it is just alternative. put the variables you want to know in parameters part.
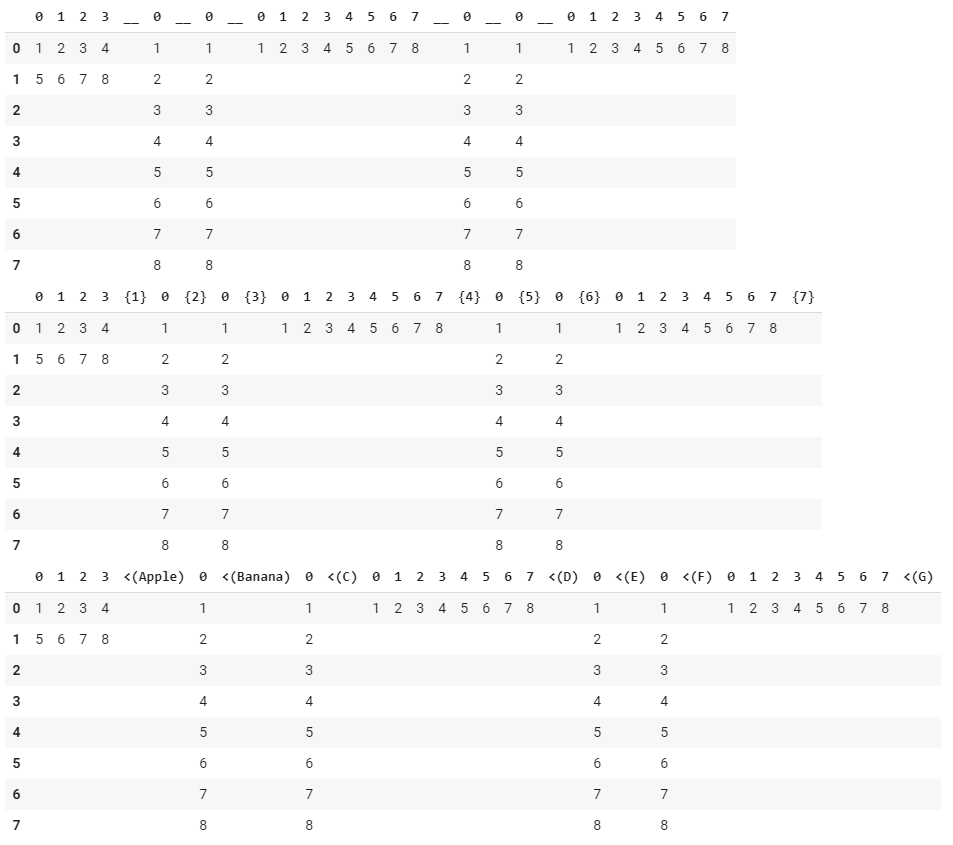
사용하는 입장에서 복사하기 편하게 모아놨습니다.
!git clone https://github.com/ironhopper/JEMIPYC.git
###<header>###
import sys
sys.path.append('JEMIPYC')
from array_check_function_global import df,dfn,dfv,dfx,dfnx,dfvx
def indi(*obj): # this returns parameter's variable name.
names = []
leng = len(obj)
for i in range(leng):
for name in globals():
if globals()[name] is obj[i]:
names.append(name)
return names
import numpy as np
###</header>###### example
# Apple = np.array([[1,2,3,4],[5,6,7,8]])
# Banana = [1,2,3,4,5,6,7,8]
# C = [[1],[2],[3],[4],[5],[6],[7],[8]]
# D = np.array([[1,2,3,4,5,6,7,8]])
# E = np.array([1,2,3,4,5,6,7,8])
# F = np.array([[1],[2],[3],[4],[5],[6],[7],[8]])
# G = [[1,2,3,4,5,6,7,8]]
# df(Apple,Banana,C,D,E,F,G)
# dfn(Apple,Banana,C,D,E,F,G)
# dfv(Apple,Banana,C,D,E,F,G,indi(Apple,Banana,C,D,E,F,G))
# dfx(Apple,Banana,C,D,E,F,G)
### ...collection of ml functions for machine learning study/ and useful custom algorithm included
0524 update
외부 함수 참조시에 dfv 변수명 인덱스가 제대로 표현되지 않는 오류 수정
0519 update
adding and editing,simplifying functions
_
only df:
pandas.reset_option('display.max_columns')
=> reset options
_
dfn : numbering, dfv : variable_naming
ex {1} {2} {3} ... / <(x) <(y) <(z) ...
=> just use it, and you know right then exactly.
_
dfx: extended
pandas.set_option('display.max_columns', None)
=> max row and col
- 사용하기전
깃 클론 먼저 하시고
(google colab 사용시엔 앞에 !(느낌표)를 붙일것)
before using the functions,
you have to git clone this project.
(if using google colab, attach the {!} sign)
!git clone https://github.com/ironhopper/JEMIPYC.git
- 사용시
아래 헤더파일을 복사하여 원하는 프로젝트에 붙여줍니다.
when using functions,
copy and paste below header codes.
###<header>###
import sys
sys.path.append('JEMIPYC')
from array_check_function_global import df,dfn,dfv,dfx,dfnx,dfvx
def indi(*obj): # this returns parameter's variable name.
names = []
leng = len(obj)
for i in range(leng):
for name in globals():
if globals()[name] is obj[i]:
names.append(name)
return names
import numpy as np
###</header>###df(A,B)
dfn(A,B)
dfv(A,B,indi(A,B))
이런식으로 사용합니다.
df -> 간단하게 볼때
dfn,dfv -> 칼럼을 숫자로 구분, 칼럼을 변수명으로 구분(써보면 바로 압니다. 파이썬코드에 아래 예제가 있으니 참고 바랍니다.)
이떄 dfv 의 경우 index 로 사용할 변수이름들을 직접 넣어줍니다. 복사붙여넣기를 하는것이 편합니다.
String 말고 변수명이어야합니다.
예) dfv(A,B,indi(A,B)) -> 이때 항상 마지막 순서로 넣어야 됨을 유의!
dfx -> extended table(전체 데이터 확인용) 입니다.
like above.
df is simple view,
dfx is extended view (full row and column.
variable inspector 대용으로 만들었습니다.
it is alternative of variable inspector
**(p.s.)..
- 기타 모든 변수의 타입 등의 현재 상태를 확인할땐
whos를 타이핑하고 실행합니다.
(ipynb 노트북을 사용할 경우) - 일반 array,list 도 사용가능하며 아래와 같이
you can use general array, list, and
Z = np.array([1,2,3])ndarray 도 사용 가능합니다.
ndarray also.
물론 iris data set 도 사용됩니다.
다른 자료구조들은 사용하신분들의 제보(?)를 부탁드립니다..
### example
# Apple = np.array([[1,2,3,4],[5,6,7,8]])
# Banana = [1,2,3,4,5,6,7,8]
# C = [[1],[2],[3],[4],[5],[6],[7],[8]]
# D = np.array([[1,2,3,4,5,6,7,8]])
# E = np.array([1,2,3,4,5,6,7,8])
# F = np.array([[1],[2],[3],[4],[5],[6],[7],[8]])
# G = [[1,2,3,4,5,6,7,8]]
# df(Apple,Banana,C,D,E,F,G)
# dfn(Apple,Banana,C,D,E,F,G)
# dfv(Apple,Banana,C,D,E,F,G,indi(Apple,Banana,C,D,E,F,G))
# dfx(Apple,Banana,C,D,E,F,G)
### ...