This repository explores adaptively finetuning large pre-trained transformers. The experiments are conducted on vision and language models -- VLBERT and LXMERT which are based on single-stream and two stream architectures respectively.
Transformers are deep neural networks built upon stacked multi-headed attention mechanisms. Transformers were first introduced in [1] for the tasks of machine translation. Since then, transformers have been widely used in pre-training of generic representations in NLP [2, 3], vision and language [4, 5, 6] and very recently in computer vision [7] as well. The rise of using transformer is attributed to the immense success these attention based networks have recieved for tasks in almost every modality. Another reason is the flexible architecture that can be used for almost any kind of input structures.
Architecture of a transformer encoder is depicted in the figure below.
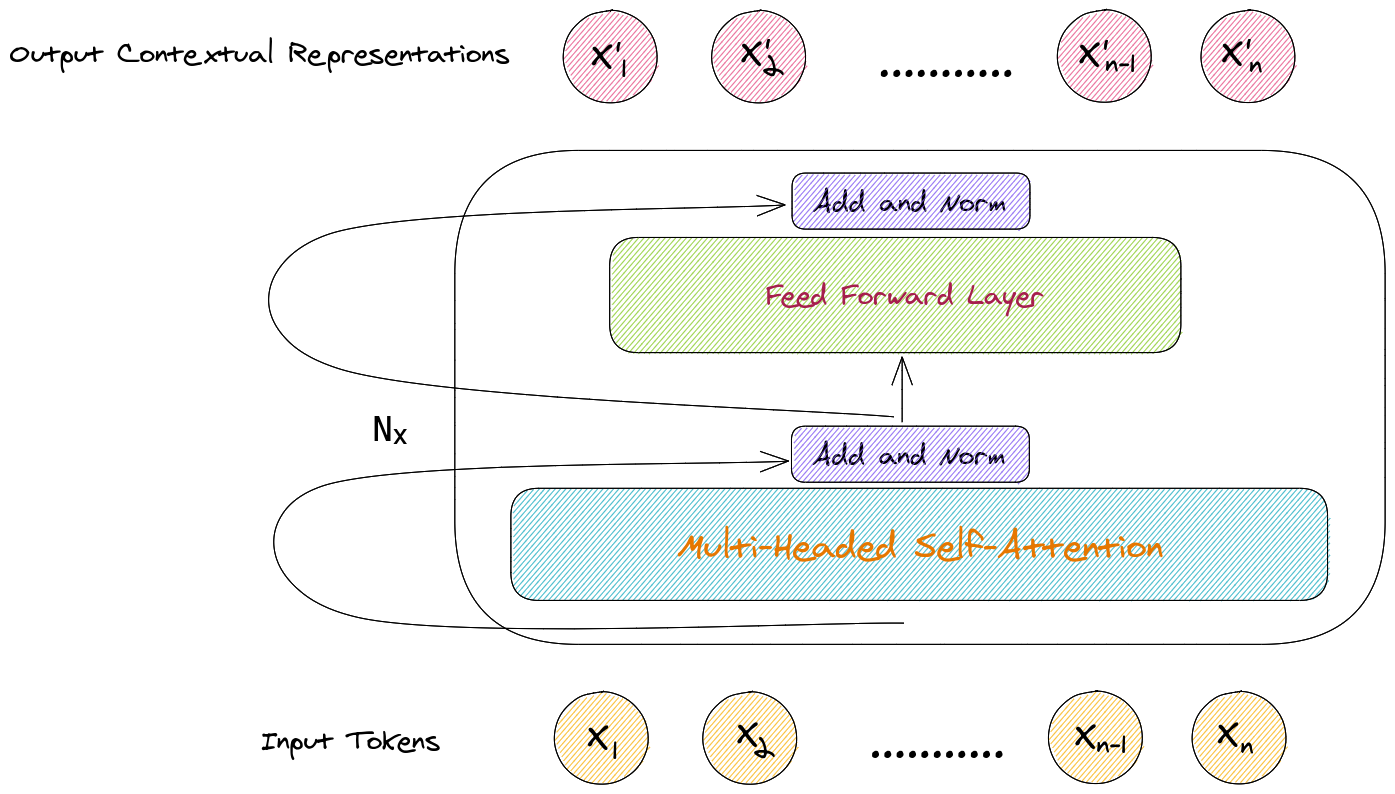
Finetuning is a widely used method for transfer learning which is a paradigm to transfer the knowledge gained by machine learning models from a task/dataset to another (usually smaller).
