此项目是试题知识点标注。属于多标签文本分类任务。
这里使用TextCNN, Transformer-Encoder等实现多标签分类模型。
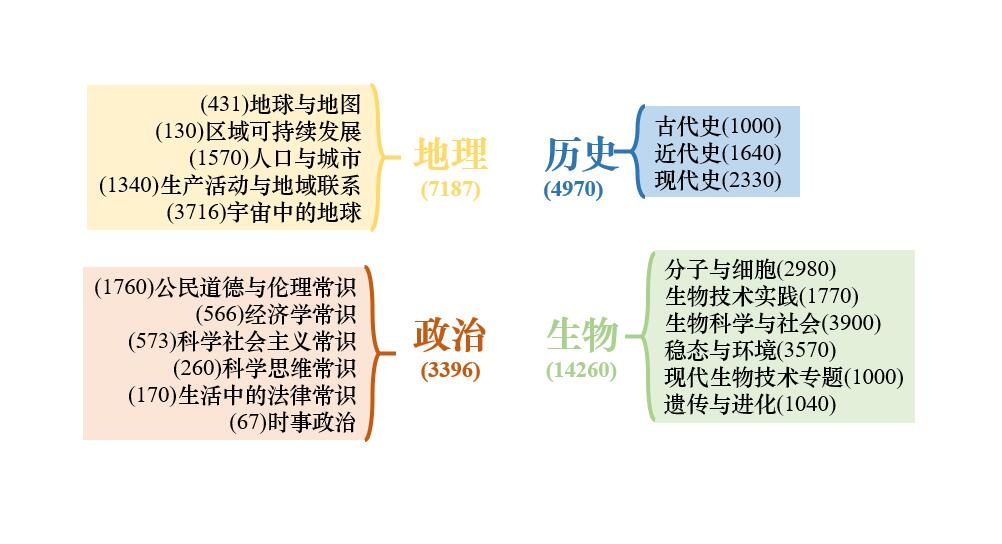
数据集包含高中4个科目的题目,每门科目下又有不同的主题。如:历史-古代史(1000) 括号内的数字表示这个主题有1000道题目,总共有29000多道题目。同时,每道题目有许多知识点,如下:

项目框架
│─data
│ │─data.rar # 数据集,包括停词
│
│─textcnn
│─transformer-encoder
│
首先需要解压原始数据集data.rar。
数据的预处理在transformer-encoder的训练代码中(train.ipynb),处理后的数据会保存在train_data.pkl中。
多标签数据的构建使用torchtext。
为了测试多标签分类的效果,这里只使用了题目中列出的知识点,并且删除了出现次数少于样本1%的知识点,所以剩下73个知识点。 具体可到相关目录查看相关处理程序及模型。 其中[sgns.sogou.char]使用了sogou的预训练向量可从这里下载(https://github.com/Embedding/Chinese-Word-Vectors)。
要求:
- requirement.txt
参考:
- https://github.com/jiangnanboy/intent_classification
- https://github.com/Light2077/Text-Classification
contact
如有搜索、推荐、nlp以及大数据挖掘等问题或合作,可联系我:
1、我的github项目介绍:https://github.com/jiangnanboy
2、我的博客园技术博客:https://www.cnblogs.com/little-horse/
3、我的QQ号:2229029156