A collaborative data science project headed by the Massive Data Institute's Jaren Haber and UC Berkeley professor Heather Haveman.
Table of Contents
Literature reviews are a vital part of research in many academic fields, and serve to help determine what we know and don’t know. For interdisciplinary studies, literature reviews are especially challenging because the numerous publications and publication outlets are growing exponentially—critically, growing to a volume that a single person cannot easily manage. Our solution is to explore the capabilities of modern machine learning techniques to review the literature automatically at a large scale.
This code uses raw JSTOR OCR raw text, and creates predictive models based on hand-coded training data (per perspective) built on pretrained transformer models. We will then use these models to predict labels for papers at a large scale, and visualize overall trends across different perspectives over time.
- Scripts to train a Longformer Model on Azure:
- Notebooks to interactively train a BERT Model:
- Notebook to label all 65k unlabeled articles using a Longformer model:
- Text preprocessing code (updated to retain stopwords for transformers):
- Notebooks to build, evaluate, and optimize models with
scikit-learn: - Notebook to build and evaluate CNN and MLP models with
keras: - Notebook to build and evaluate models with
scikit-learnand word embeddings: - Notebook to build and evaluate CNN and MLP models with
kerasand word embeddings:
- Notebook to select and compile sample of articles across classes using model predictions:
- Scripts with functions to assist in reading text files and text preprocessing:
- Notebook to load and merge datasets to assemble datasets for each perspective:
- Notebook creating a csv of our file names:
- CSV Logs of model hyperparameter and results for each perspective using the average word embedding as feature vector:
The data is obtained from approximately 70,000 JSTOR academic articles focusing on (1) sociology and (2) management and organizational behavior. Articles that are not full, in English-language, or book reviews are excluded. Our models are then trained and evaluated on hundreds of hand-labeled articles for each sociological perspective.
We preprocessed the text minimally. Because BERT utilizes structures of the sentence, stop words and grammatical structures become important as BERT assigns meaning to words based on their surrounding words in a process called self-attention. Thus, as part of the preprocessing step, we removed HTML and LaTeX tags in the JSTOR articles.
The script that processing the JSTOR files and saves the preprocessed files is in preprocess/preprocess_article_text_full.py.
Our current training script uses the Longformer as implemented by the Hugging Face library. For a given sociological perspective, our model conducts cross-validation training and evaluation on the perspective's dataset of labeled papers. An interactive example of this code for BERT is found in modeling/BERT-cross-validate.ipynb.
To train our models, we took advantage of our student Microsoft Azure computation credits. We used the platform’s machine learning servers to search the space of hyperparameters for our model to maximize cross-validation accuracy, utilizing their powerful cloud GPUs and well-used hyperparameter search framework. The files used to run these experiments are found in modeling/Azure Files/.
We have about 700 training data for each perspective, and have about twice as much negative data as positive data. To address the issue of class imbalance in our data, we used oversampling. To oversample, we bootstrap from the minority class (label 1) so that the ratio of majority and minority class is 1:1. We then perform the same procedure on the test data.
We first ran the models over ~65K unlabeled JSTOR articles from 1970 to 2016 to obtain the predicted probability that each article is of the 4 perspectives. Then to start our analysis, we divided the articles into 2 primary subjects: Sociology and Management & Organizational Behavior, each having 3 perspectives (demographic, cultural, and relational). Sociology articles are filtered to be organizational sociology, where the predicted organizational score is greater than a threshold of 0.7.
To analyze trends in various perspectives, we calculated the proportion of articles belonging to a certain perspective and primary subject and obtained the line graph above. The year 1970 and 2016 are outliers because both only contain less than 15 articles, resulting in the sharp fluctuations in some perspectives in 1970 and 2016.
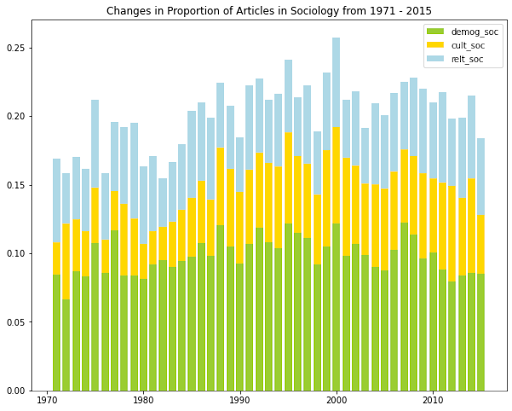

Overall, we see that demographic perspective is the most common in sociology articles, while relational perspective is the most common in management & OB articles. Demographic management articles seems to be in gradual decline starting in 2010, and cultural management articles seems to be in gradual growth starting in 1970. All other categories seem to have fluctuations over the years but exhibit no general growth nor decline from 1970 to 2016.