When finetuning a pre-trained model on a smaller dataset, the model is initialized by the pre-trained weights and the weights are updated by optimizing for accuracy on the smaller dataset.
The experiments presented in this repository choose the parts of the pre-trained model to finetune/drop based on each instance (input). It is "adaptive" in the sense that the architecture is different for each of the input samples. The decision to choose the parts is made on the basis of a policy network which is very small when compared to the original model.
Adaptive finetuning has been previously explored for residual networks [8, 9]. The policy network can be optimized in specific ways to improve the efficiency, accuracy, generalization of the models.
We explore several different adaptive finetuning strategies in this repository. One thing that is common to all the strategies is the use of a policy network to determine which parts of the model to finetune/drop based on the input images-text pair. The chosen policy network is relatively very small when compared to the original VLBERT/LXMERT network. The policy network is optimized using Gumbel Softmax which relieves the argmax constraints to softmax while backpropagation.
- SpotTune_Block: The encoder of transformer-like architectures is usually made of stacked multi-headed self-attention blocks. For example VLBERT-Base uses 12 such blocks each with 12 attention heads. While using the SpotTune_Block strategy, for each input sample (image-text pair), we make a decision for each of the block, whether to use the pre-trained weights or to finetune the weights. The process is depicted for an intermediate transformer block in the diagram below.
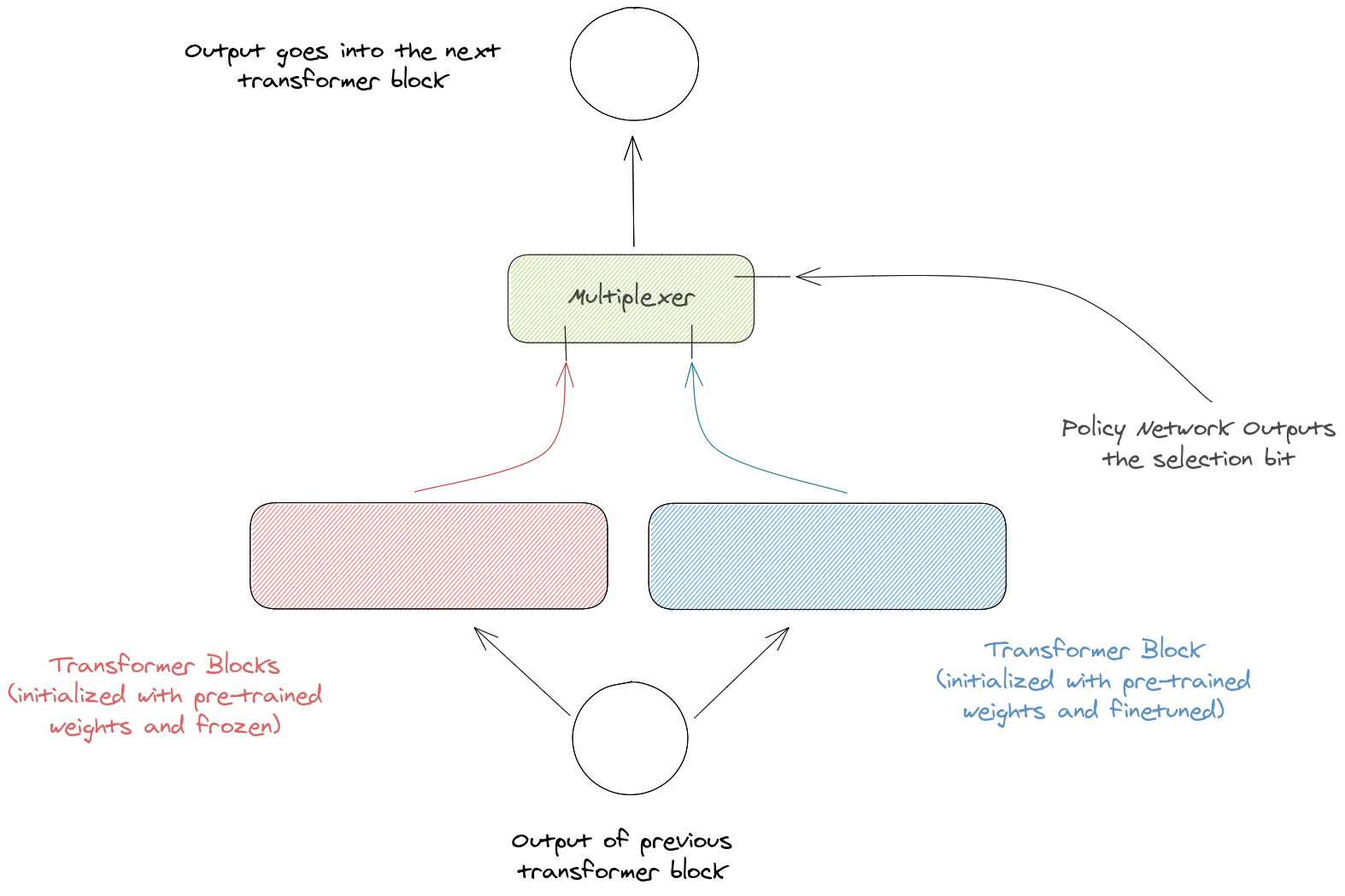
-
