Machine learning and Computer Vision to read beer
Where I live, me and my friends mark the beer we drink on a paper like this, hanging on the wall.
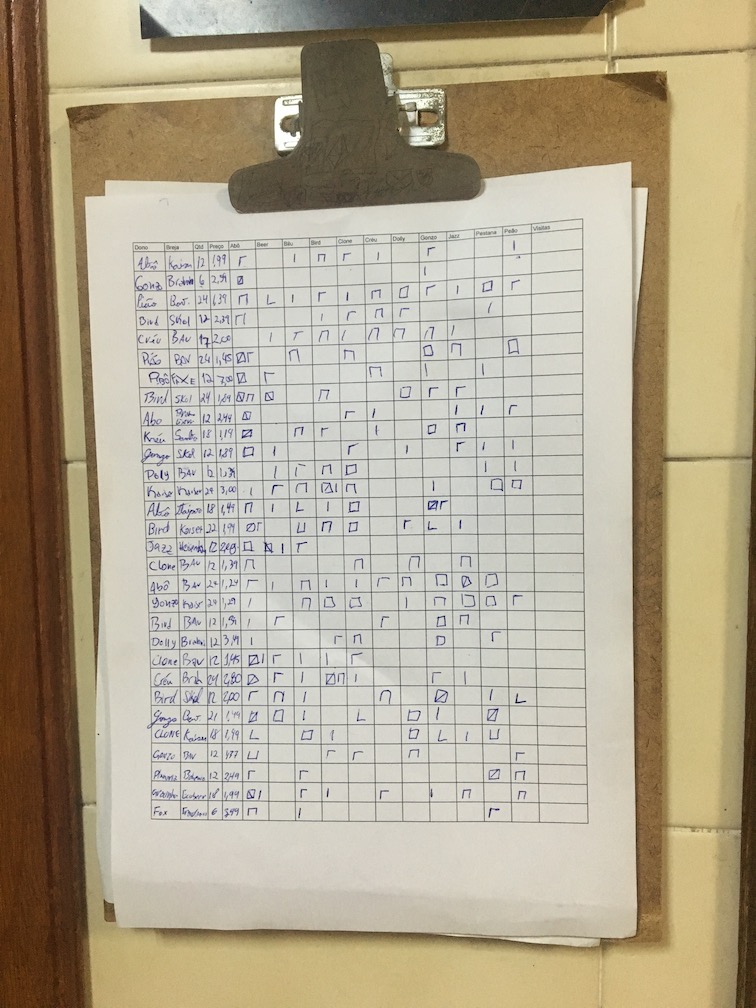
Once a month we type this paper on a spreadsheet and run a script on it to tell how much each person has to pay. This process takes 30 minutes approximately.
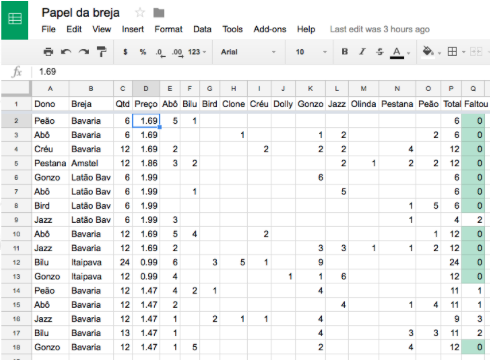
In an attempt to solve this wasted time I developed a script that reads the image of the paper and builds the spreadsheet by itself.
The only action required by the user is to take a picture of the paper.
The script, using OpenCV, separates each cell using a Hough transformation
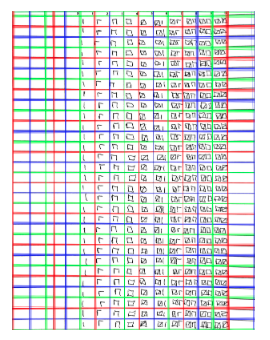
After that, runs a MLP, written in Python with numpy, on each cell

To build the dataset required to train the mlp, I needed a large amount of cells filled with known data. So I asked my friends to fill up some sheets.
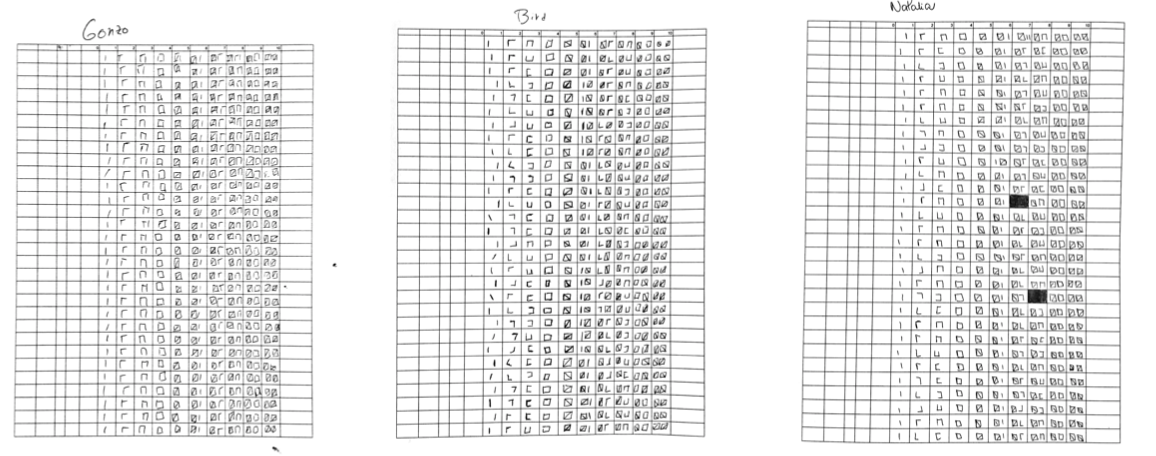
And together, we managed to draw 33,000 sticks

The algorithm gets 90% accuracy. Since this software deals with money, 90% accuracy is not enough, but the mistakes are very likely to be noticed before any payment is made. Once the spreadsheet knows how much beer has been bought, it knows how much has to be marked on the paper, and if the numbers don't match, probably we have an error.