Pipeline for Asynchronous Task Scheduling in Python via Flask-RESTPlus (API) + Redis + Celery + MongoDB
Together with advancements in computing capacity and increasing trends in working on large-scale datasets, in some projects, we might need to execute time-consuming and/or heavy functions upon the plenty of requests coming from the client side.
So, we shall run them in the background while still getting new requests from the client and finally, we should get back the result later once the process is done.
Hence, here, asynchronous (async) task scheduling via microservices provides a good offer to handle our issue!
Microservices
During designing a software pipeline, Microservices Architecture, where the applications, modules/functions work independently, has shown up for the last decade.

Image source: https://dev.to/alex_barashkov/microservices-vs-monolith-architecture-4l1m.
In a microservices architecture, in contrast to monolithic architecture, the functional parts of your whole work are split into smaller units. Those smaller units are dedicated to working on specific tasks and they do their job well!
While working they do not know what the others perform however they have a common port/way of communication where they are able to talk to each other.
For more about the microservices, you might check this blog post: https://medium.com/sciant/microservices-for-dummies-e55e428a5eef.
Here is one real-world examples of microservice architecture:
In this F1 pit spot, the fastest one which only takes few seconds, every single person works in a single task and does the best for that task!

Asynchronous (async) Programming
Let's get started with the synchronous one. In this case, the tasks, or the jobs are performed once at a time. So, to be able to work on the 2nd (following) task, first of all, the 1st (previous) task has to be completed. So, you have to wait for a task to complete to go for the next one.
By contrast, in async programming, the pipeline can go with any process without waiting for the completion of the previous task if they are independent of each other. Hence, you might catch several requests at a time simultaneously.
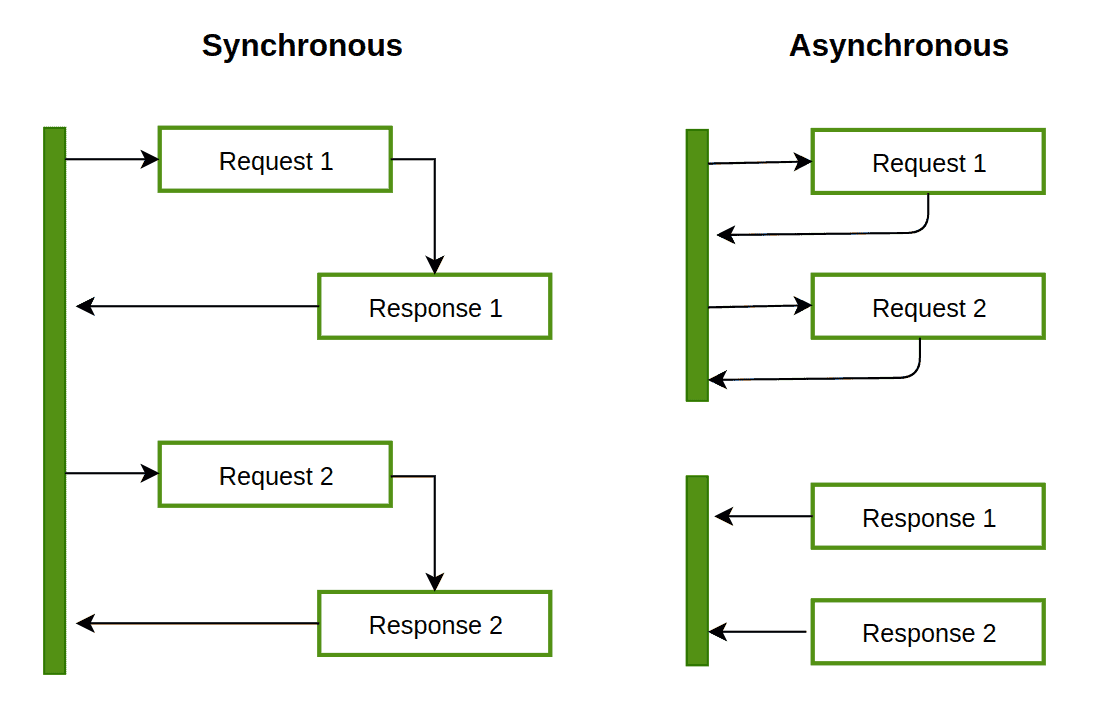
Image resource: https://www.baeldung.com/cs/async-vs-multi-threading.
Maybe you might be asking why we need this or what are the real-life examples? So, currently, several processes are going through in async way even we do not realize.
Here are some real-life examples:
If you have more (and/or clearer) examples, please just reach out to me.
Use case #1 | Ordering a burger | Literally real-life 😊
Assume that you are starving and looking forward to eating a burger!
In this scenario, every customer is getting reference number after their ordering. While the order is on its own way, the customers can just relax and control the dashboard for the status of their orders while the crew are working on other orders.