SpotTune: We take the architecture adaptation to next level. Each of the transformer block comprises of several components for example, a transformer block in VLBERT-Base has 12 attention heads and 3 feedforward layers i.e 15 components in total. We take a decision for each component, whether to use the pre-trained weights or to finetune the weights.
-
SpotTune_Res: Each transformer block has 2 skip connections. We take a decision for each part that lies between the skip connections.
-
Others: You can explore other strategies by checking out the wandb links of the projects given below.
The experiments presented are conducted on VLBERT and LXMERT. Detailed instructions to reproduce the experiments, comparisons and results are shown in the respective folders VLBERT and LXMERT. Additionally, I have provided the links for Wandb workspaces for experiments on both the architectures [VLBERT, LXMERT]. You can find the results, visualizations, training procedures, configs etc. in detail there.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. (2019). Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems (pp. 5753-5763).
- Lu, J., Batra, D., Parikh, D., & Lee, S. (2019). Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems (pp. 13-23).
- Su, W., Zhu, X., Cao, Y., Li, B., Lu, L., Wei, F., & Dai, J. (2019). Vl-bert: Pre-training of generic visual-linguistic representations. arXiv preprint arXiv:1908.08530.
- Tan, H., & Bansal, M. (2019). Lxmert: Learning cross-modality encoder representations from transformers. arXiv preprint arXiv:1908.07490.
- [Under Review] An image is worth 16x16 words: Transformers for Image Recognition at Scale
- Guo, Y., Shi, H., Kumar, A., Grauman, K., Rosing, T., & Feris, R. (2019). Spottune: transfer learning through adaptive fine-tuning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4805-4814).
- Wu, Z., Nagarajan, T., Kumar, A., Rennie, S., Davis, L. S., Grauman, K., & Feris, R. (2018). Blockdrop: Dynamic inference paths in residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 8817-8826).