Structured prediction or structured (output) learning is an umbrella term for supervised machine learning techniques that involves predicting structured objects, rather than scalar discrete or real values.
Similar to commonly used supervised learning techniques, structured prediction models are typically trained by means of observed data in which the true prediction value is used to adjust model parameters. Due to the complexity of the model and the interrelations of predicted variables the process of prediction using a trained model and of training itself is often computationally infeasible and approximate inference and learning methods are used.
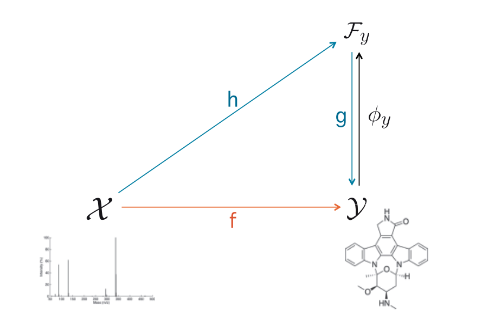
A powerful and flexible approach to structured prediction consists in embedding the structured objects to be predicted into a feature space of possibly infinite dimension by means of output kernels, and then, solving a regression problem in this output space. A prediction in the original space is computed by solving a pre-image problem. In such an approach, the embedding, linked to the target loss, is defined prior to the learning phase. In this work, we propose to jointly learn a finite approximation of the output embedding and the regression function into the new feature space. For that purpose, we leverage a priori information on the outputs and also unexploited unsupervised output data, which are both often available in structured prediction problems. We prove that the resulting structured predictor is a consistent estimator, and derive an excess risk bound. Moreover, the novel structured prediction tool enjoys a significantly smaller computational complexity than former output kernel methods. The approach empirically tested on various structured prediction problems reveals to be versatile and able to handle large datasets.
In this Package you can use 3 differents types of models for structured predictions:
- Input Output Kernel Predictions - IOKR
- Decision Tree Output Kernel - OK3
- Deep Neural Network Output Kernel Predictions -DIOKR
The library has been tested on Linux, MacOSX and Windows. It requires a C++ compiler for building/installing the EMD solver and relies on the following Python modules:
- Pandas (>=1.2)
- Numpy (>=1.16)
- Scipy (>=1.0)
- Scikit-learn (>=1.0)
You can install the toolbox through PyPI with:
pip install -i https://test.pypi.org/pypi/ --extra-index-url https://pypi.org/simple structured-predictions==0.0.8 --no-cache-dirAfter a correct installation, you should be able to import the module without errors:
import stpredictionsThis open source Python library provide several methods for Output Kernelization.
Website and documentation: https://IOKR.github.io/
Source Code (MIT): https://github.com/IOKR/IOKR
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from stpredictions.models.IOKR.model import IOKR
from stpredictions.datasets import load_bibtex
X, Y, _, _ = load_bibtex()
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
clf = IOKR()
clf.verbose = 1
L = 1e-5
clf.fit(X=X_train, Y=Y_train, L=L)
Y_pred_test = clf.predict(X_test=X_test, Y_candidates=Y_test)
f1_test = f1_score(Y_pred_test, Y_test, average='samples')
print( "Test f1 score:", f1_test)from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from stpredictions.models.IOKR.model import IOKR
from stpredictions.datasets import load_corel5k
X, Y, _, _ = load_corel5k()
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
clf = IOKR()
clf.verbose = 1
L = 1e-5
clf.fit(X=X_train, Y=Y_train, L=L)
Y_pred_test = clf.predict(X_test=X_test, Y_candidates=Y_test)
f1_test = f1_score(Y_pred_test, Y_test, average='samples')
print( "Test f1 score:", f1_test)from sklearn import datasets
from stpredictions.models.OK3._classes import OK3Regressor, ExtraOK3Regressor
from stpredictions.models.OK3.kernel import *
#%% Generate a dataset with outputs being long vectors of 0 and 1
n_samples=4000
n_features=100
n_classes=1000
n_labels=2
# Fit on a half,
# Testing on a quarter,
# Last quarter used as possible outputs' ensemble
# It is a big dataset for the algorithm, so it is kind of slow,
# Using parameters regulating the tree's growth will help:
# --> max_depth, max_features
X, y = datasets.make_multilabel_classification(n_samples=n_samples,
n_features=n_features,
n_classes=n_classes,
n_labels=n_labels)
# First half is the training set
X_train = X[:n_samples//2]
y_train = y[:n_samples//2]
# Third quarter is the test set
X_test = X[n_samples//2 : 3*n_samples//4]
y_test = y[n_samples//2 : 3*n_samples//4]
# The last quarter of outputs is used to have candidates for the tree's decoding
# Predictions will be in this ensemble
y_candidates = y[3*n_samples//4:]
#%% Fitting one (two) tree(s) to the data
# A kernel must be chosen to be used on output datas in vectorial format above
# For now the list of usable kernels is :
kernel_names = ["linear", "mean_dirac", "gaussian", "laplacian"]
