To learn about this project, please read the full report.
This work was the final project for DSCC440 Data Mining at the University of Rochester.
"Wisdom of the crowd" is the idea that collective human knowledge can be more accurate than that of a single expert, due to the fact that a large number of responses can cancel out the noise associated with each individual judgement. The advantage of this extends to crowd-sourcing: it is believed that people are better at problem-solving and innovating as a collective.
Twitter has become an important communication channel in times of emergency. By utilizing crowd-sourcing, tweets can be analyzed to provide accurate and real-time reports of natural disasters. Because of this, many agencies such as news stations and disaster relief organizations actively monitor Twitter for natural disaster reports.
However, human speech has an overwhelming amount of complexities that can make it unclear whether a tweet is announcing a real natural disaster or not. While it is clear to humans that some tweets may include a figure of speech, it can be a challenge for a machine to discern the tweet’s meaning.
In this project, our aim was to build a predictive classification model using natural language processing techniques to discern which tweets are about real natural disasters and which tweets are not.
“How accurately can we predict whether or not a Tweet is announcing the occurrence of a natural disaster using NLP?”
The dataset that was used originates from a Kaggle competition, titled Natural Language Processing with Disaster Tweets, and contains tweets that were hand classified.
The data was provided in two parts: a training set and a testing set. There were 7613 observations in the training data set and 3263 rows in the testing data set, for 10876 tweet observations in total.
There were four columns in the test set: id, keyword, location, and text. Text was the content of the tweet, which made it the most useful of the columns. The training set had the same four columns, with one additional one: target. This column was a binary value: "1" for disaster or "0" for not a disaster.
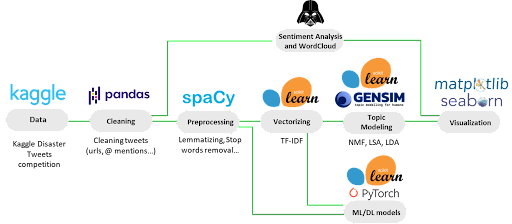
The above is an overview of our workflow. Details to be found in the following sections.
- Removed URLs
- Removed usernames/"@" mentions
- Unescaped HTML entities
- Removed all non-alphanumeric characters except spaces and quotations marks
- Removed canned phrases such as "I liked a YouTube video"
- Converted text to lowercase
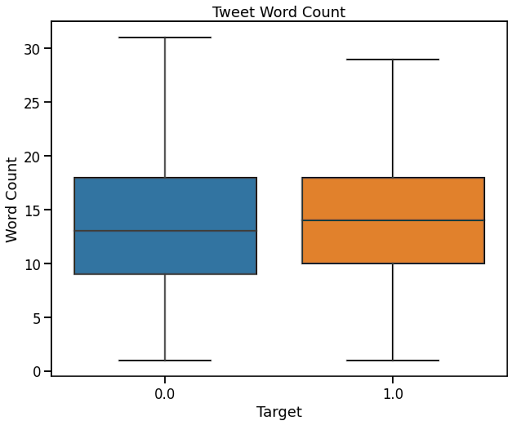
The above boxplot clearly shows that there was no association between the number of words in a tweet and whether or not the tweet was about a real disaster.
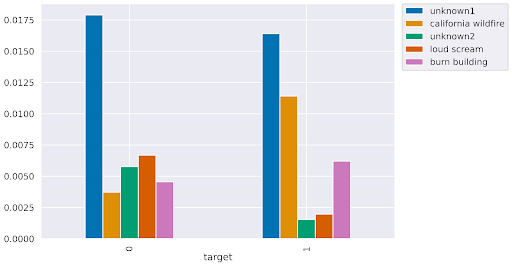
It’s clear that topics such as “california wildfire” are related to real natural disasters, whereas “loud scream” doesn’t exactly mean there’s a natural disaster happening.


Two Python libraries were used to perform sentiment analysis: textblob (TextBlob) and vaderSentiment (VADER).
The polarity boxplots illustrate that there is quite a significant difference in polarity and overall sentiment between tweets that refer to a real disaster and tweets that do not refer to a real disaster.


As demonstrated by the two word clouds above, the frequent words in real disaster tweets are generally more negative, intense, and/or vulgar; comparatively, tweets that aren't about real disasters seem to have words that generally have more of a positive connotation. It is, however, clear as to how those tweets could be misinterpreted as announcements of real disasters.
We removed stop words from and lemmatized the text using the spacy library. To prevent any data leakage, we incorporated TF-IDF tokenization into an sklearn 5-fold cross-validation pipeline. Hyperparameters were tuned using GridSearchCV, which is part of the sklearn library.
Result:
- Baseline Accuracy: 0.7845
- Baseline F1: 0.6949
- Accuracy after GridSearchCV#1: 0.7933
- F1 after GridSearchCV#1: 0.7293
LSTM is great for NLP tasks, as it can memorize important information in sequential data.
We used Python's torchtext and spacy libraries to load the tweets and build vocabulary. We then used the BucketIterator from the torchtext library to group the tweets of similar lengths into batches. Having batches with similar length examples provides a lot of gain for recurrent NNs and transformers where padding will be minimal. We then used 3-fold cross validation and trained the LSTM in 12 epochs for each fold. Both accuracy and F1-score were considered.
Result:
- Mean Validation Accuracy: 0.7638
- Mean Validation F1: 0.6692
Results are unsurprising:
- A tweet’s word count is not associated with its authenticity
- A tweet’s polarity is associated with its authenticity
- Word clouds verified that disaster tweets have a theme
- Naive Bayes classification performed better than LSTM
This is the type of problem that data mining excels at.