups. We are essentially performing separate convolutions within a single convolution layer. This allowed us to train multiple tasks in parallel efficiently on a single GPU, and we can dynamically tweak our model scale to any number of tasks effectively, which is potentially suitable for other multi-task learning applications.
To use our model:
model = MultitaskSSVEP(
num_channel=11,
num_classes=40,
signal_length=250,
)
x = torch.randn(2, 11, 250)
print("Input shape:", x.shape) # torch.Size([2, 11, 250])
y = model(x)
print("Output shape:", y.shape) # torch.Size([2, 40, 2])To use our model as a classifier:
model = MultitaskSSVEPClassifier(
num_channel=11,
num_classes=40,
signal_length=250,
)
x = torch.randn(2, 11, 250)
print("Input shape:", x.shape) # torch.Size([2, 11, 250])
y = model(x)
print("Output shape:", y.shape) # torch.Size([2, 40])We compare classification accuracies against TRCA and FBCCA across subjects.

Our model is a unified system that generates a visual response map by learning to distinguish 40 frequencies. We predict the presence of all target frequencies simultaneously. As such, this enables us to visualize what the user has seen with a visual response map.

They dataset we used in our experiment is Benchmark dataset by Yijun Wang, Xiaogang Chen, Xiaorong Gao, Shangkai Gao.
If you use the model in your research or found this repo helpful, please cite our IEEE SMC paper:
@inproceedings{khok2020deep,
title={Deep Multi-Task Learning for SSVEP Detection and Visual Response Mapping},
author={Khok, Hong Jing and Koh, Victor Teck Chang and Guan, Cuntai},
booktitle={2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC)},
pages={1280--1285},
year={2020},
organization={IEEE}
}
This project is BSD-style licensed, as found in the LICENSE file.