This repository provides the Pytorch implementation of Hindsight Experience Replay on Deep Q Network and Deep Deterministic Policy Gradient algorithms.
Link to the paper: https://arxiv.org/pdf/1707.01495.pdf
Authors: Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, Wojciech Zaremba
-
You can train the model simply by running the main.py files.
DQN With HER -> HERmain.py
DDPG With HER -> DDPG_HER_main.py
DQN Without HER -> main.py
-
You can set the hyper-parameters such as learning_rate, discount factor (gamma), epsilon, and others while initializing the agent variable in the above-mentioned files
- Just run the files mentioned in the Training section with making the load_checkpoint variable to True which will load the saved parameters of the model and output the results. Just update the paths as per the saved results path.
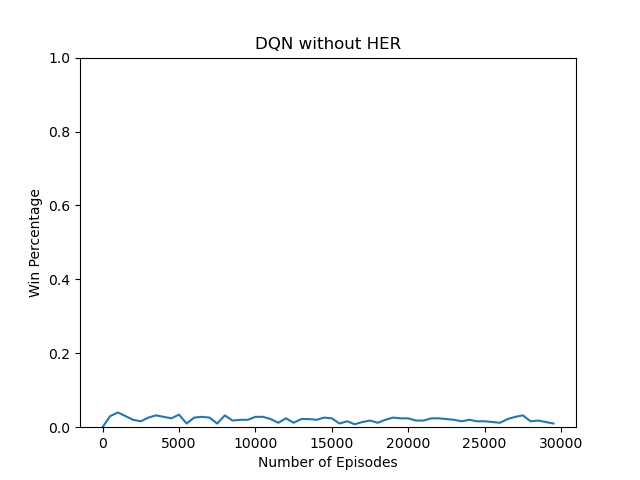 |
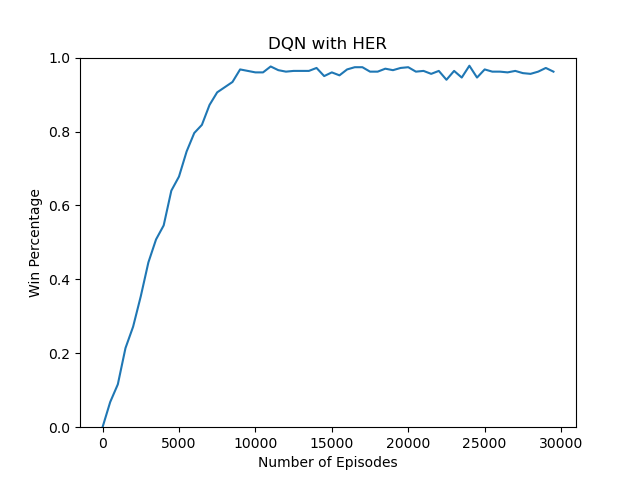 |
|
With average
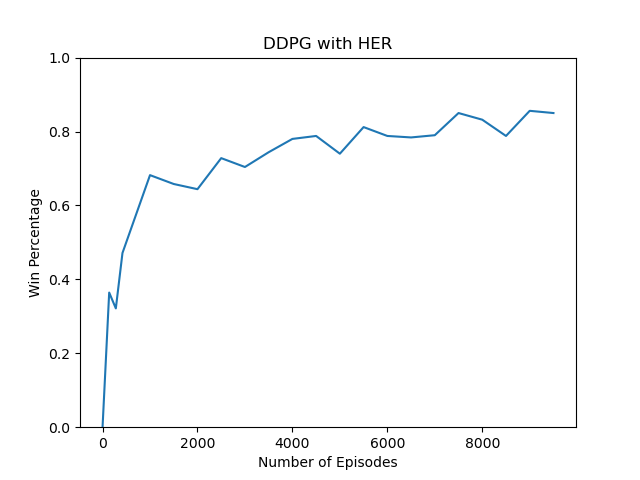
|
Without average (contains spikes)
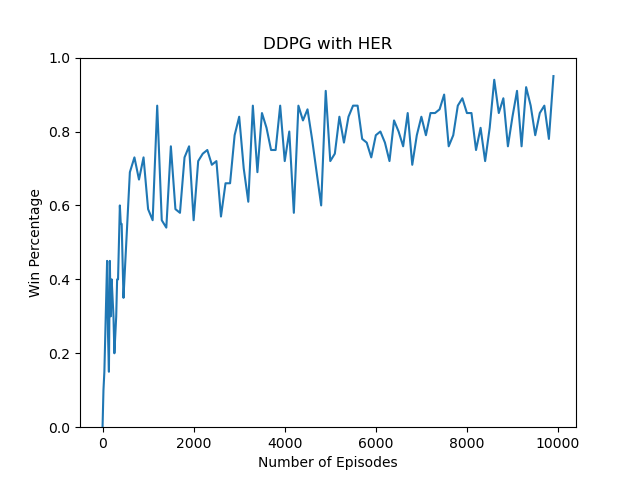
|