Please, check this awesome blog post here to see the rest and to get the issue in the easiest way! (Even worthy to look at the cartoons!)
Use case #2 | Basic example
Think that we as a team or company are providing a form in our web page to our users or customers and they can fill the form. Supposing that we need a sort of computation which takes a lot of time once the form is filled.

Now, in this scenario, our user will fill and submit the form, we will return that "OK, we got your request and will let you know". Meanwhile, we will perform needed calculation in background and once it's done, we will send an email containing the result of calculation to our user. Yey!
For this real-life example, you can find another repository and blog with its implementation here.
Use case #3 | Bioinformatics/Computational Biology
Almost same protocol also applies here. Consider that our user is willing to predict the 3D structure of a protein with given sequence or post long-time genome alignment work.
So, while you might get other request from same person and/or other users, the tasks will undergo the pipeline in the background and will turn back once they are done, if possible 😊.
Here is the schematic view of my pipeline:

Technologies used:
| Name | Description | Link |
|---|---|---|
| Flask | Python micro web-framework | https://flask.palletsprojects.com/en/1.1.x/ |
| Flask-RESTPlus | Extension for Flask that adds support for quickly building REST APIs | https://flask-restplus.readthedocs.io/en/stable/ |
| Celery | Asynchronous task queue or job queue package for Python | https://docs.celeryproject.org/en/stable/ |
| Flower | Tool for monitoring and administrating Celery clusters | https://flower.readthedocs.io/en/latest/ |
| Redis | In-memory data structure store, a distributed, key–value database | https://redis.io/ |
| MongoDB | Document-oriented NoSQL database program | https://www.mongodb.com/python |
If you wonder the comparison of several
brokers, please visit this https://docs.celeryproject.org/en/stable/getting-started/brokers/index.html page by Celery offical docs.
For use of Flask-RESTPlus extension (using Swagger UI), you might visit my previous repo and post: https://github.com/furkanmtorun/Flask-RESTPlusAPI.
Reminder: Do not forget to change
MONGO_CLIENT_URLfor your setup. For MongoDB, you might give a try to use MongoDB Atlas.
Here is classic way of installation and running.
Docker-compose file might come later!
Installation
-
Install Redis:
- Visit offical document here: https://redis.io/topics/quickstart.
- If you are using Win10, you might check here: https://dev.to/divshekhar/how-to-install-redis-on-windows-10-3e99.
-
To install the required packages:
pip install -r requirements.txt
Running
-
Start redis:
redis-server --port 6380 --slaveof 127.0.0.1 6379 -
Execute
Celery,Flowerand ourflask_apifile inside the project folder:-
celery worker -A flask_api.celery_client -EIf you are using Win10 and face some problems with Celery, try the following instead:
celery worker -A flask_api.celery_client -E --pool=solo -l info -
flower -A flask_api.celery_clientThen, you can visit http://localhost:5555/
-
python flask_api.pyNow, time to open our REST-Api on http://localhost:5000/
-
In our simple pipeline, we provide a REST API for our users where they can calculate the body-mass index (BMI) of a person. So, they can list all of the calculations or post a new one under the end point namely calculationsEP Operations for Calculations while they can get the details of a calculation using unique process ID pid or delete it via pid.