# Gaussian and exponential kernels have a parameter gamma to the the width of the kernel
# Let's choose a kernel
# We can indifferently input the name (and its potential parameters) :
kernel1 = ("gaussian", .1) # ou bien kernel1 = "linear"
# Or
kernel2 = Mean_Dirac_Kernel()
# Then we can create our estimator, that will work calculating gaussian kernels between outputs :
ok3 = OK3Regressor(max_depth=6, max_features='sqrt', kernel=kernel1)
# It is also while creating the estimator that we can fulfill
# the maximum depth, the impurity's minimal reduction on each split,
# The minimal number of samples in each leaf, etc as in classical trees
# We can now fit the estimator to our training data :
ok3.fit(X_train, y_train)
# We could also input a "sample_weight" parameter : a weight vector, positive or null on the training examples:
# A weight "0" in an example means that the example will not be taken into accountun
print("check")
# ALTERNATIVE : we can also fulfill only the computation mode of the kernels during the 'fit'
# allowing us to change the kernel with the same estimator
# ex:
extraok3 = ExtraOK3Regressor(max_depth=6, max_features='sqrt')
extraok3.fit(X_train, y_train, kernel=kernel2) # the estimator will keep in memory this new kernel
#%% (OPTIONAL) Before decoding the tree
# We can :
# get the tree's depth
depth = ok3.get_depth()
# get the number of leaves
n_leaves = ok3.get_n_leaves()
# get the predictions of each leaf with weight vectors on training outputs
leaves_preds_as_weights = ok3.get_leaves_weights()
# get the leaves with new data
X_test_leaves = ok3.apply(X_test)
# get the predictions for new data with weights
test_weights = ok3.predict_weights(X_test)
# Compute the R2 score of our predictions in Hilbert's Space in which are set the outputs
r2_score = ok3.r2_score_in_Hilbert(X_test, y_test) # We can specify a vector sample_weight
#%% Deconding the tree(s) for outputs' prediction
# For decoding, we can propose an ensemble of candidates' outputs,
# or we can "None" it. In this case the candidates' outputs are the training example's outputs
candidates_sets = [None, y_candidates]
# We can try with candidates=y_candidates or with nothing (ou None)
# We can either decode the tree considering an ensemble of candidates' outputs
leaves_preds = ok3.decode_tree(candidates=y_candidates)
# Then be able to predict quickly the outputs
y_pred_1 = ok3.predict(X_test[::2])
y_pred_2 = ok3.predict(X_test[1::2])
print("check")
# Or we can decode for a serie of inputs, by fulfilling the candidates
y_pred_extra_1 = extraok3.predict(X_test[::2], candidates=y_candidates)
y_pred_extra_2 = extraok3.predict(X_test[1::2]) # Remember the predictions from each leaf
#%% Performance's evaluation
# We can calculate the R2 score in the Hilbert's Space as said before (no need for decoding):
r2_score = extraok3.r2_score_in_Hilbert(X_test, y_test) # We can specify a 'sample_weight' vector
# We can compute scores on the real decoded datas :
hamming_score = ok3.score(X_test, y_test, metric="hamming") # We can specify a 'sample_weight' vector
# Note : It is not necessary to fulfill again a candidates' ensemble since OK3 already got one
# One of the KPI available for this score function is the 'top k accuracy'.
# To get it we need to fulfill the candidates' ensemble in the function on each call:
top_3_score = ok3.score(X_test, y_test, candidates=y_candidates, metric="top_3")
# We can fulfill any int rather than the "3" above :
top_11_score = ok3.score(X_test, y_test, candidates=y_candidates, metric="top_11")
print( "top_3_score:", top_3_score)
print( "top_11_score:", top_11_score)
###########################################################
# # # # # How to use OK3's forests # # # # #
############################################################
from stpredictions.models.OK3._classes import RandomOKForestRegressor, ExtraOKTreesRegressor
from stpredictions.models.OK3.kernel import *
from sklearn import datasets
#%% Generate a dataset with outputs being big vectors of 0 and 1
n_samples=1000
n_features=100
n_classes=1000
n_labels=2
# Fit on a half,
# Testing on a quarter,
# Last quarter used as possible outputs' ensemble
# It is a big dataset for the algorithm, so it is kind of slow,
# Using parameters regulating the tree's growth will help:
# --> max_depth, max_features s
X, y = datasets.make_multilabel_classification(n_samples=n_samples,
n_features=n_features,
n_classes=n_classes,
n_labels=n_labels)
# First half is the training set
X_train = X[:n_samples//2]
y_train = y[:n_samples//2]
# Third quarter is the test set
X_test = X[n_samples//2 : 3*n_samples//4]
y_test = y[n_samples//2 : 3*n_samples//4]
# The last quarter of outputs is used to have candidates for the tree's decoding
# Predictions will be in this ensemble
y_candidates = y[3*n_samples//4:]
#%% Fit a forest to the data
# A kernel must be chosen to be used on output datas in vectorial format above
# For now the list of usable kernels is :
kernel_names = ["linear", "mean_dirac", "gaussian", "laplacian"]
# Gaussian and exponential kernels have a parameter gamma to the the width of the kernel
# Let's choose a kernel
# We can indifferently input the name (and its potential parameters) :
kernel1 = ("gaussian", .1) # ou bien kernel1 = "linear"
# Then we can create our estimator, that will work calculating gaussian kernels between outputs :
okforest = RandomOKForestRegressor(n_estimators=20, max_depth=6, max_features='sqrt', kernel=kernel1)
# It is also while creating the estimator that we can fulfill
# the maximum depth, the impurity's minimal reduction on each split,
# The minimal number of samples in each leaf, etc as in classical trees
# We can now fit the estimator to our training data :
okforest.fit(X_train, y_train)
# We could also input a "sample_weight" parameter : a weight vector, positive or null on the training examples:
# A weight "0" in an example means that the example will not be taken into account
#%% (OPTIONAL) Before decoding the tree
# We can get the R2 score of our predictions in the Hilbert space in which are set the outputs
r2_score = okforest.r2_score_in_Hilbert(X_test, y_test) # We can specify a vector sample_weight
#%% Outputs' prediction
# For decoding, we can propose an ensemble of candidates' outputs,
# or we can "None" it. In this case the candidates' outputs are the training example's outputs
candidates_sets = [None, y_candidates]
# We can try with candidates=y_candidates or with nothing (ou None)
# Or we can decode for a serie of inputs, by fulfilling the candidates
y_pred_1 = okforest.predict(X_test[::2], candidates=y_candidates)
y_pred_2 = okforest.predict(X_test[1::2]) # Remember the predictions from each leaf
#%% Performance's evaluation
# We can calculate the R2 score in the Hilbert's Space as said before (no need for decoding):
r2_score = okforest.r2_score_in_Hilbert(X_test, y_test) # on peut y spécifier un vecteur sample_weight
# We can compute scores on the real decoded datas :
hamming_score = okforest.score(X_test, y_test, metric="hamming") # on peut y spécifier un vecteur sample_weight
# Note : It is not necessary to fulfill again a candidates' ensemble since OK3 already got one
# One of the KPI available for this score function is the 'top k accuracy'.
# To get it we need to fulfill the candidates' ensemble in the function on each call:
top_3_score = okforest.score(X_test, y_test, candidates=y_candidates, metric="top_3")
# We can fulfill any int rather than the "3" above :
top_11_score = okforest.score(X_test, y_test, candidates=y_candidates, metric="top_11")
#%% Miscellaneous things to know
##### About 'candidates' #####
# When the candidates ensembles are required, they are not provided,
# So the research is done with the training dataset's outputs' ensemble,
# memorized by the tree (faster).
# The candidates can be informed in the functions 'decode_tree', 'predict',
# 'decode' (which is equal to 'predict), and in 'score'.
# Once that an ensemble of candidates is fulfilled in one of this functions, the ensemble of
# possible predictions on leafs is memorized by the estimator (but not the ensemble of candidates
# itself because too big) , that's why
# it is not mandatory and even unwishable compute-wise to inform several times
# the same ensemble of candidates. The first time is enough.
# On the other hand when we compute a top k accuracy score then it is mandatory
# to inform an ensemble of candidates because the decoding is different
# if we need to return several predictions for each leaf.The contributors to this library are
- Tamim El Ahmad (Phd)
- Luc Motte (Phd)
- Florence d'Alché-Buc (Director)
- Awais Sani (Sr. ML Engineer)
- Gaëtan Brison (Lead ML Engineer)
Every contribution is welcome and should respect the contribution guidelines. Each member of the project is expected to follow the code of conduct.
You can ask questions and join the development discussion:
- On the structured-predictions slack channel
- On the structured-predictions gitter channel
- On the structured-predictions mailing list
You can also post bug reports and feature requests in Github issues. Make sure to read our guidelines first.
[1] Brouard, C., d'Alché-Buc, F., Szafranski, M. (2013, November). Semi-supervised Penalized Output Kernel Regression for Link Prediction. 28th International Conference on Machine Learning (ICML 2011), pp.593–600.
[2] Brouard, C., Szafranski, M., d'Alché-Buc, F. (2016). Input Output Kernel Regression: Supervised and Semi-Supervised Structured Output Prediction with Operator-Valued Kernels. Journal of Machine Learning Research, Microtome Publishing.
[3] Brouard, C., Shen, H., Dührkop, K., d'Alché-Buc, F., Böcker, S., & Rousu, J. (2016) Fast metabolite identification with input output kernel regression. Bioinformatics, Oxford University Press (OUP)