Our Flask RESTPlus API page overview
Here, in our case, bmi_calculation() function mimics a time-consuming process. Once the user submits a new entry with name, weight and height, it automatically add this request to query via message broker or queue system Redis and it forwards them to Celery workers to be processed and it returns a unique pid. Once the result is ready, it is saved into MongoDB Atlas database to operate CRUD operations on the API (getting the list of calculations, deleting, etc.).
✨ If you wonder about the details, all is explained with screenshots! 👇
 Flower UI (no task provided yet)
Flower UI (no task provided yet)
 Documents (Entries) of MongoDB Atlas Collection
Documents (Entries) of MongoDB Atlas Collection
 New calculation post in our REST-API
New calculation post in our REST-API
 PID for our calculation returned upon the post
PID for our calculation returned upon the post
 Several new calculations are posted and see how their status in Celery look like on Flower
Several new calculations are posted and see how their status in Celery look like on Flower
 Once several new posts are submitted, see the queue in Redis on Flower
Once several new posts are submitted, see the queue in Redis on Flower
 The states of all Tasks in Celery on Flower UI
The states of all Tasks in Celery on Flower UI

Results of new calculations posted are shown in MongoDB Atlas
So, now, our users can fetch easily the calculated BMI values (in the background) by using the given pid later time.
That's all for now!
- Miranda, L. (2019). Distill: Why do we need Flask, Celery, and Redis? (with McDonalds in Between). Retrieved 2 May 2021, from https://ljvmiranda921.github.io/notebook/2019/11/08/flask-redis-celery-mcdo/
- Smyth, P. (2018). Creating Web APIs with Python and Flask . Programming Historian. Retrieved from https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask
- Rocha, B. (2021). Microservices with Python, RabbitMQ and Nameko. Retrieved 2 May 2021, from http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.html
- Herman, M. (2021). Asynchronous Tasks with Flask and Celery. Retrieved 2 May 2021, from https://testdriven.io/blog/flask-and-celery/
- Costa, R. (2021). Asynchronous vs. Synchronous Programming: When to Use What. Retrieved 2 May 2021, from https://www.outsystems.com/blog/posts/asynchronous-vs-synchronous-programming/
- Vassilev, K. (2019). Microservices for Dummies. Retrieved 2 May 2021, from https://medium.com/sciant/microservices-for-dummies-e55e428a5eef
See other similar works:
- Herman, M. (2021). Asynchronous Tasks with Flask and Redis Queue. (2021). Retrieved 2 May 2021, from https://testdriven.io/blog/asynchronous-tasks-with-flask-and-redis-queue/
- Python Celery & RabbitMQ Tutorial (Demo, Source Code). (2016). Retrieved 2 May 2021, from https://tests4geeks.com/blog/python-celery-rabbitmq-tutorial/
- Gori, R. (2020). Asynchronous Tasks Using Flask, Redis and Celery. (2021). Retrieved 2 May 2021, from https://stackabuse.com/asynchronous-tasks-using-flask-redis-and-celery/
- Bhavani's Portfolio. (2021). Retrieved 2 May 2021, from https://bhavaniravi.com/blog/asynchronous-task-execution-in-python/
- Januzaj, V. (2021). Asynchronous tasks in Python with Celery + RabbitMQ + Redis. Retrieved 2 May 2021, from https://levelup.gitconnected.com/asynchronous-tasks-in-python-with-celery-rabbitmq-redis-480f6e506d76
- Bruijn, L. (2021). Distributed Task Queues With Django, RabbitMQ, and Celery. Retrieved 3 May 2021, from https://betterprogramming.pub/distributed-task-queues-with-celery-rabbitmq-django-703c7857fc17
- Elaborate the README file/post
- Prepare a
docker-compose.ymlfile for containerization - Enable re-trying the failed celery tasks
- Write tests via
pytest& integrate Github Actions for CI/CD
About the author & developer:
- Furkan M. Torun
- Mail: furkanmtorun@gmail.com
- Academia: Google Scholar Profile
- Website: furkanmtorun.github.io
Moreover, please do not hesitate to comment via opening an issue via GitHub if you have any suggestions or feedback!